You might also like
- Memory Management 2010Document103 pagesMemory Management 2010frozentoxicNo ratings yet
- OCamlDocument11 pagesOCamlFlavio GondinNo ratings yet
- LPC2378 PDFDocument709 pagesLPC2378 PDFChidvilas BNo ratings yet
- Unit 01 Basic Concepts of DBMS & Data ModelsDocument150 pagesUnit 01 Basic Concepts of DBMS & Data Models29Vaishnavi Kadam100% (1)
- Microprocessor 80386Document17 pagesMicroprocessor 80386gujusNo ratings yet
- Computer Architecture: Von Neumann vs HarvardDocument11 pagesComputer Architecture: Von Neumann vs HarvardWINORLOSENo ratings yet
- Addressing ModeDocument88 pagesAddressing Modehar100% (4)
- Harvard ArchitectureDocument3 pagesHarvard Architecturebalu4allNo ratings yet
- Mac OS X - DESIGN PRINCIPLES AND KERNEL MODULESDocument16 pagesMac OS X - DESIGN PRINCIPLES AND KERNEL MODULESapi-3700456No ratings yet
- Microprocessor 80486Document6 pagesMicroprocessor 80486Gaurav BisaniNo ratings yet
- Recommended reading for prospective CS studentsDocument4 pagesRecommended reading for prospective CS studentssushantNo ratings yet
- Unisys Part ForSQL64 Bit Seminars v10Document53 pagesUnisys Part ForSQL64 Bit Seminars v10Mohamed MohsenNo ratings yet
- Presentation On CPUDocument25 pagesPresentation On CPUbabu50% (2)
- Intel's PENTIUM-II III PROCESSORSDocument24 pagesIntel's PENTIUM-II III PROCESSORSgovindamittal07No ratings yet
- Assignment 1Document3 pagesAssignment 1JAYAPAL MNo ratings yet
- Constellations 2010 Silicon Valley - Complete Slide SetDocument227 pagesConstellations 2010 Silicon Valley - Complete Slide SetWarren SavageNo ratings yet
- Understanding Operating Systems Seventh EditionDocument58 pagesUnderstanding Operating Systems Seventh EditionHave No IdeaNo ratings yet
- Isovalent White Paper eBPF ServicemeshDocument16 pagesIsovalent White Paper eBPF ServicemeshAmim KnabbenNo ratings yet
- Peripherals and Components of a Computer SystemDocument21 pagesPeripherals and Components of a Computer SystemS ARSHIYA VU21CSEN0500245No ratings yet
- Chapter 08-Secondary StorageDocument5 pagesChapter 08-Secondary StoragehumazeeshanNo ratings yet
- ARM926EJ S Overview PDFDocument12 pagesARM926EJ S Overview PDFSlavko MitrovicNo ratings yet
- Recurrent Neurona NetworkDocument59 pagesRecurrent Neurona NetworkMiguel Angel Alvarado RamosNo ratings yet
- Difference Between Von Neumann and Harvard ArchitectureDocument4 pagesDifference Between Von Neumann and Harvard Architectureramadan hundessaNo ratings yet
- ARM architecture family overviewDocument35 pagesARM architecture family overviewHeera SinghNo ratings yet
- LPC 2378 Development BoardDocument160 pagesLPC 2378 Development BoardDinesh KumarNo ratings yet
- HP Z440, Z640, and Z840 Workstation Series: Maintenance and Service GuideDocument132 pagesHP Z440, Z640, and Z840 Workstation Series: Maintenance and Service GuideMiguel PagkalinawanNo ratings yet
- EP - Unit - V - Real World Interfacing With Cortex M4 Based MicrocontrollerDocument114 pagesEP - Unit - V - Real World Interfacing With Cortex M4 Based Microcontrollerganesh SawantNo ratings yet
- IBM WCS Introduction and Architecture OverviewDocument60 pagesIBM WCS Introduction and Architecture OverviewKranthiNo ratings yet
- Media Types for Data-Driven StorytellingDocument15 pagesMedia Types for Data-Driven StorytellingKamranNo ratings yet
- Lecture 10Document34 pagesLecture 10MAIMONA KHALIDNo ratings yet
- AssignmentDocument5 pagesAssignmentSpike Hari100% (1)
- Chapter 1. Networking and Storage ConceptsDocument31 pagesChapter 1. Networking and Storage ConceptsBhaskar ChowdaryNo ratings yet
