You might also like
- Pseudo First Order KinetikDocument5 pagesPseudo First Order Kinetikmaulida rahmiNo ratings yet
- Fuzzy C-Means: Simbol Keterangan LangkahDocument40 pagesFuzzy C-Means: Simbol Keterangan LangkahIksan AccelcifNo ratings yet
- Método Simpson: Con Cinco Cifras N: 100Document1 pageMétodo Simpson: Con Cinco Cifras N: 100Taall QuellNo ratings yet
- Fuzzy C-Means: Simbol Keterangan LangkahDocument34 pagesFuzzy C-Means: Simbol Keterangan LangkahIksan AccelcifNo ratings yet
- Credit Card Fraud Detection With CNN 99 AccuracyDocument12 pagesCredit Card Fraud Detection With CNN 99 AccuracyJadeNo ratings yet
- Normal Distribution with Average and Standard DeviationDocument8 pagesNormal Distribution with Average and Standard DeviationAdNo ratings yet
- Problema Termodinamicay GraficoDocument16 pagesProblema Termodinamicay GraficoDaniel Hernandez AguilarNo ratings yet
- 2 Drandom WalkDocument68 pages2 Drandom WalkIrina INo ratings yet
- Grafikon 3Document3 pagesGrafikon 3Pavle KopčićNo ratings yet
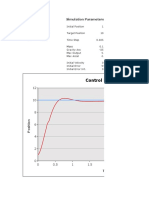
- PID Control SimulationDocument14 pagesPID Control SimulationnaeyensNo ratings yet
- Generate Unifrom DistributionDocument11 pagesGenerate Unifrom Distributionajaykum14No ratings yet
- Respons Simpangan Terhadap Waktu: Data Dan Nilai KonstantaDocument6 pagesRespons Simpangan Terhadap Waktu: Data Dan Nilai KonstantaFelix Reyfaldi L.ANo ratings yet
- Fungsi TangkiDocument3 pagesFungsi TangkiReza MaulanaNo ratings yet
- Me 321Document2 pagesMe 321Bakkashreya SriNo ratings yet
- Worshop Matériaux CompositesDocument42 pagesWorshop Matériaux CompositesInnov'Action ProdNo ratings yet
- 7752 - Mortality FinalDocument4 pages7752 - Mortality FinalShailendra ShresthaNo ratings yet
- Coordenadas de La Cerchas Grupo PeresDocument31 pagesCoordenadas de La Cerchas Grupo PeresCeci SaavedraNo ratings yet
- 9 8-TreybalDocument12 pages9 8-Treybalthings 21No ratings yet
- WERTYUIODocument3 pagesWERTYUIOAngelo Torres TerrerosNo ratings yet
- Formato Anderson DarlingDocument12 pagesFormato Anderson DarlingjaymNo ratings yet
- Tugas Teknik Reaksi Kimia (TRK) Lanjut: MARET 2019Document9 pagesTugas Teknik Reaksi Kimia (TRK) Lanjut: MARET 2019Andre Fahriz Perdana HarahapNo ratings yet
- Unidad 3Document48 pagesUnidad 3Luis Diego Peralta PerezNo ratings yet
- Exercise 3A - Supplier Selection 1Document4 pagesExercise 3A - Supplier Selection 1Sanket Sourav BalNo ratings yet
- 21 - Eigenvalue Mode Using RitzDocument5 pages21 - Eigenvalue Mode Using RitzenatagoeNo ratings yet
- Black-Scholes Example.Document3 pagesBlack-Scholes Example.Diaa eddin saeedNo ratings yet
- Traffic Chracteristics of Different Zones in MilanDocument7 pagesTraffic Chracteristics of Different Zones in MilanUdit Paul TurjoNo ratings yet
- 5 C-V (TT) - 090622Document52 pages5 C-V (TT) - 090622Tuấn LvNo ratings yet
- Runge 3Document11 pagesRunge 3xllllccNo ratings yet
- Aula 2 Mrp250Document123 pagesAula 2 Mrp250Matheus MacedoNo ratings yet
- Steams IDocument40 pagesSteams ILoading YuriNo ratings yet
- Specific Volume, M /KG Internal Energy, KJ/KG Temp. Press. Sat. Liquid Evap. Sat. Vapor Sat. Liquid Evap. Sat. Vapor (C) (Kpa)Document6 pagesSpecific Volume, M /KG Internal Energy, KJ/KG Temp. Press. Sat. Liquid Evap. Sat. Vapor Sat. Liquid Evap. Sat. Vapor (C) (Kpa)sidhartha dasNo ratings yet
- Exercìcio 1 TraopézioDocument2 pagesExercìcio 1 TraopézioJoão RochaNo ratings yet
- Tugas Getaran - Herry Zuwiardi - D1011191129Document5 pagesTugas Getaran - Herry Zuwiardi - D1011191129Herry ZuwiardiNo ratings yet
- LM6 alloy load-deflection dataDocument4 pagesLM6 alloy load-deflection dataHareesh R IyerNo ratings yet
