You might also like
- Data MiningDocument5 pagesData MiningmadhurjhsNo ratings yet
- Data MiningDocument4 pagesData MiningVivek GuptaNo ratings yet
- 01 Unit1Document13 pages01 Unit1Sridhar KumarNo ratings yet
- Big Data Processing Model and Challenging IssuesDocument69 pagesBig Data Processing Model and Challenging IssuesVenkatesh GardasNo ratings yet
- Mit401 Unit 08-SlmDocument13 pagesMit401 Unit 08-SlmAmit ParabNo ratings yet
- Unit 4 New Database Applications and Environments: by Bhupendra Singh SaudDocument14 pagesUnit 4 New Database Applications and Environments: by Bhupendra Singh SaudAnoo ShresthaNo ratings yet
- What Is Data MiningDocument5 pagesWhat Is Data MiningGustavo AlvesNo ratings yet
- Data MiningDocument40 pagesData Miningporpy_carol100% (1)
- A Techinical Paper: Tupimakadia1@yahoo - Co.in Yamu - 4u1985@yahoo - Co.inDocument14 pagesA Techinical Paper: Tupimakadia1@yahoo - Co.in Yamu - 4u1985@yahoo - Co.insur8742No ratings yet
- Motivation For Data Mining The Information CrisisDocument13 pagesMotivation For Data Mining The Information Crisisriddickdanish1No ratings yet
- Sri Venkateswara Engineering CollegeDocument15 pagesSri Venkateswara Engineering Collegeapi-19799369No ratings yet
- Data Warehousing and Mining With Q-Gram As An ApplicationDocument6 pagesData Warehousing and Mining With Q-Gram As An ApplicationBridget SmithNo ratings yet
- Web Intelligence: What Is Webintelligence?Document25 pagesWeb Intelligence: What Is Webintelligence?Rajesh RathodNo ratings yet
- Data Mining: What Is Data Mining?: OracleDocument16 pagesData Mining: What Is Data Mining?: OracleMayur N MalviyaNo ratings yet
- Data Mining: What Is Data Mining?: OracleDocument16 pagesData Mining: What Is Data Mining?: OracleDipali PatelNo ratings yet
- Data Moning Seminar ReportDocument12 pagesData Moning Seminar ReportSankalp MishraNo ratings yet
- A Survey On Data MiningDocument4 pagesA Survey On Data MiningInternational Organization of Scientific Research (IOSR)No ratings yet
- Data Mining Techniques and Multiple Classifiers for Marketing DecisionsDocument10 pagesData Mining Techniques and Multiple Classifiers for Marketing DecisionsAbhinav PandeyNo ratings yet
- MIS Assignement-1 - SwostikDocument7 pagesMIS Assignement-1 - SwostikSwostik RoutNo ratings yet
- Data Structures: Notes For Lecture 12 Introduction To Data Mining by Samaher Hussein AliDocument4 pagesData Structures: Notes For Lecture 12 Introduction To Data Mining by Samaher Hussein Alisamaher husseinNo ratings yet
- VivekDocument4 pagesVivekBiribiri WeixianNo ratings yet
- 1.1what Is Data Mining?: GallopDocument64 pages1.1what Is Data Mining?: GallopNelli HarshithaNo ratings yet
- Twitter Topic Modeling Reveals Insights Not Found in Traditional NewsDocument104 pagesTwitter Topic Modeling Reveals Insights Not Found in Traditional NewssaitejNo ratings yet
- Research Papers in Data Mining 2015Document6 pagesResearch Papers in Data Mining 2015orotmbbkf100% (1)
- Data Mining Techniques and ApplicationsDocument8 pagesData Mining Techniques and ApplicationsMani BhagatNo ratings yet
- What Is Data MiningDocument8 pagesWhat Is Data MiningAmran AnwarNo ratings yet
- Data Mining: What Is Data Mining?Document10 pagesData Mining: What Is Data Mining?kpcindrellaNo ratings yet
- Data Warehouse PresentationDocument28 pagesData Warehouse PresentationPrasad DhanikondaNo ratings yet
- Unit-I DW&DMDocument19 pagesUnit-I DW&DMthe sinha'sNo ratings yet
- Data Mining: What Is Data Mining?: OracleDocument6 pagesData Mining: What Is Data Mining?: OracleBabita YadavNo ratings yet
- Data MiningDocument12 pagesData MiningBharath PrabuNo ratings yet
- Acp ExciseDocument11 pagesAcp ExciseDerouiche ChaimaNo ratings yet
- Data Mining: OracleDocument6 pagesData Mining: OracleJob ZachariaNo ratings yet
- Data Mining Techniques and ApplicationsDocument16 pagesData Mining Techniques and Applicationslokesh KoppanathiNo ratings yet
- Data mining process steps and applicationsDocument4 pagesData mining process steps and applicationsmanojNo ratings yet
- Business IntelligenceassDocument6 pagesBusiness IntelligenceassAshley Wairimu OtienoNo ratings yet
- DMW UNIT 1 PessondranathDocument29 pagesDMW UNIT 1 Pessondranath2344Atharva PatilNo ratings yet
