You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Soil Type Classification From High Resolution Satellite Images With Deep CNNDocument4 pagesSoil Type Classification From High Resolution Satellite Images With Deep CNNMayank Pujara100% (1)
- An Analytical Approach For Soil and Land Classification System Using Image ProcessingDocument5 pagesAn Analytical Approach For Soil and Land Classification System Using Image ProcessingMayank PujaraNo ratings yet
- Classification of Soil Types From GPR B Scans Using Deep Learning TechniquesDocument5 pagesClassification of Soil Types From GPR B Scans Using Deep Learning TechniquesMayank PujaraNo ratings yet
- Classification of Soil Fertility Using Machine Learning-Based ClassifierDocument6 pagesClassification of Soil Fertility Using Machine Learning-Based ClassifierMayank PujaraNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Volvo - A40F-A40G - Parts CatalogDocument1,586 pagesVolvo - A40F-A40G - Parts Catalog7crwhczghzNo ratings yet
- 2018 January Proficiency Session 2 A VersionDocument2 pages2018 January Proficiency Session 2 A VersionUğur GiderNo ratings yet
- A Survey of Control Approaches For Unmanned Underwater Vehicles 19.8.2023 - Ver4.0Document15 pagesA Survey of Control Approaches For Unmanned Underwater Vehicles 19.8.2023 - Ver4.0Dr Agus BudiyonoNo ratings yet
- Algorithms to calculate, compare, and determine valuesDocument3 pagesAlgorithms to calculate, compare, and determine valuesLee Anne AngelesNo ratings yet
- Edited Sourcebook For Providing TA On PopDev Integration PDFDocument60 pagesEdited Sourcebook For Providing TA On PopDev Integration PDFIbrahim Jade De AsisNo ratings yet
- Behavior of Materials in A Vertical Tube Furnace at 750°C: Standard Test Method ForDocument10 pagesBehavior of Materials in A Vertical Tube Furnace at 750°C: Standard Test Method ForPYDNo ratings yet
- Fy2023 CBLD-9 RevisedDocument11 pagesFy2023 CBLD-9 Revisedbengalyadama15No ratings yet
- Distance Calculation Between 2 Points On EarthDocument3 pagesDistance Calculation Between 2 Points On EarthGirish Madhavan Nambiar100% (2)
- Mathematics F4 Us3Document5 pagesMathematics F4 Us3VERONEJAY MAIKALNo ratings yet
- Data Analysis and Research MethodologyDocument2 pagesData Analysis and Research MethodologyNitishaNo ratings yet
- BiographyDocument3 pagesBiographyPatricia Anne Nicole CuaresmaNo ratings yet
- Ilham Shalabi, Imam Muhammad Bin Saud Islamic UniversityDocument20 pagesIlham Shalabi, Imam Muhammad Bin Saud Islamic Universityaron victoryNo ratings yet
- Guide to designing a strong research proposalDocument11 pagesGuide to designing a strong research proposalmayo ABIOYENo ratings yet
- Homo Deus PDFDocument14 pagesHomo Deus PDFThaw TarNo ratings yet
- Organic Chemistry Lesson on Cyclic HydrocarbonsDocument12 pagesOrganic Chemistry Lesson on Cyclic HydrocarbonsShamarie Love MaribaoNo ratings yet
- Probability TheoryDocument9 pagesProbability TheoryAlamin AhmadNo ratings yet
- đề 20Document5 pagesđề 20duongnguyenthithuy2008No ratings yet
- Lab Audit Checklist (PRIDE) - 2014Document12 pagesLab Audit Checklist (PRIDE) - 2014hoanam2009No ratings yet
- Architect's Professional Practice 2Document48 pagesArchitect's Professional Practice 2Joshua CorpuzNo ratings yet
- Sow English Year 5 2021Document14 pagesSow English Year 5 2021AZRINA ZARIFAH BINTI ZAINAL MoeNo ratings yet
- SDD GROUP (Zuhaira, Zikry, Athirah, Ariff, Aiman)Document11 pagesSDD GROUP (Zuhaira, Zikry, Athirah, Ariff, Aiman)MUHAMMAD HARITH IKHWAN ROSMAEININo ratings yet
- Cce RF Cce RR: RevisedDocument12 pagesCce RF Cce RR: Revisedvedanth rajNo ratings yet
- NRG Systems SRM Station VerificationDocument5 pagesNRG Systems SRM Station VerificationLuis PulidoNo ratings yet
- Quarter 4 - MELC 11: Mathematics Activity SheetDocument9 pagesQuarter 4 - MELC 11: Mathematics Activity SheetSHAIREL GESIMNo ratings yet
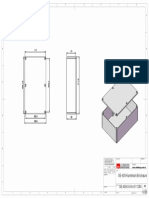
- SE-409 Aluminium Enclosure SE-409-0-0-A-0-11284: RevisionDocument1 pageSE-409 Aluminium Enclosure SE-409-0-0-A-0-11284: RevisionAhmet MehmetNo ratings yet
- PHYS 419 Classical Mechanics Lecture Notes on Quadratic Air ResistanceDocument3 pagesPHYS 419 Classical Mechanics Lecture Notes on Quadratic Air ResistanceComp 3rdNo ratings yet
- Élan VitalDocument3 pagesÉlan Vitalleclub IntelligenteNo ratings yet
- Final CBoW 2020 (Dilnesaw)Document267 pagesFinal CBoW 2020 (Dilnesaw)dilnesaw teshomeNo ratings yet
- Advanced Materials For Hydrogen ProductionDocument150 pagesAdvanced Materials For Hydrogen ProductionGhazanfar SheikhNo ratings yet
- Mumford What Is A City 1937Document5 pagesMumford What Is A City 1937arpithaNo ratings yet