You might also like
- M7 Muhammad Sandhi Khadafi 2KB04 (20122007)Document16 pagesM7 Muhammad Sandhi Khadafi 2KB04 (20122007)Nanang ArifNo ratings yet
- 2 Tekrek M7 KNN - DGX 1Document15 pages2 Tekrek M7 KNN - DGX 12IA02Faris Hidayat ArrahmanNo ratings yet
- 2IA02 Fauzan RamadhanDocument10 pages2IA02 Fauzan Ramadhan2IA02Faris Hidayat ArrahmanNo ratings yet
- Predictive+Modelling+-+Logistic+Regression+-+Student+Version-New2.3.ipynb - ColaboratoryDocument12 pagesPredictive+Modelling+-+Logistic+Regression+-+Student+Version-New2.3.ipynb - ColaboratorySHEKHAR SWAMINo ratings yet
- Name:Fedrick Samuel W Reg No: 19MIS1112 Course: Machine Learning (SWE4012) Slot: L11 + L12 Faculty: Dr.M. PremalathaDocument30 pagesName:Fedrick Samuel W Reg No: 19MIS1112 Course: Machine Learning (SWE4012) Slot: L11 + L12 Faculty: Dr.M. PremalathaFèdríck SämùélNo ratings yet
- PandasDocument49 pagesPandassubodhaade2No ratings yet
- Bagian 2: Transformasi Data Dengan Tipe Kategori : 'Install' 'Seaborn'Document10 pagesBagian 2: Transformasi Data Dengan Tipe Kategori : 'Install' 'Seaborn'Rico AlfredoNo ratings yet
- Output1Document8 pagesOutput1Laptop-Dimas-249No ratings yet
- Tugas-Bank-Campaign (1) .Ipynb - ColaboratoryDocument29 pagesTugas-Bank-Campaign (1) .Ipynb - ColaboratoryAlexander TiopanNo ratings yet
- I.P PracticalDocument48 pagesI.P PracticalKavoNo ratings yet
- Loadalgarve MLPDocument7 pagesLoadalgarve MLPRony RockNo ratings yet
- ML File 211173Document19 pagesML File 211173NANDINI AGGARWAL 211131No ratings yet
- Machine Learning Project Problem 1 Jupyter Notebook PDFDocument85 pagesMachine Learning Project Problem 1 Jupyter Notebook PDFsonali Pradhan100% (4)
- Instructions:: Mltest2question - Jupyter NotebookDocument6 pagesInstructions:: Mltest2question - Jupyter NotebookAniruddha TrivediNo ratings yet
- Untitled4 Assigment 3Document9 pagesUntitled4 Assigment 3eigintaeeNo ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Practica 11Document7 pagesPractica 112marlenehh2003No ratings yet
- Day 1 Python NotebookDocument19 pagesDay 1 Python NotebookAviral SaxenaNo ratings yet
- IP Practic MINEDocument30 pagesIP Practic MINESouryo Das GuptaNo ratings yet
- Pyt Manual 1Document85 pagesPyt Manual 1Hrithik KumarNo ratings yet
- Bank Marketing InglesDocument37 pagesBank Marketing InglesFlavio SalazarNo ratings yet
- Running RFM in PythonDocument7 pagesRunning RFM in PythonSakshi Singh YaduvanshiNo ratings yet
- Quora Question Pair Similarity ProblemDocument41 pagesQuora Question Pair Similarity Problemaggarwal nNo ratings yet
- Advanced ML PDFDocument25 pagesAdvanced ML PDFsushanthNo ratings yet
- Practice TestDocument12 pagesPractice TestSanjayNo ratings yet
- Decision TreeDocument12 pagesDecision TreeKagade AjinkyaNo ratings yet
- ProjeDocument140 pagesProjeMurat ÖzaydınNo ratings yet
- SLOT - D1+D2: Digital Assignment - I - Summer Semester 2020-2021Document9 pagesSLOT - D1+D2: Digital Assignment - I - Summer Semester 2020-2021Ganesh K 18MIS0157No ratings yet
- 20bce2251 VL2021220503859 Ast05Document4 pages20bce2251 VL2021220503859 Ast05TANMAY MEHROTRANo ratings yet
- Import As Import As From Import As Import As Import AsDocument3 pagesImport As Import As From Import As Import As Import AsDeepesh YadavNo ratings yet
