You might also like
- Have - You - Really - Loved - A - Woman - 2-ViolinoDocument1 pageHave - You - Really - Loved - A - Woman - 2-ViolinoJarom NascimentoNo ratings yet
- Have - You - Really - Loved - A - Woman - 2-ViolonceloDocument1 pageHave - You - Really - Loved - A - Woman - 2-ViolonceloJarom NascimentoNo ratings yet
- RemembranceDocument1 pageRemembranceCarol Santa RosaNo ratings yet
- 1st Floor Plan 2023, 07, 27 - Shop NumberDocument1 page1st Floor Plan 2023, 07, 27 - Shop Numbermassror.ewazNo ratings yet
- 16 - Xvi - Weather Chart - Curuan SiteDocument1 page16 - Xvi - Weather Chart - Curuan Sitebry bryNo ratings yet
- PCB LRL FrancoDocument1 pagePCB LRL FrancoSleshi Mekonnen0% (1)
- Knorr-Bremse Antilock Braking System for TrucksDocument1 pageKnorr-Bremse Antilock Braking System for TrucksRowan Cornelius0% (2)
- Mexico de Noche - Trompetas - Mariachi Vargas de TecalitlanDocument12 pagesMexico de Noche - Trompetas - Mariachi Vargas de Tecalitlanjosebassguitar100% (1)
- AbrilescoDocument1 pageAbrilescoJavier SanchoNo ratings yet
- 2017-03-22-104910-EBS_2.x_-_EBS_pre_TrucksDocument1 page2017-03-22-104910-EBS_2.x_-_EBS_pre_Trucksعبدالغني القباطيNo ratings yet
- 2017-03-22-104910-EBS_2.x_-_EBS_pre_Trucks (1)Document1 page2017-03-22-104910-EBS_2.x_-_EBS_pre_Trucks (1)عبدالغني القباطيNo ratings yet
- 2017-03-22-104910-EBS_2.x_-_EBS_pre_Trucks (1)Document1 page2017-03-22-104910-EBS_2.x_-_EBS_pre_Trucks (1)عبدالغني القباطيNo ratings yet
- Ouço o Som - Trompete em BBDocument1 pageOuço o Som - Trompete em BBDavi LuizNo ratings yet
- M3-Fci 1Document1 pageM3-Fci 1Lovely BouNo ratings yet
- MicroMod ESP32 SchematicDocument1 pageMicroMod ESP32 SchematicJonatanNo ratings yet
- Blow-Up Area: (Lot Area 25MX25M)Document1 pageBlow-Up Area: (Lot Area 25MX25M)Herbee ZevlagNo ratings yet
- Edited - Index Law Code BreakerDocument1 pageEdited - Index Law Code Breakerjada romeroNo ratings yet
- Es Violino 2Document2 pagesEs Violino 2adm.andersoncruzNo ratings yet
- Highway To Hell: Arrangement and Tab by Christophe DeremyDocument17 pagesHighway To Hell: Arrangement and Tab by Christophe DeremySujanto WidjajaNo ratings yet
- NEXUS 7-Speed Internal Hub W/coaster BrakeDocument1 pageNEXUS 7-Speed Internal Hub W/coaster BrakesolerviNo ratings yet
- All Right Now Bass TabDocument2 pagesAll Right Now Bass TabEnrique RosasNo ratings yet
- Emma NA Subboard SchematicsDocument2 pagesEmma NA Subboard Schematicsheiber ascanioNo ratings yet
- Memorando Multiple-000005-2022-Goecor-Erm2022Document3 pagesMemorando Multiple-000005-2022-Goecor-Erm2022Mario Garcia PomarNo ratings yet
- Sistema de Freio: Caminhões Volkswagen 25-390 - TractorDocument1 pageSistema de Freio: Caminhões Volkswagen 25-390 - TractorAnderson Luiz100% (1)
- Overall connection diagram for cassette mechanism moduleDocument28 pagesOverall connection diagram for cassette mechanism moduleAlexey OnishenkoNo ratings yet
- API 2C (2004) Specification For Offshore Pedestal Mounted CranesDocument51 pagesAPI 2C (2004) Specification For Offshore Pedestal Mounted CranesDenisNo ratings yet
- Carrer Opportunities - The ClashDocument3 pagesCarrer Opportunities - The ClashImportaciones e Inversiones CYHNo ratings yet
- Danse Hongroise 05Document2 pagesDanse Hongroise 05Frédéric SorhaitzNo ratings yet
- Czardas For Tenor Trombone PDFDocument3 pagesCzardas For Tenor Trombone PDFPlatanito DondiegoNo ratings yet