- 21CS43 Module 5 Microcontroller and Embedded Systems Prof VANARASANDocument41 pages21CS43 Module 5 Microcontroller and Embedded Systems Prof VANARASANNikhil chandNo ratings yet
- Power PC ArchitectureDocument28 pagesPower PC ArchitecturedesamratNo ratings yet
- 64 Bit Processors - 1Document15 pages64 Bit Processors - 1Asim NeupaneNo ratings yet
- Technical Note: Software Device Drivers For Micron MT29F NAND Flash MemoryDocument12 pagesTechnical Note: Software Device Drivers For Micron MT29F NAND Flash MemorygogiNo ratings yet
- ATmega8 As Arduino Using Internal 8Mhz CrystalDocument8 pagesATmega8 As Arduino Using Internal 8Mhz Crystalvictor AjahNo ratings yet
- Problem Bank 28Document8 pagesProblem Bank 28Rosaria SammuelsNo ratings yet
- Evolution of MicroProcessorDocument28 pagesEvolution of MicroProcessorRafat Touqir RafsunNo ratings yet
- Chapter5-The Memory SystemDocument78 pagesChapter5-The Memory SystemAvirup RayNo ratings yet
- Dual Core Vs Core 2 DuoDocument5 pagesDual Core Vs Core 2 DuogermainjulesNo ratings yet
- OS Part-1: Fundamentals of Operating SystemsDocument12 pagesOS Part-1: Fundamentals of Operating SystemsGovind GuptaNo ratings yet
- Pentium Memory Hierarchy (By Indranil Nandy, IIT KGP)Document6 pagesPentium Memory Hierarchy (By Indranil Nandy, IIT KGP)Indranil Nandy100% (5)
- GPUDocument17 pagesGPUJayanti SinghNo ratings yet
- DCC Lab Manual Final Practicals PDFDocument152 pagesDCC Lab Manual Final Practicals PDFKaran LatayeNo ratings yet
- Data FusionDocument35 pagesData FusionBernardo Diaz SuarezNo ratings yet
- The Hindu Review January 2023Document56 pagesThe Hindu Review January 2023rajesh naikNo ratings yet
- Brocade Fabric OS Software Upgrade User Guide, 8.2.x: FOS-821-SW-Upgrade-UG104 March 15, 2021Document32 pagesBrocade Fabric OS Software Upgrade User Guide, 8.2.x: FOS-821-SW-Upgrade-UG104 March 15, 2021Fouad BaroutNo ratings yet
- Windows Memory BasicsDocument5 pagesWindows Memory BasicsGrant WillcoxNo ratings yet
- 11TB01 - Performance Guidelines For IBM InfoSphere DataStage Jobs Containing Sort Operations On Intel Xeon-FinalDocument22 pages11TB01 - Performance Guidelines For IBM InfoSphere DataStage Jobs Containing Sort Operations On Intel Xeon-FinalMonica MarciucNo ratings yet
- A Chatbot Using LSTM-based Multi-Layer Embedding For Elderly CareDocument5 pagesA Chatbot Using LSTM-based Multi-Layer Embedding For Elderly CareBoni ChalaNo ratings yet
- A Hybrid CNN-LSTM: A Deep Learning Approach For Consumer Sentiment Analysis Using Qualitative User-Generated ContentsDocument15 pagesA Hybrid CNN-LSTM: A Deep Learning Approach For Consumer Sentiment Analysis Using Qualitative User-Generated ContentsBhaskar PathakNo ratings yet
- Microcontrollres NotesDocument66 pagesMicrocontrollres Notesthiruct77No ratings yet
- NetApp Backup and Recovery Solution BriefDocument4 pagesNetApp Backup and Recovery Solution BriefrmanikandanNo ratings yet
- Lesson 5 - Business Analytics and Big DataDocument39 pagesLesson 5 - Business Analytics and Big DataISSNewHQNo ratings yet
- 7BCEE1A-Datamining and Data WarehousingDocument128 pages7BCEE1A-Datamining and Data WarehousingHari KrishnaNo ratings yet
- Kernel Memory ManagementDocument37 pagesKernel Memory ManagementSneha DollyNo ratings yet
- Nintendo 64 Architecture: Architecture of Consoles: A Practical Analysis, #8From EverandNintendo 64 Architecture: Architecture of Consoles: A Practical Analysis, #8No ratings yet
