You might also like
- Radically Elementary Probability Theory. (AM-117), Volume 117From EverandRadically Elementary Probability Theory. (AM-117), Volume 117Rating: 4 out of 5 stars4/5 (2)
- Formulae SheetDocument11 pagesFormulae Sheetthyanh.vuNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- STA222 Week7Document14 pagesSTA222 Week7Kimondo KingNo ratings yet
- DistributionsDocument4 pagesDistributionsNarendra KNo ratings yet
- Random Vectors and Multivariate Normal DistributionDocument6 pagesRandom Vectors and Multivariate Normal DistributionJohn SmithNo ratings yet
- Mathematical Foundations of Computer Science Lecture OutlineDocument4 pagesMathematical Foundations of Computer Science Lecture OutlineChenyang FangNo ratings yet
- Order StatisticsDocument3 pagesOrder StatisticsSiti ZirahraiNo ratings yet
- Probability and Stochastic Process 21Document12 pagesProbability and Stochastic Process 21tarungajjuwaliaNo ratings yet
- STA 303 Lec 1Document5 pagesSTA 303 Lec 1kuriajames147No ratings yet
- Most Powerful Normal Distribution TestDocument2 pagesMost Powerful Normal Distribution TestYogiWahyudiNo ratings yet
- X-Ray Notes Part2 of 3Document24 pagesX-Ray Notes Part2 of 3LillyOpenMindNo ratings yet
- Complete Metric Space: 1 SequenceDocument44 pagesComplete Metric Space: 1 SequenceAvijit SamantaNo ratings yet
- Mathematical Foundations of Computer Science Lecture OutlineDocument4 pagesMathematical Foundations of Computer Science Lecture OutlineChenyang FangNo ratings yet
- CSD311: Artificial IntelligenceDocument33 pagesCSD311: Artificial IntelligenceAyaan KhanNo ratings yet
- Assignment 1: Probability : Partial SolutionDocument7 pagesAssignment 1: Probability : Partial SolutionVirda SetyaniNo ratings yet
- Bernoulli R.VDocument8 pagesBernoulli R.VKelvinNo ratings yet
- Section06 SolutionsDocument15 pagesSection06 SolutionsMuhammad asafNo ratings yet
- S289-231formula Sheet m2Document2 pagesS289-231formula Sheet m2Sania SamiNo ratings yet
- Section06 SolutionsDocument11 pagesSection06 SolutionsKarimaNo ratings yet
- MAT205T: Probability Theory: S VijayakumarDocument72 pagesMAT205T: Probability Theory: S VijayakumarEDM19B015 THODETI CHINA BABUNo ratings yet
- Ee132b Hw1 SolDocument4 pagesEe132b Hw1 SolAhmed HassanNo ratings yet
- Lecture 20Document5 pagesLecture 20Ritik KumarNo ratings yet
- Ps 1Document6 pagesPs 1Jesus Enrique Miranda BlancoNo ratings yet
- Oscillation Criteria For Systems of Difference Equations With Variable Coe CientsDocument7 pagesOscillation Criteria For Systems of Difference Equations With Variable Coe CientsLuis Alberto FuentesNo ratings yet
- Summations ADocument10 pagesSummations ADefault AccountNo ratings yet
- ECMT1020 Formulas 2021Document9 pagesECMT1020 Formulas 2021Darius ZhuNo ratings yet
- Queuing Theory PDFDocument38 pagesQueuing Theory PDFNelson FicaNo ratings yet
- PRML Solution ManualDocument253 pagesPRML Solution ManualHaolong LiuNo ratings yet
- SST 204 Courtesy of Michelle OwinoDocument63 pagesSST 204 Courtesy of Michelle OwinoplugwenuNo ratings yet
- Stochastic Processes and Time Series Markov Chains - II: 1 Conditional Probability ResultsDocument5 pagesStochastic Processes and Time Series Markov Chains - II: 1 Conditional Probability ResultsBiju AngaleesNo ratings yet
- s131 Reviewer 002Document14 pagess131 Reviewer 002lucy heartfiliaNo ratings yet
- MIT6 436JF18 Lec06Document18 pagesMIT6 436JF18 Lec06DevendraReddyPoreddyNo ratings yet