- Regression analysis of home value factorsDocument23 pagesRegression analysis of home value factorsshubhanjali kesharwaniNo ratings yet
- Distribusi NormalDocument7 pagesDistribusi NormalTiyas AdjiNo ratings yet
- Chart Title Chart TitleDocument2 pagesChart Title Chart TitlesaraNo ratings yet
- Mean, M Standard Deviation, S X: Graph LimitsDocument11 pagesMean, M Standard Deviation, S X: Graph LimitsNADZIRUL NAIM HAYADINNo ratings yet
- Ejercicios 2 Uda Modulo 22Document30 pagesEjercicios 2 Uda Modulo 22matlrNo ratings yet
- 2017 2018 2017 2018 Comparacion 2017Document5 pages2017 2018 2017 2018 Comparacion 2017Diego FalconNo ratings yet
- CetnarskiDocument630 pagesCetnarskimkNo ratings yet
- Lennard Jones Potenti Al Curve For Water: Zoomed ViewDocument22 pagesLennard Jones Potenti Al Curve For Water: Zoomed ViewVipin bhardwajNo ratings yet
- Simplex AirfoilDocument2 pagesSimplex AirfoilasadNo ratings yet
- Último EjercicioDocument114 pagesÚltimo EjercicioElda Torres CenturionNo ratings yet
- P1 Ruiz SusanDocument19 pagesP1 Ruiz SusanSusan RuizNo ratings yet
- InventariosDocument7 pagesInventariosAndres LoperaNo ratings yet
- Stress Strain 2Document1 pageStress Strain 2Shivam DixitNo ratings yet
- D H Arcos: Sen RII R Sen D RDocument8 pagesD H Arcos: Sen RII R Sen D RMamani Loza Neyber HenryNo ratings yet
- Si@) Z-Z (Ci (Z) - in In: Exp0Nzwi"Tal Integral Related FunctionsDocument6 pagesSi@) Z-Z (Ci (Z) - in In: Exp0Nzwi"Tal Integral Related FunctionsttNo ratings yet
- TareaDocument12 pagesTareaAbrahan MaciasNo ratings yet
- Mukhlis - Tugas Ekonomterika RegresiDocument5 pagesMukhlis - Tugas Ekonomterika Regresi2210103028.mukhlisNo ratings yet
- Analyzing Speed, Time and Distance DataDocument8 pagesAnalyzing Speed, Time and Distance DataAaron Hernandez JimenezNo ratings yet
- RS-50 (R442A) : Thermodynamic TablesDocument21 pagesRS-50 (R442A) : Thermodynamic Tablesjean-sebastien CordierNo ratings yet
- Vjeºba - GrafikoniDocument7 pagesVjeºba - GrafikoniCORSOKAK12No ratings yet
- EDM VikorDocument8 pagesEDM VikorgowrimalleshNo ratings yet
- TR5 ExcelDocument10 pagesTR5 ExcelJoshua Paul Zulueta SarigumbaNo ratings yet
- Data w1 w2Document12 pagesData w1 w2Andi PrasNo ratings yet
- Nama Rivandi Wibisana NPM 1406576162Document2 pagesNama Rivandi Wibisana NPM 1406576162aingNo ratings yet
- 3 SVM - Jupyter NotebookDocument4 pages3 SVM - Jupyter Notebookvenkatesh mNo ratings yet
- 6 XG Boost - Jupyter NotebookDocument3 pages6 XG Boost - Jupyter Notebookvenkatesh m100% (1)
- 1 Basics of PythonDocument6 pages1 Basics of Pythonvenkatesh mNo ratings yet
- 2 MLR New - Jupyter NotebookDocument3 pages2 MLR New - Jupyter Notebookvenkatesh mNo ratings yet
- 5 Random Forest - Jupyter NotebookDocument2 pages5 Random Forest - Jupyter Notebookvenkatesh mNo ratings yet
- 1 KNN - Jupyter NotebookDocument3 pages1 KNN - Jupyter Notebookvenkatesh mNo ratings yet
- 1 Simple Linear RegressionDocument9 pages1 Simple Linear Regressionvenkatesh mNo ratings yet
- Gender Classification Using Genetic Feature SelectionDocument43 pagesGender Classification Using Genetic Feature SelectionSaket JhaNo ratings yet
- Supervision of Ethylene Propylene Diene M-Class (EPDM) Rubber Vulcanization and Recovery Processes Using Attenuated Total Reflection Fourier Transform Infrared (ATR FT-IR) Spectroscopy and Multivariate AnalysisDocument12 pagesSupervision of Ethylene Propylene Diene M-Class (EPDM) Rubber Vulcanization and Recovery Processes Using Attenuated Total Reflection Fourier Transform Infrared (ATR FT-IR) Spectroscopy and Multivariate AnalysisFairmont Ind Quality DivisionNo ratings yet
- Weightlifting Performance Is Related ToDocument7 pagesWeightlifting Performance Is Related ToH BarbosaNo ratings yet
