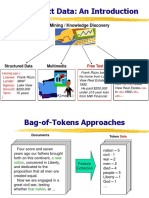
You might also like
- Vector Space Model ExplainedDocument11 pagesVector Space Model ExplainedjeysamNo ratings yet
- Acm Iconiaac 2014Document8 pagesAcm Iconiaac 2014veningstonNo ratings yet
- Latent Semantic Analysis For Information Retrieval: Khyati Pawde, Niharika Purbey, Shreya Gangan, Lakshmi KurupDocument4 pagesLatent Semantic Analysis For Information Retrieval: Khyati Pawde, Niharika Purbey, Shreya Gangan, Lakshmi KuruperpublicationNo ratings yet
- Question AnsweringDocument29 pagesQuestion AnsweringSV PRNo ratings yet
- Anti-Serendipity: Finding Useless Documents and Similar DocumentsDocument9 pagesAnti-Serendipity: Finding Useless Documents and Similar DocumentsPreeti BansalNo ratings yet
- Personalized Information Retrieval SysteDocument6 pagesPersonalized Information Retrieval Systenofearknight625No ratings yet
- K-Means Document Clustering Using Vector Space ModelDocument5 pagesK-Means Document Clustering Using Vector Space ModelBONFRINGNo ratings yet
- Document Ranking Using Customizes Vector MethodDocument6 pagesDocument Ranking Using Customizes Vector MethodEditor IJTSRDNo ratings yet
- A Study On Document Classification Using Machine Learning TechniquesDocument6 pagesA Study On Document Classification Using Machine Learning TechniquesrohitNo ratings yet
- A Study On Document Classification Using Machine Learning TechniquesDocument6 pagesA Study On Document Classification Using Machine Learning TechniquesrohitNo ratings yet
- 9 JSE (Jan-Mar'18) 1Document7 pages9 JSE (Jan-Mar'18) 1Prashant DahiwaleNo ratings yet
- Language Independent DocumentDocument10 pagesLanguage Independent DocumentAnonymous Gl4IRRjzNNo ratings yet
- Text MiningDocument27 pagesText MiningAchyuth PentakotaNo ratings yet
- A New Hierarchical Document Clustering Method: Gang Kou Yi PengDocument4 pagesA New Hierarchical Document Clustering Method: Gang Kou Yi PengRam KumarNo ratings yet
- Bees Swarm Optimization Based Approach For Web Information RetrievalDocument8 pagesBees Swarm Optimization Based Approach For Web Information RetrievalMaya NagasakiNo ratings yet
- Comparing Topic Modeling and Named Entity Recognition Techniques For The Semantic Indexing of A Landscape Architecture TextbookDocument6 pagesComparing Topic Modeling and Named Entity Recognition Techniques For The Semantic Indexing of A Landscape Architecture Textbooksudharsan_tkgNo ratings yet
- Detecção de Tópicos em Documentos Usando Agrupamento de Vetores de PalavrasDocument8 pagesDetecção de Tópicos em Documentos Usando Agrupamento de Vetores de PalavrasGuilhermeRaiolNo ratings yet
- Approaches On The Implementation of The Multimedia DatabasesDocument10 pagesApproaches On The Implementation of The Multimedia DatabasesGeorge Octavian MitaNo ratings yet
- Implementing K-Means Clustering Algorithm Using Mapreduce ParadigmDocument5 pagesImplementing K-Means Clustering Algorithm Using Mapreduce ParadigmvrkatevarapuNo ratings yet
- Cacm FinDocument5 pagesCacm FinAvina NigNo ratings yet
- Paper 10Document5 pagesPaper 10Unknown UnknownNo ratings yet
- Document Classification Utilising Ontologies and Relations Between DocumentsDocument8 pagesDocument Classification Utilising Ontologies and Relations Between DocumentsUno de MadridNo ratings yet
- Text Classification in 20 NewsgroupsDocument17 pagesText Classification in 20 NewsgroupsRaja PurbaNo ratings yet
- Zigbee Based Wireless Data AcquisitionDocument15 pagesZigbee Based Wireless Data AcquisitionanjanbsNo ratings yet
- Introduction of IR ModelsDocument62 pagesIntroduction of IR ModelsMagarsa BedasaNo ratings yet
- Dynamic - Neural - Networks - For - Text - ClassificationDocument6 pagesDynamic - Neural - Networks - For - Text - ClassificationDuarte Harris CruzNo ratings yet
- Information Retrieval On Cranfield DatasetDocument15 pagesInformation Retrieval On Cranfield DatasetvanyaNo ratings yet