- Diwali Sales Analysis EDA 1696347982Document8 pagesDiwali Sales Analysis EDA 1696347982Trần Diệu HoaNo ratings yet
- Users of A Music Streaming Service Will Churn or Stay: @staticmethodDocument1 pageUsers of A Music Streaming Service Will Churn or Stay: @staticmethodGowtham SuguNo ratings yet
- IP - Record 2023-24Document79 pagesIP - Record 2023-24FreyaNo ratings yet
- BroomspatialDocument31 pagesBroomspatialHolaq Ola OlaNo ratings yet
- Twitter Project2Document339 pagesTwitter Project2ANAN OptimizationNo ratings yet
- Class 7Document17 pagesClass 7Roli DubeNo ratings yet
- Customer Retention in BankDocument27 pagesCustomer Retention in BankHarun ul Rasheed ShaikNo ratings yet
- DW 14Document14 pagesDW 14SowmyaNo ratings yet
- 03 Exp5 AbhishekDocument7 pages03 Exp5 Abhishek03 Bhingle AbhishekNo ratings yet
- Sunbase Data AssignmentDocument11 pagesSunbase Data Assignmentfanrock281No ratings yet
- What Are Decision Trees?Document9 pagesWhat Are Decision Trees?eng_mahesh1012No ratings yet
- LifeFrequency ManualDocument111 pagesLifeFrequency ManualEgwuatu UchennaNo ratings yet
- B - 59 - SMA - Exp 4Document9 pagesB - 59 - SMA - Exp 4Ritz FernandesNo ratings yet
- AnsKey SQP2 CS XII T2 2022 YKDocument7 pagesAnsKey SQP2 CS XII T2 2022 YKTanishqNo ratings yet
- SN Travel Jupyter Notebook PDFDocument28 pagesSN Travel Jupyter Notebook PDFsonali PradhanNo ratings yet
- Suicide AnalysisDocument18 pagesSuicide AnalysisNandhini AnandNo ratings yet
- Observation: As We Can See We Have Threwe Types of Datatypes I.E. (Int, Float, Object) That Means We Have Both Categorical and Numerical DataDocument2 pagesObservation: As We Can See We Have Threwe Types of Datatypes I.E. (Int, Float, Object) That Means We Have Both Categorical and Numerical DataPRATIK RATHODNo ratings yet
- Data Wrangling AssignmentDocument17 pagesData Wrangling Assignmentshahfaisal gfgNo ratings yet
- Human Activity Recognition Using Smartphone DataDocument18 pagesHuman Activity Recognition Using Smartphone DataofficialimranebenNo ratings yet
- Income Qualification Project3Document40 pagesIncome Qualification Project3NikhilNo ratings yet
- Heart Failure PredictionDocument41 pagesHeart Failure PredictionAKKALA VIJAYGOUD100% (1)
- Tugas MPS Variabel JurnalDocument5 pagesTugas MPS Variabel JurnalIrfan HermawanNo ratings yet
- Statisitics Project 6Document48 pagesStatisitics Project 6AMAN PRAKASH100% (2)
- Practical File Questions With AnswersDocument7 pagesPractical File Questions With AnswersPriyanshu KumarNo ratings yet
- LogDocument4 pagesLoghajirjir897No ratings yet
- Day44 KNN ClassificationDocument2 pagesDay44 KNN ClassificationIgor FernandesNo ratings yet
- Chapter 1Document22 pagesChapter 1Rodrigo Pasten CortesNo ratings yet
- OIA With ADBCDocument2 pagesOIA With ADBCNikhil BhatiaNo ratings yet
- In in in In: '/kaggle/input/data-19-1/data'Document6 pagesIn in in In: '/kaggle/input/data-19-1/data'sambitsoftNo ratings yet
- 03 Activity 3 - ARGDocument4 pages03 Activity 3 - ARGstapaNo ratings yet
- Xhibit: Redacted OF Document Sought TO BE SealedDocument10 pagesXhibit: Redacted OF Document Sought TO BE SealedChance MillerNo ratings yet
- The Microprocessor and Its ArchitectureDocument26 pagesThe Microprocessor and Its ArchitecturebassamNo ratings yet
- SpiderCloud System Commissioning Guide (LCI) Release 3.1Document76 pagesSpiderCloud System Commissioning Guide (LCI) Release 3.1Hector Solarte50% (2)
