You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5807)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (842)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Hypothesis Testing: An Intuitive Guide for Making Data Driven DecisionsFrom EverandHypothesis Testing: An Intuitive Guide for Making Data Driven DecisionsNo ratings yet
- Aiep S3Document4 pagesAiep S3Jerson AlexisNo ratings yet
- Face Your Fears: A Proven Plan to Beat Anxiety, Panic, Phobias, and ObsessionsFrom EverandFace Your Fears: A Proven Plan to Beat Anxiety, Panic, Phobias, and ObsessionsRating: 5 out of 5 stars5/5 (1)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Brown Chapter 2Document14 pagesBrown Chapter 2Maria ElorriagaNo ratings yet
- T He Molder of Learnings and Values: Activity C C 1.1Document5 pagesT He Molder of Learnings and Values: Activity C C 1.1Yma Losabio100% (2)
- Multivariate Analysis – The Simplest Guide in the Universe: Bite-Size Stats, #6From EverandMultivariate Analysis – The Simplest Guide in the Universe: Bite-Size Stats, #6No ratings yet
- Quantitative and Statistical Research Methods: From Hypothesis to ResultsFrom EverandQuantitative and Statistical Research Methods: From Hypothesis to ResultsRating: 2 out of 5 stars2/5 (1)
- The Clinician's Guide to Anxiety Sensitivity Treatment and AssessmentFrom EverandThe Clinician's Guide to Anxiety Sensitivity Treatment and AssessmentJasper SmitsNo ratings yet
- Pep Habilidades SocialesDocument7 pagesPep Habilidades SocialesTata TuckerNo ratings yet
- Schaum's Easy Outline of Probability and Statistics, Revised EditionFrom EverandSchaum's Easy Outline of Probability and Statistics, Revised EditionNo ratings yet
- Probability with Permutations: An Introduction To Probability And CombinationsFrom EverandProbability with Permutations: An Introduction To Probability And CombinationsNo ratings yet
- Concise Biostatistical Principles & Concepts: Guidelines for Clinical and Biomedical ResearchersFrom EverandConcise Biostatistical Principles & Concepts: Guidelines for Clinical and Biomedical ResearchersNo ratings yet
- A Joosr Guide to... Superforecasting by Philip Tetlock and Dan Gardner: The Art and Science of PredictionFrom EverandA Joosr Guide to... Superforecasting by Philip Tetlock and Dan Gardner: The Art and Science of PredictionNo ratings yet
- BEWARE OF THE MAN WITH ONLY ONE RELIGIOUS BOOK!: He is Incapable of Knowing the TruthFrom EverandBEWARE OF THE MAN WITH ONLY ONE RELIGIOUS BOOK!: He is Incapable of Knowing the TruthNo ratings yet
- Cognitive Errors and Diagnostic Mistakes: A Case-Based Guide to Critical Thinking in MedicineFrom EverandCognitive Errors and Diagnostic Mistakes: A Case-Based Guide to Critical Thinking in MedicineNo ratings yet
- Critical Thinking: Inductive and Deductive Reasoning ExplainedFrom EverandCritical Thinking: Inductive and Deductive Reasoning ExplainedRating: 4.5 out of 5 stars4.5/5 (6)
- Decision Making: A Practical Approach to Effective Decision Making (Mastering Critical Thinking and Problem-solving for Enhanced Productivity)From EverandDecision Making: A Practical Approach to Effective Decision Making (Mastering Critical Thinking and Problem-solving for Enhanced Productivity)No ratings yet
- The Theory of Evolution is a Result of Erroneous ExtrapolationFrom EverandThe Theory of Evolution is a Result of Erroneous ExtrapolationNo ratings yet
- Applications of Hypothesis Testing for Environmental ScienceFrom EverandApplications of Hypothesis Testing for Environmental ScienceNo ratings yet
- Handbook of Sexual Assault and Sexual Assault PreventionFrom EverandHandbook of Sexual Assault and Sexual Assault PreventionNo ratings yet
- Outsmart Your Brain: Identify and Control Unconscious Judgments, Protect Yourself From Exploitation, and Make Better Decisions The Psychology of Bias, Distortion and IrrationalityFrom EverandOutsmart Your Brain: Identify and Control Unconscious Judgments, Protect Yourself From Exploitation, and Make Better Decisions The Psychology of Bias, Distortion and IrrationalityRating: 4 out of 5 stars4/5 (7)
- Outsmart Your Brain: Mental DIscipline, #4From EverandOutsmart Your Brain: Mental DIscipline, #4Rating: 2 out of 5 stars2/5 (1)
- Summary: The Irrational Economist: Review and Analysis of Erwann Michel-Kerjan and Paul Slovic's BookFrom EverandSummary: The Irrational Economist: Review and Analysis of Erwann Michel-Kerjan and Paul Slovic's BookNo ratings yet