- Fletchers Song in Club - WhiplashDocument2 pagesFletchers Song in Club - WhiplashPonce Meza JorgeNo ratings yet
- Revised 200CMD PULSAR HOTEL-Mar25-2019Document5 pagesRevised 200CMD PULSAR HOTEL-Mar25-2019Jonathan Quilang ObienaNo ratings yet
- Bench Vise Isometric, Front, Side and Top ViewsDocument1 pageBench Vise Isometric, Front, Side and Top ViewsshubhamNo ratings yet
- Piano Cold Coffe SwingDocument2 pagesPiano Cold Coffe SwingRubén SollosoNo ratings yet
- CHT Bmifa Girls Z 5 19years PDFDocument1 pageCHT Bmifa Girls Z 5 19years PDFRetnoNurulMandasariNo ratings yet
- Dissolved Oxygen Sample Code: ArduinoDocument1 pageDissolved Oxygen Sample Code: ArduinoLuisRoseroNo ratings yet
- I'm A Believer - Monkees - GDocument1 pageI'm A Believer - Monkees - GtaniaiorioNo ratings yet
- Dragon Ball GT-Flauta IIDocument1 pageDragon Ball GT-Flauta IITâmissonazevedo tamissonbassNo ratings yet
- Moonlight On The ThamesDocument2 pagesMoonlight On The ThamesTonny Leibnitz Ruda AltuveNo ratings yet
- La Gata Bajo La Lluvia PDFDocument1 pageLa Gata Bajo La Lluvia PDFBarrios Styvens50% (2)
- SF7 Duro DJ eDocument1 pageSF7 Duro DJ eDuško JevticNo ratings yet
- Green HornetDocument3 pagesGreen HornetPaulo Rosas ChávezNo ratings yet
- Dust_in_the_windDocument2 pagesDust_in_the_windVung NguyenNo ratings yet
- Alfa Laval T-82P Rotary Jet Head - Portable: Fast, Effective Impact CleaningDocument4 pagesAlfa Laval T-82P Rotary Jet Head - Portable: Fast, Effective Impact CleaningSamo SpontanostNo ratings yet
- On The Bach String MibDocument2 pagesOn The Bach String Mibenzo dell'airaNo ratings yet
- Renault V.I.: ModelsDocument7 pagesRenault V.I.: ModelsChaoui MoundjiNo ratings yet
- OM5284/EB03 Audio Module Setup GuideDocument4 pagesOM5284/EB03 Audio Module Setup GuideLuis CarlosNo ratings yet
- Laptop Lenovo Foxcon-TPC01Document39 pagesLaptop Lenovo Foxcon-TPC01حسن علي نوفلNo ratings yet
- Registros LateralesDocument1 pageRegistros LateralesFer OrtegaNo ratings yet
- KCNR3528Document2 pagesKCNR3528seba paezNo ratings yet
- PS1501 Power AmpDocument1 pagePS1501 Power AmpAdriana DundesNo ratings yet
- Sueño ViolinDocument1 pageSueño ViolinSujey BallesterosNo ratings yet
- Luis Miguel Trombón Será Que No Me Amas Sheet MusicDocument1 pageLuis Miguel Trombón Será Que No Me Amas Sheet MusicHiram VázquezNo ratings yet
- BX 32TD2Document2 pagesBX 32TD2Jack HawkeNo ratings yet
- Evidencias FlautaDocument1 pageEvidencias FlautaMaestro Nelio AmaroNo ratings yet
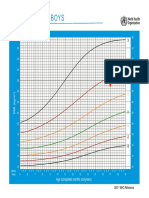
- BMI-for-age BOYS: 5 To 19 Years (Z-Scores)Document1 pageBMI-for-age BOYS: 5 To 19 Years (Z-Scores)Miko FernandezNo ratings yet
- OMS. IMC Meninos - 5-19 Anos. em Z Score.Document1 pageOMS. IMC Meninos - 5-19 Anos. em Z Score.anaclaraamaralf2002No ratings yet
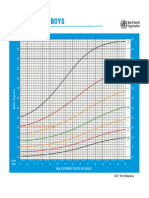
- Boyz BmiDocument1 pageBoyz BmiShana MarisseNo ratings yet
- OMS. IMC Meninos - 5-19 Anos. em Z Score.Document1 pageOMS. IMC Meninos - 5-19 Anos. em Z Score.Leciane Thewsley Rodrigues NogueiraNo ratings yet
- 40 - PDFsam - Escholarship UC Item 5qd0r4wsDocument1 page40 - PDFsam - Escholarship UC Item 5qd0r4wsMohammadNo ratings yet
- 16 - PDFsam - Escholarship UC Item 5qd0r4wsDocument1 page16 - PDFsam - Escholarship UC Item 5qd0r4wsMohammadNo ratings yet
- 9.11 Performing Multiple Operations On A List Using FunctorsDocument4 pages9.11 Performing Multiple Operations On A List Using FunctorsMohammadNo ratings yet
