68%(28)68% found this document useful (28 votes)
256K views14 pagesGhozali 2018
fasf
Uploaded by
royhan bayuCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF or read online on Scribd
68%(28)68% found this document useful (28 votes)
256K views14 pagesGhozali 2018
fasf
Uploaded by
royhan bayuCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF or read online on Scribd
IBM" SPSS" Statistics
Version 25
ISBN: 979-704-015-1
CET Os Ce nc
YAU CCU VEEL:
SY
Ty =e a)
eT
Prof.H.lmam Ghozali, M.Com, Ph.D, CA, Akt
Fakultas Ekonomika dan Bisnis Universitas Diponegoro Semarang
ISBN: 979-704-015-1
PEE ta a Ui estes Ua)
Prof.H.Imam Ghozali, M.Com, Ph.D, CA
APLIKASI ANALISIS MULTIVARIATE Dengan Program IBM SPSS 25 Edisi 9
ISBN : 979.704.0151
@ 2018 Badan Penerbit - Undip
Xx, 490 hal, 160 X 240 mm
Lay-out / Setting : Abadi Tejokusumo
Desain Cover : Abadi Tejokusumo
Hak Cipta dilindungi oleh Undang-Undang
Dilarang mengutip, memperbanyak, dan mengedarkan sebagian atau seluruh isi buku ini tanpa izin
tertulis dari penerbit.
Cetakan! —: Juli 2001
Cetakan II gustus 2002
Cetakan Ill > Januari 2005
Cetakan IV: Oktober 2006
April 2007
April 2009
CetakanV April 2011
Cetakan VI
Cetakan VII
Cetakan VIII :
Cetakan IX: Februari 2018 y atte
Kutipan Pasal 72 : —
Sanksi Pelanggaran-Undang-Undang Hak Cipta
(Undang-Undang No. 19 Tahun 2002)
1. _Barang siapa dengan sengaja dan tanpa hak melakukan perbuatan sebagaimana dimaksud
dalam Pasal 2 ayat (1) dipidana penjara masing-masing paling singkat 1 (satu) bulan dan/atau
denda paling sedikit Rp. 1.000.000,00 (satu juta rupiah), atau pidana penjara paling lama 7
(tujuh) tahun dan /atau denda paling banyak Rp. 5.000.000.000,00 (lima miliar rupiah).
Barang siapa dengan sengaja menyiarkan, memamerkan, mengedarkan, atau menjual kepada
umum suatu ciptaan atau barang hasil pelanggaran Hak Clpta atau Hak Terkait sebagaimana
dimaksud pada ayat (1) dipidana dengan pidana penjara paling lama 5 (lima) tahun dan/atau
denda paling banyak Rp. 500.000.000,00 (lima ratus juta rupiah).
(a
Jika model regresi transformasi anda kalikan kedua sisi dengan Sales
maka akan diperoleh regresi yang mirip dengan regresi awal RA ide
sedikit perbedaan nilai slope atau koefisien Sales. Sedangkan standar
error slope koefisien Sales pada regresi transformasi lebih kecil
(se=0.007) dibandingkan regresi awal (se=0,008). Jadi regresi OLS
awal memiliki standar error yang overestimate. Seperti telah dijelaskan
sebelumnya bahwa regresi dengan heteroskedastisitas, OLS estimator
dari standar error akan bias.
