You might also like
- An Overview and Study of Security Issues & Challenges in Cloud ComputingDocument6 pagesAn Overview and Study of Security Issues & Challenges in Cloud ComputingRoyal TNo ratings yet
- UC Siwes ReportDocument13 pagesUC Siwes ReportMAYOWA ADEBAYONo ratings yet
- ForecastingDocument58 pagesForecastingPavithra Gowtham100% (1)
- Book Shop Management System: Project TitleDocument9 pagesBook Shop Management System: Project TitleSanay GagraniNo ratings yet
- Mobile and Wireless Communication Complete Lecture Notes #8Document25 pagesMobile and Wireless Communication Complete Lecture Notes #8Student Lecture NotesNo ratings yet
- OK MasterThesis DisclosureDocument115 pagesOK MasterThesis Disclosureboranga1No ratings yet
- Introduction to Machine Learning in the Cloud with Python: Concepts and PracticesFrom EverandIntroduction to Machine Learning in the Cloud with Python: Concepts and PracticesNo ratings yet
- Time Series Data: y + X + - . .+ X + UDocument81 pagesTime Series Data: y + X + - . .+ X + Uraja ahmedNo ratings yet
- Practice Quiz AnswersDocument40 pagesPractice Quiz AnswersReddy Freddy75% (4)
- Open Data Driving Growth Ingenuity and InnovationDocument36 pagesOpen Data Driving Growth Ingenuity and InnovationAnonymous EBlYNQbiMyNo ratings yet
- Android Application For Call TaxiDocument13 pagesAndroid Application For Call TaxiRam Prasad K100% (2)
- Advanced Machine Learning: CS 281Document88 pagesAdvanced Machine Learning: CS 281Will White100% (1)
- Flutter Notes - RevisedDocument53 pagesFlutter Notes - RevisedYasin YoseffNo ratings yet
- Design and Analysis of Algorithm: Lab FileDocument58 pagesDesign and Analysis of Algorithm: Lab FileSagar 2053 BhanNo ratings yet
- My ArticleDocument20 pagesMy ArticleRory SkrentNo ratings yet
- Design of An Educational Game (Scramble Using Python)Document40 pagesDesign of An Educational Game (Scramble Using Python)Abduljelil ZubairuNo ratings yet
- Srihari 4 JavaDocument4 pagesSrihari 4 JavaSaran ManiNo ratings yet
- DSE 3 Unit 3Document4 pagesDSE 3 Unit 3Priyaranjan SorenNo ratings yet
- DESIGN AND SIMULATION OF FARMER'S FRIEND DEVICE USING IoTDocument8 pagesDESIGN AND SIMULATION OF FARMER'S FRIEND DEVICE USING IoTNIET Journal of Engineering & Technology(NIETJET)No ratings yet
- DSE 3 Unit 2Document18 pagesDSE 3 Unit 2Priyaranjan SorenNo ratings yet
- Implementing Automata Theory in The Design of A Finite Virtual Reality Game (Final Draft)Document8 pagesImplementing Automata Theory in The Design of A Finite Virtual Reality Game (Final Draft)Anthony BarbadilloNo ratings yet
- Attedndance Mangement SystemDocument39 pagesAttedndance Mangement SystemAmen BefekaduNo ratings yet
- AP Narender Singh LabDocument64 pagesAP Narender Singh LabNarender Singh ChauhanNo ratings yet
- Question 1 (10 Marks) : Student ID - 2015046 Student Name Sushan Rajchal Unit Code CIS007Document4 pagesQuestion 1 (10 Marks) : Student ID - 2015046 Student Name Sushan Rajchal Unit Code CIS007Laxman ShresthaNo ratings yet
- Applied Category Theory in Chemistry, Computing, and Social NetworksDocument6 pagesApplied Category Theory in Chemistry, Computing, and Social Networksdon beneno100% (1)
- Awesome Python1 PDFDocument1 pageAwesome Python1 PDFTaras KlimovNo ratings yet
- Advance Database Systems Development: CC6001NADocument37 pagesAdvance Database Systems Development: CC6001NAmetro gNo ratings yet
- B e Cse PDFDocument406 pagesB e Cse PDFKrithigaNo ratings yet
- 06 RNN Et Séquences Temporelles v2.02Document37 pages06 RNN Et Séquences Temporelles v2.02youssefELMOUTEENo ratings yet
- 81composer Us RaDocument140 pages81composer Us RaRodolfo TobiasNo ratings yet
- A Deep Learning Enabled Chatbot Approach For Self-DiagnosisDocument11 pagesA Deep Learning Enabled Chatbot Approach For Self-DiagnosisIJRASETPublicationsNo ratings yet