- CS347 Memory Management in xv6 Operating SystemDocument5 pagesCS347 Memory Management in xv6 Operating SystemMohit DasNo ratings yet
- Lec 22-24 Paging + TLBDocument31 pagesLec 22-24 Paging + TLBRIYANo ratings yet
- Hyundai 14 - 16 - 20 - 25BRJ-9Document8 pagesHyundai 14 - 16 - 20 - 25BRJ-9NayanajithNo ratings yet
- 1967 2013 PDFDocument70 pages1967 2013 PDFAlberto Dorado Martín100% (1)
- PowerHA SystemMirror Session 2 OverviewDocument80 pagesPowerHA SystemMirror Session 2 OverviewFabrice PLATELNo ratings yet
- Samples For Loanshyd-1Document3 pagesSamples For Loanshyd-1dpkraja100% (1)
- Abbadvant 800 XaDocument9 pagesAbbadvant 800 XaAlexNo ratings yet
- Ebooks vs Traditional Books: An AnalysisDocument10 pagesEbooks vs Traditional Books: An AnalysisLOVENo ratings yet
- Gender Support Plan PDFDocument4 pagesGender Support Plan PDFGender SpectrumNo ratings yet
- Applsci 13 13339Document25 pagesApplsci 13 13339ambroseoryem1No ratings yet
- PHP Oop: Object Oriented ProgrammingDocument21 pagesPHP Oop: Object Oriented ProgrammingSeptia ni Dwi Rahma PutriNo ratings yet
- Readings On The History and System of The Common Law - Roscoe PoundDocument646 pagesReadings On The History and System of The Common Law - Roscoe PoundpajorocNo ratings yet
- Mfi in GuyanaDocument19 pagesMfi in Guyanadale2741830No ratings yet
- Parison of Dia para FerroDocument4 pagesParison of Dia para FerroMUNAZIRR FATHIMA F100% (1)
- Performance Evaluation of Root Crop HarvestersDocument15 pagesPerformance Evaluation of Root Crop HarvestersIJERDNo ratings yet
- PBL PgamboaDocument6 pagesPBL PgamboaLeanne Princess GamboaNo ratings yet
- OSK Ekonomi 2016 - SoalDocument19 pagesOSK Ekonomi 2016 - SoalputeNo ratings yet
- Explicit Instruction: A Teaching Strategy in Reading, Writing, and Mathematics For Students With Learning DisabilitiesDocument3 pagesExplicit Instruction: A Teaching Strategy in Reading, Writing, and Mathematics For Students With Learning DisabilitiesKatherineNo ratings yet
- Anubis - Analysis ReportDocument17 pagesAnubis - Analysis ReportÁngelGarcíaJiménezNo ratings yet
- Ic T7HDocument36 pagesIc T7HCarlos GaiarinNo ratings yet
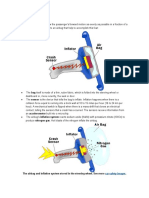
- Airbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreDocument5 pagesAirbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreShivankur HingeNo ratings yet
- 7 Ways of Looking at Grammar China EditDocument20 pages7 Ways of Looking at Grammar China EditAshraf MousaNo ratings yet
- 2.e-Learning Chapter 910Document23 pages2.e-Learning Chapter 910ethandanfordNo ratings yet
- Few Words About Digital Protection RelayDocument5 pagesFew Words About Digital Protection RelayVasudev AgrawalNo ratings yet
- 4 Types and Methods of Speech DeliveryDocument2 pages4 Types and Methods of Speech DeliveryKylie EralinoNo ratings yet
- Hps40 Tech Doc ScreenDocument20 pagesHps40 Tech Doc ScreenAnonymous oyUAtpKNo ratings yet
- M HNDTL SCKT Imp BP RocDocument2 pagesM HNDTL SCKT Imp BP RocAhmed Abd El RahmanNo ratings yet
- TaxonomyDocument56 pagesTaxonomyKrezia Mae SolomonNo ratings yet
- HE HOUSEKEEPING GR11 Q1 MODULE-6-for-teacherDocument25 pagesHE HOUSEKEEPING GR11 Q1 MODULE-6-for-teacherMikaela YtacNo ratings yet
- India: Soil Types, Problems & Conservation: Dr. SupriyaDocument25 pagesIndia: Soil Types, Problems & Conservation: Dr. SupriyaManas KaiNo ratings yet
- Creatinine JaffeDocument2 pagesCreatinine JaffeOsinachi WilsonNo ratings yet
- Bioprocess Engineering QuestionsDocument13 pagesBioprocess Engineering QuestionsPalanisamy Selvamani100% (1)