- Emerging Multidisciplinary Research Across Database Management SystemsDocument4 pagesEmerging Multidisciplinary Research Across Database Management SystemsMani AmmalNo ratings yet
- A Detailed Comparative Analysis of Document Ranking ApproachesDocument5 pagesA Detailed Comparative Analysis of Document Ranking ApproachesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Multi-Agent System For Documents Retrieval and Evaluation Using Fuzzy Inference SystemsDocument7 pagesMulti-Agent System For Documents Retrieval and Evaluation Using Fuzzy Inference SystemsIAES IJAINo ratings yet
- Can Vector Space Bases Model Context?: Abstract Current Information Retrieval Models Do Not Directly Incorporate ConDocument11 pagesCan Vector Space Bases Model Context?: Abstract Current Information Retrieval Models Do Not Directly Incorporate ConParagNo ratings yet
- Standardizing Research Data Documentation with DDIDocument18 pagesStandardizing Research Data Documentation with DDIMahmoud MahdyNo ratings yet
- IRS B Tech CSE Part 1Document161 pagesIRS B Tech CSE Part 1Rajput SinghNo ratings yet
- Modeling Documents As Mixtures of Persons For Expert FindingDocument12 pagesModeling Documents As Mixtures of Persons For Expert FindingL TNo ratings yet
- Completed Unit II 17.7.17Document113 pagesCompleted Unit II 17.7.17Dr.A.R.KavithaNo ratings yet
- Concept MiningDocument2 pagesConcept Miningolivia523No ratings yet
- 8946-Article Text-12474-1-2-20201228Document7 pages8946-Article Text-12474-1-2-20201228ROS ROSNo ratings yet
- Humanitarian Applications of Big Data: Prof. (MRS.) Sindhu Nair, Mr. Neel Shah, Mr. Pinank ShahDocument3 pagesHumanitarian Applications of Big Data: Prof. (MRS.) Sindhu Nair, Mr. Neel Shah, Mr. Pinank ShaherpublicationNo ratings yet
- Document Clustering Method Based On Visual FeaturesDocument5 pagesDocument Clustering Method Based On Visual FeaturesrajanNo ratings yet
- SSW: A Small-World-Based Overlay For Peer-to-Peer SearchDocument15 pagesSSW: A Small-World-Based Overlay For Peer-to-Peer Searchsyed_zakriyaNo ratings yet
- State of The Art Document Clustering Algorithms Based On Semantic SimilarityDocument18 pagesState of The Art Document Clustering Algorithms Based On Semantic SimilarityAna ArianiNo ratings yet
- Text MiningDocument23 pagesText MiningChakkarawarthiNo ratings yet
- Course and Book Recommendation Model Based On The Item Based Filtering System With Similarity Measure Based On The Dice CoefficientDocument4 pagesCourse and Book Recommendation Model Based On The Item Based Filtering System With Similarity Measure Based On The Dice CoefficientInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- A Survey On Text Categorization: International Journal of Computer Trends and Technology-volume3Issue1 - 2012Document7 pagesA Survey On Text Categorization: International Journal of Computer Trends and Technology-volume3Issue1 - 2012surendiran123No ratings yet
- JIU Term-Document MatrixDocument6 pagesJIU Term-Document MatrixjewarNo ratings yet
- NLP Mod-V Q - A (Uploaded by Snaptricks - In)Document7 pagesNLP Mod-V Q - A (Uploaded by Snaptricks - In)sharan rajNo ratings yet
- Named Entity Disambiguation: A Hybrid Approach: Ton Duc Thang University, Viet Nam E-Mail: Hien@tdt - Edu.vnDocument16 pagesNamed Entity Disambiguation: A Hybrid Approach: Ton Duc Thang University, Viet Nam E-Mail: Hien@tdt - Edu.vnJuca CrispimNo ratings yet
- Education and Design: Using Human-Computer Interaction Case Studies To LearnDocument6 pagesEducation and Design: Using Human-Computer Interaction Case Studies To LearnLaurian VegaNo ratings yet
- DoCEIS2013 - BrainMap - A Navigation Support System in A Tourism Case StudyDocument8 pagesDoCEIS2013 - BrainMap - A Navigation Support System in A Tourism Case StudybromeroviateclaNo ratings yet
- 1792 2006 1 SM PDFDocument10 pages1792 2006 1 SM PDFScorpion1985No ratings yet
- Chi 88Document6 pagesChi 88api-3803202No ratings yet
- Tamrakar 2015Document6 pagesTamrakar 2015First UnboxNo ratings yet
- Doing Database Design With MysqlDocument15 pagesDoing Database Design With MysqlbrNo ratings yet