- Scales Construction For Consumers' Personal ValuesDocument493 pagesScales Construction For Consumers' Personal ValuesAnonymous 01wDu2No ratings yet
- Model-Based Avionic Prognostic Reasoner (MAPR) PDFDocument9 pagesModel-Based Avionic Prognostic Reasoner (MAPR) PDFlalith.shankar7971No ratings yet
- Article EJIM50603 Franco2Document26 pagesArticle EJIM50603 Franco2rizam aliNo ratings yet
- Approaching (Almost) Any Machine Learning Problem - Abhishek Thakur - No Free HunchDocument22 pagesApproaching (Almost) Any Machine Learning Problem - Abhishek Thakur - No Free HunchpepeNo ratings yet
- Clustering An African Hairstyle Dataset Using Pca and K-MeansDocument11 pagesClustering An African Hairstyle Dataset Using Pca and K-MeansJames MorenoNo ratings yet
- #2. Exploring Value of Project Management PDFDocument16 pages#2. Exploring Value of Project Management PDFreffi heldayaniNo ratings yet
- CS F415 Data Mining Data PreprocessingDocument103 pagesCS F415 Data Mining Data PreprocessingShubhra BhatotiaNo ratings yet
- DTREGDocument395 pagesDTREGyxiefacebookNo ratings yet
- NOREVA - Normalization and Evaluation of MS-based Metabolomics DataDocument9 pagesNOREVA - Normalization and Evaluation of MS-based Metabolomics Dataciborg1978No ratings yet
- An Analysis On The Determinants of Quality of Work Life and Employee Turnover Among The Nurses of Private Hospitals in CoimbatoreDocument13 pagesAn Analysis On The Determinants of Quality of Work Life and Employee Turnover Among The Nurses of Private Hospitals in CoimbatoreIAEME PublicationNo ratings yet
- 2004 JQT Woodall Et AlDocument12 pages2004 JQT Woodall Et AlWei WangNo ratings yet
- Barry Oreck 2004 - The Arts and Professional Development of Teachers, A Study of Teacher's Attitudes Toward and Use of The Arts in TeachingDocument15 pagesBarry Oreck 2004 - The Arts and Professional Development of Teachers, A Study of Teacher's Attitudes Toward and Use of The Arts in Teachingluiz carvalhoNo ratings yet
- Notes5 PDFDocument11 pagesNotes5 PDFsashumaruNo ratings yet
- Relations Between The Functions of Autobiographical Memory and Psychological WellbeingDocument12 pagesRelations Between The Functions of Autobiographical Memory and Psychological WellbeingJasonNo ratings yet
- Risk MeasurementDocument52 pagesRisk MeasurementBhaskkar SinhaNo ratings yet
- Ice Cream ResearchDocument306 pagesIce Cream ResearchHenry Osineke100% (1)
- Modern Psychometrics With R - Patrick MairDocument464 pagesModern Psychometrics With R - Patrick MairRicardo Narváez89% (9)
- Antifungal Activity of A Common Himalayan Foliose Lichen Parmotrema Tinctorum (Despr. Ex Nyl.) Hale.Document5 pagesAntifungal Activity of A Common Himalayan Foliose Lichen Parmotrema Tinctorum (Despr. Ex Nyl.) Hale.Himanshu RaiNo ratings yet
- Chapter 4 - Dimension Reduction: Data Mining For Business IntelligenceDocument24 pagesChapter 4 - Dimension Reduction: Data Mining For Business IntelligencejayNo ratings yet
- An Effective Framework For Skyline Queries Using PCADocument5 pagesAn Effective Framework For Skyline Queries Using PCAAbhishek MishraNo ratings yet
- ML Basics 02 (Statistics)Document438 pagesML Basics 02 (Statistics)Rishabh chaudhary100% (6)
- Food Chemistry: A A A BDocument10 pagesFood Chemistry: A A A BOSWALDO ALEXIS VARGAS VALENCIANo ratings yet
- Sentiment Analysis of Mobile ReviewsDocument73 pagesSentiment Analysis of Mobile ReviewsprajwalaNo ratings yet
- Introduction To Data MiningDocument643 pagesIntroduction To Data MiningDong-gu Jeong100% (1)
- 1 Descriptive StatisticsDocument20 pages1 Descriptive StatisticsNittin BaruNo ratings yet
- Change Detection TechniquesDocument21 pagesChange Detection TechniquesPrasadNo ratings yet
- CH 11Document34 pagesCH 11yashwanthr3No ratings yet