- 16 - PDFsam - Escholarship UC Item 5qd0r4wsDocument1 page16 - PDFsam - Escholarship UC Item 5qd0r4wsMohammadNo ratings yet
- 24 - PDFsam - Escholarship UC Item 5qd0r4wsDocument1 page24 - PDFsam - Escholarship UC Item 5qd0r4wsMohammadNo ratings yet
- Deep Learning For Assignment of Protein Secondary Structure Elements From CoordinatesDocument7 pagesDeep Learning For Assignment of Protein Secondary Structure Elements From CoordinatesMohammadNo ratings yet
- 19 - PDFsam - Beginning Rust - From Novice To Professional (PDFDrive)Document1 page19 - PDFsam - Beginning Rust - From Novice To Professional (PDFDrive)MohammadNo ratings yet
- 9.11 Performing Multiple Operations On A List Using FunctorsDocument4 pages9.11 Performing Multiple Operations On A List Using FunctorsMohammadNo ratings yet
- 9.11 Performing Multiple Operations On A List Using FunctorsDocument4 pages9.11 Performing Multiple Operations On A List Using FunctorsMohammadNo ratings yet
- Closures in C#: Understanding Behavior and StateDocument3 pagesClosures in C#: Understanding Behavior and StateMohammadNo ratings yet
- 18.4 Being Notified of The Completion of An Asynchronous DelegateDocument2 pages18.4 Being Notified of The Completion of An Asynchronous DelegateMohammadNo ratings yet
- 9.11 Performing Multiple Operations On A List Using FunctorsDocument1 page9.11 Performing Multiple Operations On A List Using FunctorsMohammadNo ratings yet
- 9.11 Performing Multiple Operations On A List Using FunctorsDocument1 page9.11 Performing Multiple Operations On A List Using FunctorsMohammadNo ratings yet
- Example 18-3. Getting Notification On Completion of An Anonymous DelegateDocument1 pageExample 18-3. Getting Notification On Completion of An Anonymous DelegateMohammadNo ratings yet
- Solution: Securitymanager - IsgrantedDocument5 pagesSolution: Securitymanager - IsgrantedMohammadNo ratings yet
- ZISBVUk Uv 7Document1 pageZISBVUk Uv 7MohammadNo ratings yet
- 9.11 Performing Multiple Operations On A List Using FunctorsDocument1 page9.11 Performing Multiple Operations On A List Using FunctorsMohammadNo ratings yet
- 18.4 Being Notified of The Completion of An Asynchronous DelegateDocument2 pages18.4 Being Notified of The Completion of An Asynchronous DelegateMohammadNo ratings yet
- Check permissions using SecurityManager.IsGranted methodDocument2 pagesCheck permissions using SecurityManager.IsGranted methodMohammadNo ratings yet
- 18.4 Being Notified of The Completion of An Asynchronous DelegateDocument3 pages18.4 Being Notified of The Completion of An Asynchronous DelegateMohammadNo ratings yet
- Solution: Securitymanager - IsgrantedDocument4 pagesSolution: Securitymanager - IsgrantedMohammadNo ratings yet
- Rethrow exceptions at highest levelDocument4 pagesRethrow exceptions at highest levelMohammadNo ratings yet
- Rethrow exceptions at highest levelDocument4 pagesRethrow exceptions at highest levelMohammadNo ratings yet
- Solution: Securitymanager - IsgrantedDocument4 pagesSolution: Securitymanager - IsgrantedMohammadNo ratings yet
- Check permissions using SecurityManager.IsGranted methodDocument2 pagesCheck permissions using SecurityManager.IsGranted methodMohammadNo ratings yet
- Solution: Securitymanager - IsgrantedDocument5 pagesSolution: Securitymanager - IsgrantedMohammadNo ratings yet
- Solution: Securitymanager - IsgrantedDocument3 pagesSolution: Securitymanager - IsgrantedMohammadNo ratings yet