7.4 Uji Normalitas
Uji normalitas bertujuan_ untuk menguji apakah dalam model
regresi, variabel pengganggu atau residual iliki_ distribusi
normal. Seperti diketahui bahwa uji t dan F mengasumsikan bahwa
jilai residual mengikuti distribusi normal. Kalau asumsi ini dilanggar
maka uji statistik menjadi tidak valid untuk jumlah sampel kecil_ Ada
dua cara untuk mendeteksi_apakah residual berdistribusi normal atau
tidak yaitu dengan analisis grafik dan uji statistik.
ae
a. Analisis Grafik
Salah satu cara termudah untuk melihat nomalitas residual adalah
Ce aoa Ne
ObSCrV: engan distribusi yang miendekati distribusi normal. Namun
demikian hanya dengan melihat histogram hal ini dapat menyesatkan
khususnya untuk jumlah sampel yang kecil. Metode yang lebih handal
adalah dengan melihat normal probability plot yang membandingkan
distribusi kumulatif dari distribusi_normal. Distribusi akan
Mmembentuk satu garis lurus diagonal, dan ploting data residual akan
normal, maka garis yang menggambarkan data sesungguhnya akan
mengikuti garis diagonalnya.
Cara menguji normalitas residual dengan analisis grafik lewat SPSS
- dapat dilakukan dengan langkah sebagai berikut:
a, Lakukan regresi dengan persamaan INCOME={(S
WEALTH,SAVING)
~b. Lanjutkan dengan menekan tombol Plots hingga di layar tam
tampilan windows
IZE,EARNS
pak
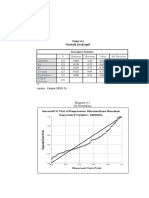
3.3 Data Outlier
Setelah melakukan transformasi untuk mendapatkan normalitas data
langkah screening berikutnya yang harus dilakukan adalah mendetekg;
adanya data outlier. Outlier adalah kasus atau data yang memilikj
karakteristik unik yang terlihat sangat berbeda jauh dari observasj-
observasi lainnya dan muncul dalam bentuk nilai ekstrim baik untuk
sebuah variabel tunggal atau variabel kombinasi. Ada empat penyebab
timbulnya data outlier: (1) kesalahan dalam meng-entri data, (2) gagal
menspesifikasi adanya missing value dalam program komputer, (3)
outlier bukan merupakan anggota populasi yang kita ambil sebagai
sampel, dan (4) outlier berasal dari populasi yang kita ambil sebagai
sampel, tetapi distribusi dari variabel dalam populasi tersebut memiliki
nilai ekstrim dan tidak terdistribusi secara normal.
Deteksi terhadap univariate outlier dapat dilakukan dengan
menentukan nilai batas yang akan dikategorikan sebagai data outlier
yaitu dengan cara mengkonversi nilai data kedalam skor standardized
atau yang biasa disebut z-score, yang memiliki nilai means (rata-rata)
sama dengan nol dan standar deviasi sama dengan satu. Menurut Hair
(1998) untuk kasus sampel kecil (kurang dari 80), maka standar skor
dengan nilai > 2.5 dinyatakan outlier. Untuk sampel besar standar skor
dinyatakan outlier jika nilainya pada kisaran 3 sampai 4. Jika standar
skor tidak digunakan, maka kita dapat menentukan data outlier jika
data tersebut nilainya lebih beasr dari 2.5 standar deviasi atau antara 3
sampai 4 standar deviasi tergantung dari besarnya sampel.
Data yang akan kita deteksi outliernya adalah data yang sudah kita
screening normalitasnya, jadi dalam hal ini adalah variabel SQREARNS
dan SQRWEALLT. Berikut ini cara mendeteksi outlier.
Langkah Anali
a. Dari menu utama SPSS pilih Analyze, lalu Descriptive Statistic
dan kemudian Descriptive.
b. Tampak dilayar tampilan windows Descriptive
APLIKASI ANALISIS MULTIVARIATE Dengan Program IBM SPSS 25 Edisi 9
Di tatis tifk \
6. Pilih Statistik dan aktifkan Durbin-Watson (untuk menguji
apakah masih terjadi autokorelasi)
7. Abaikan lainnya dan tekan Ok
8. Hasil Output SPSS
Model Summary?
Std. Error of the
Model R R Square _| Adjusted R Square|___Estimate Durbin-Watson
1 924" 853; 846 04976 1.774
a. Predictors: (Constant), LnUt@
b. Dependent Variable: LiHWIt@
ANOVA’
(Model Sum of Squares | df_[ Mean Square F Sig.