- Indicator functions and expected values explainedDocument10 pagesIndicator functions and expected values explainedPatricio Antonio VegaNo ratings yet
- Moment Generating Functions ExplainedDocument6 pagesMoment Generating Functions Explainedmoh01362eoopyomNo ratings yet
- CH 4Document33 pagesCH 4hung13579No ratings yet
- Probability and Statistics: PopulationDocument14 pagesProbability and Statistics: PopulationAjaya Kumar Patel100% (1)
- MA40092 PROBLEM SHEET 3 - SOLUTIONSDocument4 pagesMA40092 PROBLEM SHEET 3 - SOLUTIONSJhonnataCarvalhoNo ratings yet
- SummaryDocument3 pagesSummaryKHÁNH NGÔ ĐÌNH BẢONo ratings yet
- 1 Sufficient Statistics:, X,, X, X,, XDocument6 pages1 Sufficient Statistics:, X,, X, X,, XELIBER DIONISIO RODR�GUEZ GONZALESNo ratings yet
- Poisson Distribution 2Document14 pagesPoisson Distribution 2KashafNo ratings yet
- ECMT1020 2023S1 FormulasDocument10 pagesECMT1020 2023S1 Formulasvladimirputino1No ratings yet
- ST903 Week6solDocument2 pagesST903 Week6solLuke JohnstonNo ratings yet
- ExpectationDocument19 pagesExpectationShah FahadNo ratings yet
- Definition 4.1.1.: R Then We Could Define ADocument42 pagesDefinition 4.1.1.: R Then We Could Define AAkshayNo ratings yet
- Analysis of functions using substitution theorem and properties of Riemann integralsDocument3 pagesAnalysis of functions using substitution theorem and properties of Riemann integralsMainak SamantaNo ratings yet
- Moments, moment generating functions, and random variable propertiesDocument10 pagesMoments, moment generating functions, and random variable propertiestegarpradanaNo ratings yet
- More Discrete R.VDocument40 pagesMore Discrete R.VjiddagerNo ratings yet
- Lecture 8Document4 pagesLecture 8anonymousNo ratings yet
- Lecture 5Document3 pagesLecture 5gikiruroseNo ratings yet
- Series by FourierDocument6 pagesSeries by FourierMandela Bright QuashieNo ratings yet
- Equation SheetDocument5 pagesEquation SheetArisha BasheerNo ratings yet
- ECS315 2014 Postmidterm U1 PDFDocument89 pagesECS315 2014 Postmidterm U1 PDFArima AckermanNo ratings yet
- Ch2 Interpolation 2022Document27 pagesCh2 Interpolation 2022SK. BayzeedNo ratings yet
- Independent Random Variables Review and ExamplesDocument34 pagesIndependent Random Variables Review and ExamplesAntonio JNo ratings yet
- Math 3215 Intro. Probability & Statistics Summer '14 Homework 2Document4 pagesMath 3215 Intro. Probability & Statistics Summer '14 Homework 2Pei JingNo ratings yet
- Chebysev Inequality: Suppose and VarianceDocument13 pagesChebysev Inequality: Suppose and VarianceMuthusivaramapandian MuthurajNo ratings yet
- Binomial and Poisson DistributionDocument26 pagesBinomial and Poisson Distributionmahnoorjamali853No ratings yet
- hw4 SolnsDocument5 pageshw4 SolnsOm Mani Padme HumNo ratings yet
- WW1 Causes and ResultsDocument101 pagesWW1 Causes and ResultsBrenda MakonoNo ratings yet
- Ndebele Word CategoriesDocument4 pagesNdebele Word CategoriesCarl Ushe100% (1)
- HASTS212 Lecture 4Document21 pagesHASTS212 Lecture 4Carl UsheNo ratings yet
- Ndebele Lesson Body PartsDocument2 pagesNdebele Lesson Body PartsCarl Ushe100% (1)
- HASTS212 Lecture 3Document39 pagesHASTS212 Lecture 3Carl UsheNo ratings yet
- ScienceofscienceDocument10 pagesScienceofscienceCarl UsheNo ratings yet
- Daftar PustakaDocument8 pagesDaftar PustakaAbiezer AnggaNo ratings yet
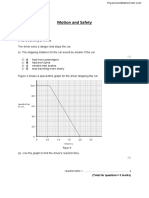
- 2.3 Motion and SafetyDocument13 pages2.3 Motion and SafetyGeorge TongNo ratings yet