- Summary of How Not To Be Wrong: by Jordan Ellenberg | Includes AnalysisFrom EverandSummary of How Not To Be Wrong: by Jordan Ellenberg | Includes AnalysisNo ratings yet
- Summary of How Not To Be Wrong: by Jordan Ellenberg | Includes AnalysisFrom EverandSummary of How Not To Be Wrong: by Jordan Ellenberg | Includes AnalysisNo ratings yet
- The Liar's Non-Paradox: Why Liar Sentences Present No Problems for the Concept of TruthFrom EverandThe Liar's Non-Paradox: Why Liar Sentences Present No Problems for the Concept of TruthNo ratings yet
- Immunohematology and Transfusion Medicine: A Case Study ApproachFrom EverandImmunohematology and Transfusion Medicine: A Case Study ApproachNo ratings yet
- Correlation Is Not Causation: Bite-Size Stats, #3From EverandCorrelation Is Not Causation: Bite-Size Stats, #3Rating: 5 out of 5 stars5/5 (1)
- Statistics: 1,001 Practice Problems For Dummies (+ Free Online Practice)From EverandStatistics: 1,001 Practice Problems For Dummies (+ Free Online Practice)Rating: 3 out of 5 stars3/5 (1)
- Phase I Oncology Drug DevelopmentFrom EverandPhase I Oncology Drug DevelopmentTimothy A. YapNo ratings yet
- Fundamental Statistical Principles for the Neurobiologist: A Survival GuideFrom EverandFundamental Statistical Principles for the Neurobiologist: A Survival GuideRating: 5 out of 5 stars5/5 (1)
- LAC Plan: Phase Activities Persons Involve Time Frame Resources Success Indicator Fund Source of FundDocument1 pageLAC Plan: Phase Activities Persons Involve Time Frame Resources Success Indicator Fund Source of FundShring HighbNo ratings yet
- Atividade 2.1Document2 pagesAtividade 2.1Denise Ap. Siqueira e SilvaNo ratings yet
- PROPUESTA DE FORMATO DE RUBRICA AngieDocument1 pagePROPUESTA DE FORMATO DE RUBRICA AngieangieNo ratings yet
- Language Partner and Affective FiltersDocument12 pagesLanguage Partner and Affective FiltersElly SipayungNo ratings yet
- Rpms Kra CoverDocument22 pagesRpms Kra CoverClark Vergara Cabaral100% (6)
- Lesson Plan Inspectie Grad 2 Clasa IIIDocument2 pagesLesson Plan Inspectie Grad 2 Clasa IIIOlivian DuleaNo ratings yet
- Semana 1 TCCDocument20 pagesSemana 1 TCCmauro raul obregon moscolNo ratings yet
- RZL110 SYLLABUS REVISED Q21920 NewDocument5 pagesRZL110 SYLLABUS REVISED Q21920 NewJustin ViberNo ratings yet
- Programac. Inglés 1ero AvanzDocument6 pagesProgramac. Inglés 1ero AvanzsandyNo ratings yet
- Qué Es La Psicología de La PersonalidadDocument5 pagesQué Es La Psicología de La Personalidad11 MA Fabiana GalavisNo ratings yet
- MIDTERMDocument6 pagesMIDTERMLiana XudabaxshyanNo ratings yet
- CONCEPTO DE DIAGNOSTICO PSICOPEDAGOGICO de La Vida DiariaDocument4 pagesCONCEPTO DE DIAGNOSTICO PSICOPEDAGOGICO de La Vida DiariaalexNo ratings yet
- Impulsar La Participacion en El AulaDocument10 pagesImpulsar La Participacion en El AulaauitelNo ratings yet
- Agenda Sesión 14Document1 pageAgenda Sesión 14Yadira CordovaNo ratings yet
- Bac 205 Aeb 403 M.A Course OutlineDocument2 pagesBac 205 Aeb 403 M.A Course OutlineKelvin mwaiNo ratings yet
- Plan Diagnóstico y Refuerzo 2022 - 2023 YoutubeDocument4 pagesPlan Diagnóstico y Refuerzo 2022 - 2023 Youtubevespertinos vesperNo ratings yet
- Analisis de Los Paragrafos 34 y 35 de SeDocument14 pagesAnalisis de Los Paragrafos 34 y 35 de SecristianNo ratings yet
- Programas Introducción Al Turismo 2014Document11 pagesProgramas Introducción Al Turismo 2014Alejandra CubillaNo ratings yet
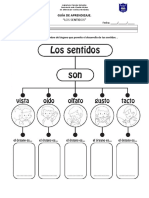
- Guía SentidosDocument2 pagesGuía SentidosVerónica Lorena Hernández González100% (1)
- Salvemos Al MundoDocument2 pagesSalvemos Al MundoPablo Andrés ReyesNo ratings yet
- Child and Adolescent Learners and Learning PrincipleDocument3 pagesChild and Adolescent Learners and Learning PrincipleAshley Kezia Lopez0% (1)
- Foro 2parcialDocument4 pagesForo 2parcialAngel miguel Reyes100% (1)
- FRANCÉS A1 Guia Docente 2018 19Document6 pagesFRANCÉS A1 Guia Docente 2018 19Javier Alonso PancorboNo ratings yet
- 2 - Epistemología - Esther Díaz y A. ComteDocument27 pages2 - Epistemología - Esther Díaz y A. ComteRodrigo LuquiNo ratings yet
- Tarea 1Document14 pagesTarea 1Anonymous Yi1e0k0lndNo ratings yet
- Historia de La Psicologia - Trabajo Colaborativo - Fase 3Document4 pagesHistoria de La Psicologia - Trabajo Colaborativo - Fase 3Edwin GonzalezNo ratings yet