1 Regression 302, 1 302] 121.995] .000"
Residual 052| 21 002|
Total 354] 22
‘a. Predictors: (Constant), LnUt@
b. Dependent Variable: LnHWIt@
Coefficients*
Standardized
Unstandardized Coefficients | _ Coefficients
Model B ‘Std. Error Beta t Sig.
1 (Constant) 3.203) 091 35.327, 000)
LnUt@ “1.467, 133 -924] -11.045 000)
@. Dependent Variable: LnHWIt@
Membandingkan hasil regresi persamaan asli sebelum ada
transformasi dan hasil regresi setelah transformasi ternyata dapat
dibandingkan (comparable). Hanya bedanya terletak pada nilai Durbin-
Watson. Pada persamaan asli nilai Durbin Watson sebesar 0.911 dan
autokorelasi positif, sedangkan dengan persamaan regresi
terjadi
transformasi nilai Durbin Watson sebesar 1.774 yang berarti sudah
tidak ada lagi autokorelasi Re?
7.3 Uji Heteroskedas
Uji nee ae eal a dalam model
regresi terjadi Ketidaksamaan variance dari residual satu pensar"
pe variance dari residual satu pengamatan
€ pengamatan lain tetap, maka disebut Homoskedastisitas dan
jika berbeda disebut Heteroskedastisitas, Model regresi_yang baik
as atau tidak terjadi ‘oskesdatisitas.
nn mengandung situas! heteroskesdatisitas
kili bebagai ukuran (kecil,
Kel
karena data ini menghimpun data yang mewal
sedang dan besar).
UJI ASUMSI KLASIK 137
Jikanilai k antara 100 dan 1000, maka terdapat multikoloniearitas
moderat ke kuat. Jika k > 1000, maka terdapat multikolonieritas
sangat kuat. Dengan cara lain jika Cl (= k) nilainya antara 10
dan 30 terdapat multikoloniearitas moderat ke kuat, jika nilai CI
> 30 terdapat multikoloniearitas sangat kuat.
Cara mengobati Multikoloniearitas
a. Menggabungkan data crossection dan time series (pooling
data)
b. Keluarkan satu atau lebih variabel independen yang
mempunyai korelasi tinggi dari model regresi dan
identifikasikan variabel independen lainnya untuk membantu
prediksi.
c. Transformasi variabel merupakan salah satu cara mengurangi
hubungan linear di antara variabel independen. Transformasi
dapat dilakukan dalam bentuk logaritma natural dan bentuk
* first difference atau delta. Caranya
Yt=bl + b2 X2t+b3 X3t+ut .... i wae OD)
Yt-1 =bl + b2 X2t-1 + b3 X3t-1 + ut-1 (2)
Kurangkan persamaan (2) dari (1) didapat first difference
Yt—Yt-1 = b2(X2t — X2t-1) + b3(X3t-X3t-1) + vt.. (3)
d. Gunakan model dengan variabel independen yang
hanya semata-mata untuk
mempunyai_ korelasi tinggi
prediksi (jangan mencoba untuk menginterpretasikan
koefisien regresinya).