- Course Recommender System Aims at Predicting The Best Combination of Courses Selected by Students-1Document29 pagesCourse Recommender System Aims at Predicting The Best Combination of Courses Selected by Students-1ShivaniNo ratings yet
- Data Mining TechniquesDocument24 pagesData Mining TechniquesOmaR AL-SaffaRNo ratings yet
- Lecture 3Document10 pagesLecture 3mohammed.riad.bi.2020No ratings yet
- LECTURE NOTES ON DATA MINING and DATA WADocument84 pagesLECTURE NOTES ON DATA MINING and DATA WAAli AzfarNo ratings yet
- 04 Data Mining-ApplicationsDocument6 pages04 Data Mining-ApplicationsRaj EndranNo ratings yet
- IT Unit 4Document7 pagesIT Unit 4ShreestiNo ratings yet
- Unit-1 Introduction To Data MiningDocument33 pagesUnit-1 Introduction To Data Miningzeeshaan7290No ratings yet
- Data Mining For Customer SegmentationDocument13 pagesData Mining For Customer SegmentationRahul RanganathanNo ratings yet
- Introduction to Data Mining Techniques and ApplicationsDocument14 pagesIntroduction to Data Mining Techniques and ApplicationsuttamraoNo ratings yet
- Lec1 OverviewDocument4 pagesLec1 OverviewAlia buttNo ratings yet
- Knowledge Mining: Extracting Patterns from DataDocument16 pagesKnowledge Mining: Extracting Patterns from DataKathyaini AlagirisamyNo ratings yet
- Seminar Data MiningDocument10 pagesSeminar Data MiningSreedevi KovilakathNo ratings yet
- Data Mining AND Warehousing: AbstractDocument12 pagesData Mining AND Warehousing: AbstractSanthosh AnuhyaNo ratings yet
- ChandrakanthDocument64 pagesChandrakanthSuresh DhamathotiNo ratings yet
- Aispre 3 Lesson 3 MswordDocument3 pagesAispre 3 Lesson 3 MswordKennNo ratings yet
- A Survey On Data Mining Techniques and ApplicationsDocument5 pagesA Survey On Data Mining Techniques and ApplicationsEditor IJRITCCNo ratings yet
- Cs507 Data MiningDocument3 pagesCs507 Data Miningrabirabi100% (1)
- DataDocument9 pagesDataAlston FernandesNo ratings yet
- unit 1Document27 pagesunit 1bhavanabhoomika1234No ratings yet
- Data Mining Prologues: K.Sankar Lecturer / M.E., (P.HD) ., D.V.Rajkumar M.C.A., M.Phil LecturerDocument4 pagesData Mining Prologues: K.Sankar Lecturer / M.E., (P.HD) ., D.V.Rajkumar M.C.A., M.Phil LecturerJournal of Computer ApplicationsNo ratings yet
- Data Mining: by Doug AlexanderDocument6 pagesData Mining: by Doug AlexanderVictoria ZúñigaNo ratings yet
- Lec 1Document7 pagesLec 1marshal 04No ratings yet
- Data BlendingDocument3 pagesData Blendingjohn949No ratings yet
- Fourier AnalysisDocument10 pagesFourier Analysiswatson191No ratings yet
- Early Case AssessmentDocument2 pagesEarly Case Assessmentmattew657No ratings yet
- Multilinear Principal Component AnalysisDocument3 pagesMultilinear Principal Component Analysismattew657No ratings yet
- Dimensionality ReductionDocument7 pagesDimensionality Reductionmattew657No ratings yet
- Actuarial ScienceDocument10 pagesActuarial Sciencemattew657No ratings yet
- Data and Information VisualizationDocument27 pagesData and Information Visualizationmattew657No ratings yet
- Digital Signal ProcessingDocument8 pagesDigital Signal Processingmattew657No ratings yet
- Censoring (Statistics)Document5 pagesCensoring (Statistics)mattew657No ratings yet
- Exploratory Data AnalysisDocument7 pagesExploratory Data Analysismattew657No ratings yet
- PRODIGAL (Computer System)Document2 pagesPRODIGAL (Computer System)mattew657No ratings yet
- Equifax Workforce SolutionsDocument4 pagesEquifax Workforce Solutionsmattew657No ratings yet
- Educational Data MiningDocument9 pagesEducational Data Miningmattew657No ratings yet
- Data Mining in AgricultureDocument4 pagesData Mining in Agriculturemattew657No ratings yet
- Anomaly Detection at Multiple ScalesDocument2 pagesAnomaly Detection at Multiple Scalesmattew657No ratings yet
- Data AppliedDocument1 pageData Appliedmattew657No ratings yet
- Time SeriesDocument13 pagesTime Seriesmattew657No ratings yet
- Data WarehouseDocument12 pagesData Warehousemattew657100% (1)
- Big DataDocument41 pagesBig Datamattew657No ratings yet
- Electronic DiscoveryDocument9 pagesElectronic Discoveryolivia523No ratings yet
- Information ExtractionDocument7 pagesInformation Extractionmattew657No ratings yet
- Web ScrapingDocument9 pagesWeb Scrapingmattew657No ratings yet