- Solution: Securitymanager - IsgrantedDocument3 pagesSolution: Securitymanager - IsgrantedMohammadNo ratings yet
- Check permissions using SecurityManager.IsGranted methodDocument2 pagesCheck permissions using SecurityManager.IsGranted methodMohammadNo ratings yet
- ZISBVUk Uv 7Document1 pageZISBVUk Uv 7MohammadNo ratings yet
- ITATB Lesson 3 Key ComponentsDocument9 pagesITATB Lesson 3 Key Componentsber tingNo ratings yet
- Effect of Covid-19 On CompaniesDocument11 pagesEffect of Covid-19 On CompaniesSagar SreekumarNo ratings yet
- Syllabus CM3045 3DGADocument7 pagesSyllabus CM3045 3DGAPrasannaNo ratings yet
- p920 p720 Power Configurator v1.6Document25 pagesp920 p720 Power Configurator v1.6DemoNo ratings yet
- Sims4 App InfoDocument5 pagesSims4 App InfooltisorNo ratings yet
- (Guide) HD4600-Hdmi Audio (DSDT or SSDT) v2.1.3Document12 pages(Guide) HD4600-Hdmi Audio (DSDT or SSDT) v2.1.3Robin XuNo ratings yet
- Adobe Premiere Pro - System Requirements: WindowsDocument2 pagesAdobe Premiere Pro - System Requirements: WindowsMinh KhôiNo ratings yet
- Mini Project Report FormatDocument3 pagesMini Project Report FormatAyush kargutkarNo ratings yet
- Satellite C55D-C5271 PDFDocument3 pagesSatellite C55D-C5271 PDFgeko1No ratings yet
- Laboratory ExDocument2 pagesLaboratory ExDeprr 悪夢No ratings yet
- Real Time Face Detection ReportDocument78 pagesReal Time Face Detection Reportblessingj19it018No ratings yet
- Petrel 2014 Installation GuideDocument96 pagesPetrel 2014 Installation GuideAngie Carolina Rodriguez MeloNo ratings yet
- HistogramDocument11 pagesHistogramUltimate AltruistNo ratings yet
- APS 7.5 Photogrammetry SoftwareDocument2 pagesAPS 7.5 Photogrammetry SoftwareFajar RahmawanNo ratings yet
- ExdiDocument3 pagesExdiBayarbaatarNo ratings yet
- Snapdragon 435 Processor Product Brief PDFDocument2 pagesSnapdragon 435 Processor Product Brief PDFrichardtao89No ratings yet
- Automotive Processors: "Jacinto 6 Plus"Document2 pagesAutomotive Processors: "Jacinto 6 Plus"david tangNo ratings yet
- RdsDocument321 pagesRdsrajverma10in2002No ratings yet
- History of Computer GraphicsDocument24 pagesHistory of Computer GraphicsShubashish NiloyNo ratings yet
- Insecure Boot: Andrea Barisani - Head of Hardware SecurityDocument42 pagesInsecure Boot: Andrea Barisani - Head of Hardware SecurityFuck YoujNo ratings yet
- Optiplex 980 Tech GuideDocument51 pagesOptiplex 980 Tech GuidePhosika Sithisane100% (1)
- Amd Cdna WhitepaperDocument11 pagesAmd Cdna WhitepapermanoleeNo ratings yet
- Download Understanding Strategic Management Anthony Henry all chapterDocument67 pagesDownload Understanding Strategic Management Anthony Henry all chaptereric.ward851100% (2)
- Steve Plimpton Sandia National Labs Sjplimp@sandia - GovDocument77 pagesSteve Plimpton Sandia National Labs Sjplimp@sandia - GovGeorge Michael Alvarado LopezNo ratings yet
- DeepinMind NVR Hits 90% Alarm AccuracyDocument8 pagesDeepinMind NVR Hits 90% Alarm Accuracykunene07No ratings yet
- Puter - Power.user JanuaryDocument112 pagesPuter - Power.user January9W2DSLNo ratings yet
- 04-Administration Lync OnlineDocument52 pages04-Administration Lync OnlineJAVIALEX006No ratings yet
- Launcher LogDocument76 pagesLauncher LogAhmed BahriNo ratings yet
- Introduction To Massively Parallel ComputingDocument44 pagesIntroduction To Massively Parallel ComputingHunter Ashish ChaurasiaNo ratings yet
- IB CS HL Case Study TermsDocument4 pagesIB CS HL Case Study TermsSaihielBakshiNo ratings yet