e, Gunakan metodeanalisis yang lebih canggih seperti Bayesian
regression atau dalam kasus khusus ridge regression
7.2 Uji Autokorelasi
Uji autokorelasi_bertujuan_menguji apakah dalam model regresi
linear ada Korelasi antara kesalahan pengganggu pada periode t deng
esalahan pengganggu pada periode t-1 (sebelumnya). ika terjadi
korelasi, maka dinamakan ada problem autokorelasi. Autokorelasi
muncul karena observasi yang berurutan sepanjang waktu berkaitan satu
sama lainnya. Masalah ini timbul karena residual (kesalahan penganggu)
tidak bebas dari satu observasi ke observasi lainnya. Hal ini sering
UJI ASUMSI KLASIK Mt
ANALISIS REGRESI
6.1 Pendahuluan
Istilah “regresi” pertama kali diperkenalkan oleh Sir Francis Galton
pada tahun 1886. Galton menemukan adanya tendensi bahwa orang tua
yang memiliki tubuh tinggi, memiliki anak-anak yang tinggi pula dan
orang tua yang pendek memiliki anak-anak yang pendek pula. Kendati
demikian, ia mengamati ada kecenderungan bahwa tinggi anak bergerak
menuju rata-rata tinggi populasi secara keseluruhan. Dengan kata lain
ketinggian anak yang amat tinggi atau orang tua yang amat pendek
cenderung bergerak ke arah rata-rata tinggi populasi. Inilah yang disebut
hukum Galton mengenai regresi universal. Dalam bahasa Galton ia
menyebutnya sebagai regresi menuju mediokritas (Maddala, 1992).
Interpretasi modern mengenai regresi agak berlainan dengan regresi
versi Galton. Secara umum , analisis regresi pada dasarnya adalah studi
mengenai ketergantungan variabel dependen (terikat) dengan satu atau
lebih variabel independen (variabel penjelas/bebas), dengan tujuan
untuk mengestimasi dan/atau memprediksi rata-rata populasi atau nilai
rata-rata variabel dependen berdasarkan nilai variabel independen yang
diketahui (Gujarati, 2003).
Hasil analisis regresi adalah berupa koefisien untuk masing-masing
variabel independen. Koefisien ini diperoleh dengan cara memprediksi
nilai variabel dependen dengan suatu persamaan. Koefisien regresi
dihitung dengan dua tujuan sekaligus: pertama, meminimumkan
penyimpangan antara nilai aktual dan nilai estimasi variabel dependen
berdasarkan data yang ada (Tabachnick, 1996).
6.2 Regresi vs Korelasi
Analisis korelasi_bertujuan_untuk_mengukur kekuatan_asosiasi
(habungan) linear_antara_dua variabel. Korelasi tidak menunjukkan
0 ES ee
_ ANALISIS REGRESI 95
hubungan _fungsional atau dengan kata lain analisis_korelasi tidak
membedakan antara variabel dependen dengan variabel inde enden.
~—Dalanranalisis regresi, selain mengukur kekuatan hubungan antara
dua variabel atau lebih, juga menunjukkan arah hubungan antara
variabel dependen dengan variabel independen. Variabel dependen
diasumsikan random/stokastik, yang berarti mempunyai distribusi
probabilistik. Variabel independen/bebas diasumsikan memiliki nilai
tetap (dalam pengambilan sampel yang berulang).
Teknik estimasi variabel dependen yang melandasi analisis regresi
disebut Ordinary Least Squares (pangkat kuadrat terkecil biasa). Metode
OLS diperkenalkan pertama kali oleh Carl Friedrich Gauss, seorang
ahli matematika dari Jerman. Inti metode OLS adalah mengestimasi
suatu garis regresi dengan jalan meminimalkan jumlah dari Ruadrat
kesalahan setiap observasi terhadap garis tersebut.
6.3 Asumsi Ordinary Least Squares
Menurut Gujarati (2003) asumsi utama yang mendasari model
regresi linear klasik dengan menggunakan model OLS adalah:
a.¥ Model regresi linear, artinya linear dalam parameter seperti
dalam persamaan di bawah ini: pororneme 90?