- Task 3 - Information - Asset - Management - Policy - V.0Document15 pagesTask 3 - Information - Asset - Management - Policy - V.0Rex DanielNo ratings yet
- SEC3014 Part4cDocument38 pagesSEC3014 Part4cYeong Lee SenggNo ratings yet
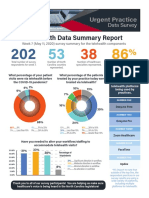
- UPDS Telehealth Data ReportDocument3 pagesUPDS Telehealth Data ReportCorey LarkinsNo ratings yet
- Tutorial 5 EKT 230 Signals & Systems: N U N U N XDocument2 pagesTutorial 5 EKT 230 Signals & Systems: N U N U N XTan Yean YeanNo ratings yet
- Parts Catalog: I R 1 0 2 3 / 1 0 2 2 / 1 0 1 9 / 1 0 1 8 SeriesDocument84 pagesParts Catalog: I R 1 0 2 3 / 1 0 2 2 / 1 0 1 9 / 1 0 1 8 SeriesmarecalinNo ratings yet
- Study of Socket Programming and Client SDocument4 pagesStudy of Socket Programming and Client Snkprannesh12No ratings yet
- Performance Task No. 1 3 Quarter: Mathematics 6Document4 pagesPerformance Task No. 1 3 Quarter: Mathematics 6Shimmer CrossbonesNo ratings yet
- Risso Error CodesDocument41 pagesRisso Error Codesnickypanze97% (30)
- Fast Track Magazine Malayalam PDFDocument3 pagesFast Track Magazine Malayalam PDFshanty joseph100% (1)
- Memory and I/O Decoding: The x86 Microprocessor - Lyla B Das 1Document61 pagesMemory and I/O Decoding: The x86 Microprocessor - Lyla B Das 1A Samuel ClementNo ratings yet
- Robowars: Important Notes and GuidelinesDocument5 pagesRobowars: Important Notes and GuidelinesAkash KumarNo ratings yet
- GPON PresentationDocument20 pagesGPON Presentationwoody0100% (2)
- Manual - PMAC Qiuck Reference GuideDocument88 pagesManual - PMAC Qiuck Reference GuideqwerNo ratings yet
- Super Vag K Can v4.8 User Manual PDFDocument11 pagesSuper Vag K Can v4.8 User Manual PDFroberto caiado100% (1)
- Doctopus Instructions - Mrs AssimDocument6 pagesDoctopus Instructions - Mrs Assimapi-239505062No ratings yet
- Students Attendances System Using Face RecognitionDocument8 pagesStudents Attendances System Using Face RecognitionIJRASETPublicationsNo ratings yet
- Emotion DetectorDocument5 pagesEmotion DetectorEditor IJTSRDNo ratings yet
- Account Statement From 4 Jun 2021 To 31 Mar 2022: TXN Date Value Date Description Ref No./Cheque No. Debit Credit BalanceDocument3 pagesAccount Statement From 4 Jun 2021 To 31 Mar 2022: TXN Date Value Date Description Ref No./Cheque No. Debit Credit BalanceSaleem KhanNo ratings yet
- CV - Jelinta Margareth Rotua - 2022Document1 pageCV - Jelinta Margareth Rotua - 2022sandy fumyNo ratings yet
- Paper 1 Topic 4 - SL QuestionsDocument2 pagesPaper 1 Topic 4 - SL QuestionsKrish HingoraniNo ratings yet
- Avaya Contact Center Select - GuideDocument20 pagesAvaya Contact Center Select - GuideManmeet ShandilyaNo ratings yet
- Search EngineDocument42 pagesSearch EngineiqraNo ratings yet
- G8 Final Term 2 Revision Sheet (21-22)Document10 pagesG8 Final Term 2 Revision Sheet (21-22)Hala HassanNo ratings yet
- .5 Computer Teaching StrategiesDocument40 pages.5 Computer Teaching StrategiesELIZABETH GRACE AMADORNo ratings yet
- Paper Supply ChainDocument20 pagesPaper Supply ChainDago CastilloNo ratings yet
- CS10-8L: Computer Programming Laboratory Machine Problem #4: Parking Fee CalculationDocument4 pagesCS10-8L: Computer Programming Laboratory Machine Problem #4: Parking Fee Calculationjian cool dudeNo ratings yet