- Tohatsu 2 Stroke Service Manual 1992 2000Document329 pagesTohatsu 2 Stroke Service Manual 1992 2000Adi Peterfi97% (38)
- MSC - Nastran 2014 Linear Static Analysis User's Guide PDFDocument762 pagesMSC - Nastran 2014 Linear Static Analysis User's Guide PDFFeiNo ratings yet
- Human Persons Are Oriented Toward Their Impending DeathDocument40 pagesHuman Persons Are Oriented Toward Their Impending DeathNaddy Retxed100% (1)
- Operation and Safety Manual: Ansi As/NzsDocument116 pagesOperation and Safety Manual: Ansi As/NzsMuhammad AwaisNo ratings yet
- Design Approval Checklist 2nd Rev.Document3 pagesDesign Approval Checklist 2nd Rev.Daric Tesfaye0% (1)
- Cost-Time-Resource Sheet for Rumaila Oil Field Engineering ServicesDocument13 pagesCost-Time-Resource Sheet for Rumaila Oil Field Engineering ServicesonlyikramNo ratings yet
- Sem NotesDocument39 pagesSem NotesN NandiniNo ratings yet
- Design of Base Slab of UGTDocument5 pagesDesign of Base Slab of UGTAamir SuhailNo ratings yet
- B. Glo Bal Maxima/MinimaDocument15 pagesB. Glo Bal Maxima/MinimalucasNo ratings yet
- Ddec IV Application and InstallationDocument148 pagesDdec IV Application and Installationsptecnico8292% (36)
- Creating Quizzes in MS PowerPointDocument6 pagesCreating Quizzes in MS PowerPointZiel Cabungcal CardañoNo ratings yet
- Sub Net Questions With AnsDocument5 pagesSub Net Questions With AnsSavior Wai Hung WongNo ratings yet
- Part IIDocument281 pagesPart IILeng SovannarithNo ratings yet
- Robinair Mod 10324Document16 pagesRobinair Mod 10324StoneAge1No ratings yet
- Did You Ever Meet Shattered Illusions?Document5 pagesDid You Ever Meet Shattered Illusions?Junjie HuangNo ratings yet
- CLASS 10 CH-1 ECO DEVELOPMENT Question AnswersDocument8 pagesCLASS 10 CH-1 ECO DEVELOPMENT Question AnswersDoonites DelhiNo ratings yet
- Krish Kumar 13 Activity 5 SolutionDocument39 pagesKrish Kumar 13 Activity 5 SolutionkrishNo ratings yet
- User Manual Thomson Mec 310#genset Controller Option J Canbus j1939 eDocument14 pagesUser Manual Thomson Mec 310#genset Controller Option J Canbus j1939 eJapraAnugrahNo ratings yet
- Lecture Notes (Chapter 2.3 Triple Integral)Document5 pagesLecture Notes (Chapter 2.3 Triple Integral)shinee_jayasila2080100% (1)
- Prelim Quiz 1 ResultsDocument27 pagesPrelim Quiz 1 Resultsgummy bearNo ratings yet
- P90X2 Les Mills PUMP HybridDocument7 pagesP90X2 Les Mills PUMP HybridRamonBeltranNo ratings yet
- Understanding Negation in Indian LogicDocument10 pagesUnderstanding Negation in Indian LogicvasubandhuNo ratings yet
- Overhead Management through Template ConfigurationDocument5 pagesOverhead Management through Template ConfigurationBalanathan VirupasanNo ratings yet
- Species - Age of RebellionDocument10 pagesSpecies - Age of RebellionLeo VieiraNo ratings yet
- ICs Interface and Motor DriversDocument4 pagesICs Interface and Motor DriversJohn Joshua MontañezNo ratings yet
- International Emergency Nursing: Karen Hammad, Lingli Peng, Olga Anikeeva, Paul Arbon, Huiyun Du, Yinglan LiDocument5 pagesInternational Emergency Nursing: Karen Hammad, Lingli Peng, Olga Anikeeva, Paul Arbon, Huiyun Du, Yinglan LiRuly AryaNo ratings yet
- CHAPTER 9 Microsoft Excel 2016 Back ExerciseDocument3 pagesCHAPTER 9 Microsoft Excel 2016 Back ExerciseGargi SinghNo ratings yet
- Fugacity CoefficientDocument4 pagesFugacity Coefficientsigit1058No ratings yet
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (79)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)From EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No ratings yet