Yi=bl + b2 Xi+ui
b.“ Nilai X diasumsikan non-stokastik, artinya nilai X dianggap
tetap dalam sampel yang berulang.
c. Nilai rata-rata kesalahan adalah nol, atau E(ui/Xi) = 0.
d. Homoskedastisitas, artinya variance kesalahan sama untuk
vai “ESS setiap periode (Homo = sama, Skedastisitas = sebaran) dan
dinyatakan dalam bentuk matematis Var (ui/Xi) = 0
e. Tidak ada autokorelasi antar kesalahan (antara ui dan uj tidak
ada korelasi) atau secara matematis Cov (ui,uj/Xi,Xj) = 0.
f. Antara ui dan Xi saling bebas, sehingga Cov (ui/Xi) = 0.
g. Jumlah observasi, n, harus lebih besar daripada jumlah parameter
yang diestimasi (jumah variabel bebas).
h. Adanya variabilitas dalam nilai X, artinya nilai X harus berbeda.
i. Model regresi telah dispesifikasi secara benar. Dengan kata
lain tidak ada bias (kesalahan) spesifikasi dalam model yang
digunakan dalam analisis empirik.
j. Tidak ada multikolinearitas yang sempurna antar variabel bebas.
96 APLIKAS! ANALISIS MULTIVARIATE Dengan Program IBM SPSS 25 Edisi 9
re
6.4 Menilai Goodness of Fit Suatu Model
Ketepatan fungsi regresi sampel | dalam me ir nilai aktual dapat
diukur dari Goodness of fitnya. Secara statisti etidaknya
diukur dari ri nilai koefisien determinasi, nilai statistik F dan nilai statistik
disebut signifikan secara statistik apabila
knya a berada dalam daerah kritis (daerah dimana Ho ditolak).
Sebaliknya disebut tidak signifikan bila nilai uji statistiknya berada
dalam daerah dimana Ho diterima.
a. Koefisien Determinasi
Koefisien determinasi ( R*) pada intinya mengukur seberapa jauh
kemamy rangkan watiesi variabel d=penden-NITat
koefisien determinasi_adalah antara nol dan n satu. Nilai R? yang kec ke
berarti kemampuan variabel-variabel independen dalam menjelaskan
variasi variabel dependen amat terbatas. Nilai yang mendekati satu
berarti ti_variabel-variabel_independen_ _memberikan hampir semua
¢ emprediksi variasi_variabel
Secara umum. koefisien ‘determinasi untuk data silang
(crossection) relatif rendah karena adanya variasi yang besar antara
masing-masing pengamatan, sedangkan untuk data runtun waktu (time
series) biasanya mempunyai nilai Koefisien determinasi yang tinggi.
Satu hal yang perlu dicatat adalah masalah regresi lancung
(spurious regression). Insukindro (1998) menekankan bahwa koefisien
determinasi hanyalah salah satu dan bukan satu-satunya kriteria
memilih model yang baik. Alasannya bila suatu estimasi regresi linear
menghasilkan koefisien determinasi yang tinggi, tetapi tidak konsisten
dengan teori ekonomika yang dipilih oleh peneliti, atau tidak lolos dari
*uji asumsi klasik, maka model tersebut bukanlah model penaksir yang
baik dan seharusnya tidak dipilih menjadi model empirik.
Kelemahan mendasar penggunaan koefisien determinasi adalah
bias terhadap jumlah variabel independen aanE dimasukkan kedalam
model. Setiap tambahan_satu_vari; ei 2 ti
meningkat tidak perduli iabel_tersebut_berpengaruh secara
Signifikan terhadap _variabel_dependen. Oleh karena itu banyak
penelity menganjurkan untuk menggunakan nilai Adjusted R° pada
saat mengevaluasi mana model regresi terbaik, Tidak seperti R% nilai
Adjusted R? dapat naik atau turun apabila satu variabel independen
ditambahkan kedalam model.