- Cloud Computing Asm2 Tran Xuan Tu 2Document89 pagesCloud Computing Asm2 Tran Xuan Tu 2Lộc Phạm PhúNo ratings yet
- Structure Programming ApproachDocument23 pagesStructure Programming ApproachjayeshNo ratings yet
- Lecture 1 DAADocument27 pagesLecture 1 DAAtestNo ratings yet
- Computer Vision Based Attendance Management System For StudentsDocument6 pagesComputer Vision Based Attendance Management System For StudentsIJRASETPublicationsNo ratings yet
- Labview - Web PublishingDocument20 pagesLabview - Web PublishingAmit CherianNo ratings yet
- C ExampleDocument11 pagesC ExampleyihunNo ratings yet
- The Mobility LandscapeDocument8 pagesThe Mobility Landscape046 Pawan PawanGuptaNo ratings yet
- The Open 3D GIS Project - A Free Tool To Enable 3D Geographic Systems On The WebDocument6 pagesThe Open 3D GIS Project - A Free Tool To Enable 3D Geographic Systems On The WebHelton Nogueira UchoaNo ratings yet
- Evolution and Trends in GPU ComputingDocument7 pagesEvolution and Trends in GPU ComputingGabriel DonovanNo ratings yet
- Ruby Deep Dive (Jesus Castello)Document250 pagesRuby Deep Dive (Jesus Castello)William Yánez DevNo ratings yet
- Trimble Guide PDFDocument60 pagesTrimble Guide PDFCésar Oswaldo Lazo castroNo ratings yet
- Programming LanguageDocument15 pagesProgramming Languageمصطفى محمد محسن مزعلNo ratings yet
- ATM Simulation Full DoCumEntary With CodeDocument141 pagesATM Simulation Full DoCumEntary With Codevaishnavi kadambariNo ratings yet
- 18CS653 - NOTES Module 1Document24 pages18CS653 - NOTES Module 1SuprithaNo ratings yet
- An Experimental Evaluation of Similarity-Based and Embedding-Based Link Prediction Methods On GraphsDocument18 pagesAn Experimental Evaluation of Similarity-Based and Embedding-Based Link Prediction Methods On GraphsLewis TorresNo ratings yet
- E-Commerce ProjectDocument26 pagesE-Commerce ProjectKomal ChaudhariNo ratings yet
- Brochure CMU NLP 24-08-2022 V13Document13 pagesBrochure CMU NLP 24-08-2022 V13Maria Antonietta RicciNo ratings yet
- Software Design and Architecture JUNE-2021 Sem - II SET-5 (T.Y.B.tech COMP)Document6 pagesSoftware Design and Architecture JUNE-2021 Sem - II SET-5 (T.Y.B.tech COMP)1367 AYUSHA KATEPALLEWARNo ratings yet
- SiriusXM PSAP Overview Document 446655 7Document4 pagesSiriusXM PSAP Overview Document 446655 7AdityaNo ratings yet
- Mapping Dataflow Into ArchitectureDocument12 pagesMapping Dataflow Into ArchitectureVijaya AlukapellyNo ratings yet
- 3.05 Software: Gis Cookbook For LgusDocument4 pages3.05 Software: Gis Cookbook For LgusChristian SantamariaNo ratings yet
- Agile Software Development Lab FileDocument58 pagesAgile Software Development Lab FileSaksham SahasiNo ratings yet
- PDF Version Quick Guide Resources Discussion: Job SearchDocument81 pagesPDF Version Quick Guide Resources Discussion: Job SearchmanigandanNo ratings yet
- Volume 2Document696 pagesVolume 2Kirti Mittal100% (1)
- Good Programming PracticeDocument17 pagesGood Programming PracticeRosette DjeukoNo ratings yet
- Precautionary and Common Medicines: Fingerprint Authentication Secured Android NotesDocument4 pagesPrecautionary and Common Medicines: Fingerprint Authentication Secured Android NotesIsurf CyberNo ratings yet
- AdityaDocument14 pagesAdityaApurv RajNo ratings yet
- Bpo ProcessDocument4 pagesBpo ProcessAvick ChakrabortyNo ratings yet
- Evolution of The QR CodeDocument20 pagesEvolution of The QR Codeapi-272558771No ratings yet
- Review of Threats in IoT Systems Challenges and SolutionsDocument19 pagesReview of Threats in IoT Systems Challenges and SolutionsIJRASETPublicationsNo ratings yet
- Sabarinathansethuraman - 13 Yrs - SLN Developer - AMD - BangaloreDocument7 pagesSabarinathansethuraman - 13 Yrs - SLN Developer - AMD - BangaloreVinodh KumarNo ratings yet