- Query Expansion Based On Modified Concept2vec Model Using Resource Description Framework Knowledge GraphsDocument10 pagesQuery Expansion Based On Modified Concept2vec Model Using Resource Description Framework Knowledge GraphsIAES IJAINo ratings yet
- Course Name: Advanced Information RetrievalDocument6 pagesCourse Name: Advanced Information RetrievaljewarNo ratings yet
- Extracting Keyphrases From Research Papers Using Citation NetworksDocument7 pagesExtracting Keyphrases From Research Papers Using Citation NetworksVivian JinNo ratings yet
- Monitoring and Supporting Data Conversion ExamDocument2 pagesMonitoring and Supporting Data Conversion ExamAmanuel KassaNo ratings yet
- Module 2 - Data Management and Data WranglingDocument40 pagesModule 2 - Data Management and Data WranglingKristian UyNo ratings yet
- Lesson 4. Overview of Health InformaticsDocument2 pagesLesson 4. Overview of Health InformaticsClark AraraoNo ratings yet
- Database Design Lab ActivityDocument9 pagesDatabase Design Lab ActivityHega SiniNo ratings yet
- Diabetic Retinopathy Detection Deep Learning - Matlab - SimulinkDocument3 pagesDiabetic Retinopathy Detection Deep Learning - Matlab - SimulinkAdnan KhanNo ratings yet
- Second Review PTT 15062023Document28 pagesSecond Review PTT 15062023ANKUSH SINHANo ratings yet
- Unit 4 NLP NotesDocument35 pagesUnit 4 NLP Notessneha03102003No ratings yet
- Warwick Thesis TemplateDocument5 pagesWarwick Thesis Templateangelashfordmurfreesboro100% (2)
- Simple and Blue Resume-WPS OfficeDocument1 pageSimple and Blue Resume-WPS OfficeJenamiso LufuNo ratings yet
- Machine Learning Interview Preparation: Day 09Document9 pagesMachine Learning Interview Preparation: Day 09ARPAN MAITYNo ratings yet
- Machine Learning Techniques QuantumDocument161 pagesMachine Learning Techniques QuantumAnup YadavNo ratings yet
- Chapter 1 - Introduction To Database NotesDocument12 pagesChapter 1 - Introduction To Database NotesDibyeshNo ratings yet
- 121 CseDocument23 pages121 CsekshownishNo ratings yet
- Analyzing an IEEE Paper on Expert Systems Using a Hybrid ApproachDocument9 pagesAnalyzing an IEEE Paper on Expert Systems Using a Hybrid ApproachBiatchNo ratings yet
- UntitledDocument3 pagesUntitledsamirNo ratings yet
- 2014 2015 Spring M275 FinalDocument5 pages2014 2015 Spring M275 Finalabod attarNo ratings yet
- PostgreSQL Architecture 2Document5 pagesPostgreSQL Architecture 2Stephen EfangeNo ratings yet
- Python SyllabusDocument12 pagesPython SyllabusNarendra kumarNo ratings yet
- Superfluous Substance Reclaimed For Posterity Industry Industry ProgressionDocument99 pagesSuperfluous Substance Reclaimed For Posterity Industry Industry ProgressionMarliya MNo ratings yet
- DBMS: Database Management System ExplainedDocument12 pagesDBMS: Database Management System ExplainedTaniya SethiNo ratings yet
- Anup Davin M: ObjectiveDocument3 pagesAnup Davin M: ObjectiveDavin AnupNo ratings yet
- Data Science Interview Questions (#Day15)Document12 pagesData Science Interview Questions (#Day15)ARPAN MAITYNo ratings yet
- Normalization DbmsDocument9 pagesNormalization DbmsJohn MainaNo ratings yet
- Hema. M: ObjectiveDocument3 pagesHema. M: ObjectiveSoudaNo ratings yet
- A Survey On Analysing The Crash ReportsDocument4 pagesA Survey On Analysing The Crash ReportsEddy ManurungNo ratings yet
- Stress Detection Using Emotions A SurveyDocument6 pagesStress Detection Using Emotions A SurveyIJRASETPublicationsNo ratings yet
- Chap-11 Relational Databases Notes Class 12Document12 pagesChap-11 Relational Databases Notes Class 12Rachita RamanNo ratings yet
- Cat AssignmentDocument2 pagesCat AssignmentMungai KagechuNo ratings yet
- DataBase Management (VBSPU 4th Sem)Document108 pagesDataBase Management (VBSPU 4th Sem)Atharv KatkarNo ratings yet
- Fundamentals of Database System - Module - CHapter - OneDocument19 pagesFundamentals of Database System - Module - CHapter - OneDesyilalNo ratings yet