Dalam kenyataan nilai adjusted R? dapat bernilai negatif, walaupun
yang dikehendaki harus bernilai positif. Menurut Gujarati (2003) jika
ANALISIS REGRESI
i A
97
Pada kotak Dependent isikan variabel INCOME
Pada kotak Independent isikan variabel SIZE, EARNS
WEALTH and SAVING
Pada kotak method pilih Enter
A baikan yar dan tekan Ok
h. - Hasil output
Koefisien Determinasi
Model Summary
Adjusted R Std. Error of the
Model R R Square Square Estimate
1 902" 814 807 2.456274
a. Predictors: (Constant), SIZE, EARNS, SAVING, WEALTH
Dari tampilan output SPSS model summary besarnya adjusted R?
adalah 0.807, hal ini berarti 80.7% variasi Income dapat dijelaskan oleh
variasi dari ke empat variabel independen SIZE, EARNS, WEALTH
dan SAVING. Sedangkan sisanya (100% - 80.7% = 19.3%) dijelaskan
oleh sebab sebab yang lain diluar model. — ~
Standar Error of estimate (SEE) sebesar 2.4563 ribu dolar. Makin
kecil nilai SEE akan membuat model regresi semakin tepat dalam
memprediksi variabel dependen. ’
Uji Signifikansi Simultan (Uji Statistik F)
ANOVA?
Model Sum of Squares_| df __|_Mean Square FE Sig.
1 Regression 2513.760 e 628.440 104.162 __.000°
Residual 573.162 95
Total 3086.922 99
a. Dependent Variable: INCOME
b. Predictors: (Constant), SIZE, EARNS, SAVING, WEALTH
60:
«
Dari uji ANOVA atau F test didapat nilai F hitung sebesar 104.162
dengan probabilitas 0.000. Karena probabilitas jauh lebih kecil dari 0.05,
maka model regresi dapat digunakan untuk memprediksi INCOME atau
dapat dikatakan bahwa SIZE, EARNS, WEALTH dan SAVING secara
bersama-sama berpengaruh terhadap INCOME.
Uji Signifikansi Parameter Individual (Uji Statistik t)
Untuk menginterpretasikan _koefisien _ variabel_ bebas
(independen) dapat menggunakan unstandardized coefficients maupun
‘standardized coefficients. s
é
;
é
dalam uji empiris didapat nilai adjusted R* negatif, maka nilai adjusted
R? dianggap bernilai nol. Secara matematis jika nilai R? = 1, maka
Adjusted R? = R? = | sedangkan jika nilai R? = 0, maka adjusted R?= (1
—k)n—k). Jika k > 1, maka adjusted R? akan bernilai negatif
b. Uji Signifikansi Keselurahan dari Regresi Sample (Uji Statistik
F)
Tidak seperti uji t yang menguji signifikansi koefisien parsial
regresi secara individu dengan uji hipotesis terpisah bahwa setiap setiap
koefiensn regresi sama dengan nol. Uji F menguji joint hipotesia bahwa
bl, b2 dan b3 secara bersama-sama sama dengan nol, atau :
1=b2 ‘bk = 0
b2 # bk #0
Ujihipotesis seperti ini dinamakan uji signifikansi secera keseluruhan
terhadap garis regresi yang diobservasi maupun estimasi, apakah Y
berhubngan linear terhadap X1, X2 dan X3. Apakah joint hipotesis dapat
diuji dengan signifikansi bl , b2 dan b3 secara individu. Jawabannya
tidak. Alasannya dalam uji signifikansi individu terhadap_parsial
koefieisn regresi diasumsikan bahwa setiap uji signifkansi berdasarkan
sample (independen ) yang berbeda.Jadi menguji signifikansi b2
dengan hipotesis b2=0 diasumsikan pengujian ini berdasarkan sample
yang berbeda ketika kita akan menguji b3 dengan hipotesis b3=-0.
Sementara itu ketika kita menguji joint hipotesis dengan sample yang
sama akan menyalahi asumsi prosedu pengujian.