- Educational Data MiningDocument9 pagesEducational Data Miningmattew657No ratings yet
- PsychometricsDocument11 pagesPsychometricsmattew657No ratings yet
- Data Mining ProcessesDocument14 pagesData Mining Processesmattew657No ratings yet
- Data Transformation (Computing)Document5 pagesData Transformation (Computing)mattew657No ratings yet
- Data AnalysisDocument28 pagesData Analysismattew657No ratings yet
- Predictive AnalyticsDocument9 pagesPredictive Analyticsmattew657No ratings yet
- Category Applied Data MiningDocument2 pagesCategory Applied Data Miningmattew657No ratings yet
- Tirfor: Lifting and Pulling Machines With Unlimited Wire RopeDocument26 pagesTirfor: Lifting and Pulling Machines With Unlimited Wire RopeGreg ArabazNo ratings yet
- Lean Management AssignmentDocument14 pagesLean Management AssignmentElorm Oben-Torkornoo100% (1)
- Aerospace Opportunities in SwitzerlandDocument5 pagesAerospace Opportunities in SwitzerlandBojana DekicNo ratings yet
- Bhakti Trader Ram Pal JiDocument232 pagesBhakti Trader Ram Pal JiplancosterNo ratings yet
- Hisar CFC - Approved DPRDocument126 pagesHisar CFC - Approved DPRSATYAM KUMARNo ratings yet
- TNG UPDATE InstructionsDocument10 pagesTNG UPDATE InstructionsDiogo Alexandre Crivelari CrivelNo ratings yet
- SS1c MIDTERMS LearningModuleDocument82 pagesSS1c MIDTERMS LearningModuleBryce VentenillaNo ratings yet
- SCJP 1.6 Mock Exam Questions (60 QuestionsDocument32 pagesSCJP 1.6 Mock Exam Questions (60 QuestionsManas GhoshNo ratings yet
- Managing Post COVID SyndromeDocument4 pagesManaging Post COVID SyndromeReddy VaniNo ratings yet
- Service Positioning and DesignDocument3 pagesService Positioning and DesignSaurabh SinhaNo ratings yet
- Smoktech Vmax User ManualDocument9 pagesSmoktech Vmax User ManualStella PapaNo ratings yet
- GRP Product CatalogueDocument57 pagesGRP Product CatalogueMulyana alcNo ratings yet
- Visualization BenchmarkingDocument15 pagesVisualization BenchmarkingRanjith S100% (1)
- Inspection and Acceptance Report: Stock No. Unit Description QuantityDocument6 pagesInspection and Acceptance Report: Stock No. Unit Description QuantityAnj LeeNo ratings yet
- Admission Procedure For International StudentsDocument8 pagesAdmission Procedure For International StudentsAndreea Anghel-DissanayakaNo ratings yet
- Political Engineering and Party Politics in Conflict-Prone SocietiesDocument18 pagesPolitical Engineering and Party Politics in Conflict-Prone SocietiesNashiba Dida-AgunNo ratings yet
- State of Education in Tibet 2003Document112 pagesState of Education in Tibet 2003Tibetan Centre for Human Rights and DemocracyNo ratings yet
- Building and Enhancing New Literacies Across The CurriculumDocument119 pagesBuilding and Enhancing New Literacies Across The CurriculumLowela Kasandra100% (3)
- MATHEMATICAL ECONOMICSDocument54 pagesMATHEMATICAL ECONOMICSCities Normah0% (1)
- Cyber Security 2017Document8 pagesCyber Security 2017Anonymous i1ClcyNo ratings yet
- Proposed Panel Antenna: Globe Telecom ProprietaryDocument2 pagesProposed Panel Antenna: Globe Telecom ProprietaryJason QuibanNo ratings yet
- Biamp Vocia Catalog Apr2020Document24 pagesBiamp Vocia Catalog Apr2020Mahavir Shantilal DhokaNo ratings yet
- AWS Cloud Practicioner Exam Examples 0Document110 pagesAWS Cloud Practicioner Exam Examples 0AnataTumonglo100% (3)
- Analysis and Design of Multi Storey Building by Using STAAD ProDocument5 pagesAnalysis and Design of Multi Storey Building by Using STAAD Prolikith rockNo ratings yet
- Understanding 2006 PSAT-NMSQT ScoresDocument8 pagesUnderstanding 2006 PSAT-NMSQT ScorestacobeoNo ratings yet
- Communications201101 DLDocument132 pagesCommunications201101 DLAle SandovalNo ratings yet
- Flexible Ductwork Report - November 2011v2Document69 pagesFlexible Ductwork Report - November 2011v2bommobNo ratings yet
- DLL Grade7 First 1solutions ConcentrationDocument5 pagesDLL Grade7 First 1solutions ConcentrationJaneth de JuanNo ratings yet
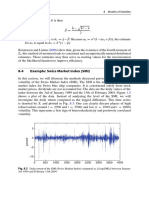
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- European Business in China Position Paper 2017 2018 (English Version)Document408 pagesEuropean Business in China Position Paper 2017 2018 (English Version)Prasanth RajuNo ratings yet