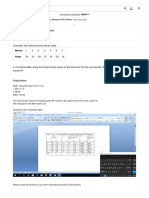
- Solved - Consider The Following Time Series Data. Month 1 2 3 4 5 6 7 Value 24 13 20 12 19 23 15 A....Document3 pagesSolved - Consider The Following Time Series Data. Month 1 2 3 4 5 6 7 Value 24 13 20 12 19 23 15 A....Charles UnlocksNo ratings yet
- Forecasting Models - PPTDocument57 pagesForecasting Models - PPTPRITI DASNo ratings yet
- Econometrics: A Predictive Modeling Approach: Francis X. Diebold University of PennsylvaniaDocument247 pagesEconometrics: A Predictive Modeling Approach: Francis X. Diebold University of PennsylvaniaGülbenNo ratings yet
- Easychair Preprint: Vinod Kimbhaune, Harshil Donga, Asutosh Trivedi, Sonam Mahajan and Viraj MahajanDocument5 pagesEasychair Preprint: Vinod Kimbhaune, Harshil Donga, Asutosh Trivedi, Sonam Mahajan and Viraj MahajanGOVIND AWASTHINo ratings yet
- Final DMT Report PDFDocument27 pagesFinal DMT Report PDFAnonymous Sqb2WONo ratings yet
- Regression AnalysisDocument47 pagesRegression AnalysisRuchika MotwaniNo ratings yet
- Moderation Interpretation Write UpDocument2 pagesModeration Interpretation Write UpHassanRazaNo ratings yet
- LS Estimation Using DLDocument13 pagesLS Estimation Using DLkamarajme2006No ratings yet
- Ingeniera Geotecnica Machine LearningDocument8 pagesIngeniera Geotecnica Machine LearningROBERTO RENZO RIVERA CASASNo ratings yet
- 2022 - Ramirez-Agudelo - Intake Time As Potential Predictor of Methane Emissions From CattleDocument23 pages2022 - Ramirez-Agudelo - Intake Time As Potential Predictor of Methane Emissions From CattleGaius VihowanouNo ratings yet
- L4b - Perfomance Evaluation Metric - RegressionDocument6 pagesL4b - Perfomance Evaluation Metric - RegressionKinya KageniNo ratings yet
- Exercise 03Document5 pagesExercise 03gfjggNo ratings yet
- L2 数量课件Document196 pagesL2 数量课件Ran XUNo ratings yet
- Energies 13 04467Document12 pagesEnergies 13 04467Krishna KumarNo ratings yet
- Ee 769 Assignment 1 PDFDocument11 pagesEe 769 Assignment 1 PDFSachin BisenNo ratings yet
- Temperature Prediction For Reheating Furnace by Gated Recurrent Unit ApproachDocument8 pagesTemperature Prediction For Reheating Furnace by Gated Recurrent Unit ApproachRodrigo LimaNo ratings yet
- Road Materials and Pavement DesignDocument10 pagesRoad Materials and Pavement DesignMasood AhmedNo ratings yet
- Stock-Price-Prediction-Using-Machine-Learning Final Project Indu Mam Project Final ProjectDocument47 pagesStock-Price-Prediction-Using-Machine-Learning Final Project Indu Mam Project Final Projectshubhamkr91234No ratings yet
- Practice Set #6 Demand Management and ForecastingDocument8 pagesPractice Set #6 Demand Management and ForecastingFung CharlotteNo ratings yet
- Francis Diebold - Econometrics SlidesDocument281 pagesFrancis Diebold - Econometrics SlidesPierre Chavez AlcoserNo ratings yet
- Forecasting Intermittent DemandDocument31 pagesForecasting Intermittent DemandnauliNo ratings yet
- Lecture 21: Model Selection 1 Choosing ModelsDocument14 pagesLecture 21: Model Selection 1 Choosing ModelsSNo ratings yet
- Chain Ladder MethodDocument54 pagesChain Ladder MethodTaitip SuphasiriwattanaNo ratings yet
- Chapter 6: Temporal Difference Learning: Objectives of This ChapterDocument49 pagesChapter 6: Temporal Difference Learning: Objectives of This Chapterreshma khemchandaniNo ratings yet
- 2016 FRM1 PracticeExamDocument77 pages2016 FRM1 PracticeExamPaul Antonio Rios MurrugarraNo ratings yet
- Kunci Soal LatihanDocument7 pagesKunci Soal LatihanAgus SetiawanNo ratings yet
- Recent Advances in Wireless Communications and NetworksDocument466 pagesRecent Advances in Wireless Communications and Networksaryanpoor7371No ratings yet