Untuk menguji hipotesis ini digunakan statistik F dengan kriteria
pengambilan keputusan sebagai berikut:
@ Quick look : bila nilai F lebih besar daripada 4 maka Ho
dapat ditolak pada derajat kepercayaan 5%., Dengan kata lain
kita menerima hipotesis alternatif, yang menyatakan bahwa
semua variabel independen secara serentak dan signifikan
mempengaruhi variabel dependen.
e Membandingkan nilai F hasil perhitungan dengan nilai F
menurut tabel, Bila nilai F hitung lebih besar daripada nilai F
tabel, maka Ho ditolak dan menerima HA.
¢. Uji Signifikan Parameter Individual (Uji Statistik t)
Uji statistik t pada dasarnya menunjukkan seberapa jauh pengaruh
satu variabel penjelas/independen secara individual dalam menerangkan
98 ‘APLIKASI ANALISIS MULTIVARIATE Dengan Program IBM SPSS 25 Edisi 9
variasi variabel dependen. Hipotesis nol (Ho) yang hendak diuji adalah
apakah suatu parameter (bi) sama dengan nol, atau :
Ho: bi=0
Artinya apakah suatu variabel independen bukan merupakan penjelas
yang signifikan terhadap variabel dependen. Hipotesis alternatifnya
(HA) parameter suatu variabel tidak sama dengan nol, atau :
HA: bi #0
Artinya, variabel tersebut merupakan penjelas yang signifikan terhadap
variabel dependen.
Cara melakukan uji t adalah sebagai berikut:
© Quick look : bila jumlah degree of freedom (df) adalah 20 atau
lebih, dan derajat kepercayaan sebesar 5%, maka Ho yang
menyatakan bi = 0 dapat ditolak bila nilai t lebih besar dari 2
(dalam nilai absolut). Dengan kata lain kita menerima hipotesis
alternatif, yang menyatakan bahwa suatu variabel independen
secara individual mempengaruhi variabel dependen.
e Membandingkan nilai statistik t dengan titik kritis menurut
tabel. Apabila nilai statistik t hasil perhitungan lebih tinggi
dibadingkan nilai t tabel, kita menerima hipotesis alternatif yang
menyatakan bahwa suatu variabel independen secara individual
mempengaruhi variabel dependen.
Untuk menjelaskan aplikasi dari teori regresi di atas marilah kita analisis
file CROSSESC1.xls dengan program SPSS:
Kasus yang ingin dianalisis adalah apakah total income anggota keluarga
(INCOME) dipengaruhi oleh jumlah anggota keluarga (SIZE), gaji
yang ie kepala keluarga (EARNS), Besarnya kekayaan keluarga
tabungan tee od atau secara matematis
SIZE +b b2 EARNS +b3 WEALTH + b4 SAVING +e
aa
Aplikasi analiss multivariate dengan program ism spss 25. *
Fakultas
B281861606 legoro. la
menyelesaikan pendidikan Sarjana Ekonomi
Jurusan Akuntansi di Universitas Gadjah Mada
4985. Pendidikan S2 (M.Com) diselesaikannya di
University of New South Wales, Sydney, Australia
1990 dan pendidikan S3 (Ph.D) bidang
Management Accounting diselesaikan di University
of Wollongong, Australia 1995. Disamping sebagai
dosen tetap pada Fakultas Ekonomika dan Bisnis
UNDIP, ia juga menjadi dosen tidak tetap di program S3 Manajemen Jasa
Universitas Trisakti Jakarta dan di program S3 Manajemen Universitas
Tanjungpura Pontianak. la juga pernah menjadi Visiting Professor di
University of Malaya, Kuala Lumpur, Malaysia 2009-2011 dan 2017. Saat ini
menjabat sebagai Ketua Program Study Doktor ilmu ekonomi Universitas
Diponegoro. Lebih dari 30 artikel telah dipublikasikan di jurnal international
terindex Scopus (Author ID: 55875276500 scopus)
Buku-buku yang telah ditulis antara lain:
Pokok-Poko Akuntansi Pemerintahan BP FE Yogya, Statistik Non-Parame'rik
BP Undip, Persamaan Model Struktural dengan AMOS 24 BP Unc
Structural Equation Modeling Teori, Konsep dan Aplikasi dengan Progr
Lisrel 9.10 BP Undip, Structural Equation Modeling, Metode Alternatif den: an
Partial Least Squares (PLS) BP Undip, Partial Least Squares Konsep, Me
dan Aplikasi Menggunakan Program WarpPLS 5.0 BP Undip, Aplikasi An
Multivariate dengan Progem IBM SPSS 23 BP Undip, Ekonometrika der
Program IBM SPSS 24 BP Undip, Generalized Structured Compo: it
Analysis (GeSCA) BP Undip, Desain Penelitian Eksperimental den:
Program SPSS 23 BP Undip, Structural Equation Modeling dengan Progr *
SmartPLS 3.0, Structural Equation Modeling dengan Program XLSTAT "~~
Undip, Strucutral Equation Modeling Pendekatan Induktif dengan Progr
Tetrad IV BP Undip, Teori Akuntansi IFRS BP Undip, Akuntansi Pemerintal
Pusat (APBN) dan Daerah (APBD) BP Undip, Akuntansi Keperilakuan
Undip, Analisis Multivariat dan Ekonometrika dengan Program Eview 10
Undip, Teknik Penyususnan Skala Likert dalam Penelitian Akuntansi ¢
Bisnis BP Undip.
4
5
You might also like
- SPSS 23: Validity, Reliability, and Regression TestsNo ratings yetSPSS 23: Validity, Reliability, and Regression Tests10 pages
- Analysis of Deny Setyawan's Training ImpactNo ratings yetAnalysis of Deny Setyawan's Training Impact21 pages
- Multivariate Linear Regression in National Exam AnalysisNo ratings yetMultivariate Linear Regression in National Exam Analysis8 pages
- Regression Analysis and Diagnostics ReportNo ratings yetRegression Analysis and Diagnostics Report10 pages
- Multicollinearity & Heteroskedasticity GuideNo ratings yetMulticollinearity & Heteroskedasticity Guide39 pages
- Descriptive Statistics and Regression AnalysisNo ratings yetDescriptive Statistics and Regression Analysis8 pages
- Multiple Linear Regression Practicum GuideNo ratings yetMultiple Linear Regression Practicum Guide10 pages
- 11.2. Quantitative Data Analysis - RegressionNo ratings yet11.2. Quantitative Data Analysis - Regression29 pages
- Robust Regression Method for Energy SalesNo ratings yetRobust Regression Method for Energy Sales8 pages
- Panduan Regresi Berganda dalam Analisis DataNo ratings yetPanduan Regresi Berganda dalam Analisis Data5 pages
- Stepwise Regression Analysis ComparisonNo ratings yetStepwise Regression Analysis Comparison10 pages
- Descriptive Statistics and ANOVA ResultsNo ratings yetDescriptive Statistics and ANOVA Results3 pages
- Analisis Regresi Linear Permintaan Tenaga KerjaNo ratings yetAnalisis Regresi Linear Permintaan Tenaga Kerja4 pages
- Bivariate and Multivariate Normality Analysis100% (1)Bivariate and Multivariate Normality Analysis7 pages
- Uji Regresi Inflasi dan Variabel EkonomiNo ratings yetUji Regresi Inflasi dan Variabel Ekonomi3 pages
- Descriptive Statistics and ANOVA AnalysisNo ratings yetDescriptive Statistics and ANOVA Analysis4 pages
- Metode Modified Jackknife Ridge Regression Dalam Penanganan Multikolinieritas (Studi Kasus Indeks Pembangunan Manusia Di Jawa Tengah)No ratings yetMetode Modified Jackknife Ridge Regression Dalam Penanganan Multikolinieritas (Studi Kasus Indeks Pembangunan Manusia Di Jawa Tengah)10 pages