You might also like
- Electrical Machines 3rd Edition - S. K. Bhattacharya PDFDocument113 pagesElectrical Machines 3rd Edition - S. K. Bhattacharya PDFajai_cseNo ratings yet
- British AirwaysDocument16 pagesBritish AirwaysRahat Ali100% (7)
- ML 7Document6 pagesML 7pratikn1406No ratings yet
- Retail Relay CaseDocument6 pagesRetail Relay CaseNishita AgrawalNo ratings yet
- D.A Lab Assignment-09: (NAME:RUDRASISH MISHRA) - (SECTION:IT-8) - (ROLL NO:1906649)Document12 pagesD.A Lab Assignment-09: (NAME:RUDRASISH MISHRA) - (SECTION:IT-8) - (ROLL NO:1906649)Rudrasish MishraNo ratings yet
- Code Documentation: Loading The PackagesDocument5 pagesCode Documentation: Loading The PackagesShashwat Patel mm19b053No ratings yet
- AFTERMIDCODEDocument12 pagesAFTERMIDCODERamesh DhamiNo ratings yet
- Rstudio Study Notes For PA 20181126Document6 pagesRstudio Study Notes For PA 20181126Trong Nghia VuNo ratings yet
- Assignment 5 - Logistic - RegressionDocument7 pagesAssignment 5 - Logistic - RegressionMariano ManuNo ratings yet
- Ps NewDocument9 pagesPs NewSowmyaNo ratings yet
- PSPPTDocument10 pagesPSPPTSowmyaNo ratings yet
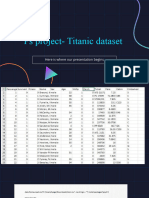
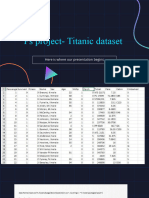
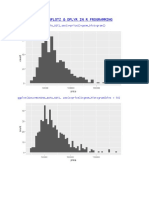
- Ps ProjectDocument6 pagesPs ProjectSowmyaNo ratings yet
- SOC 210 LabAssignment2Document1 pageSOC 210 LabAssignment2sfomutereNo ratings yet
- Data Science Programming Lab Assessment-6: Importing The Packages and Loading The DatasetDocument16 pagesData Science Programming Lab Assessment-6: Importing The Packages and Loading The DatasetKtm ChandruNo ratings yet
- Digital Assignment-6: Read The DataDocument30 pagesDigital Assignment-6: Read The DataPavan KarthikeyaNo ratings yet
- CodigoDocument6 pagesCodigoRoger Adrian Lopez BriceñoNo ratings yet
- Script Ejercicios Ggplot2Document1 pageScript Ejercicios Ggplot2Rodrigo Del Rio JoglarNo ratings yet
- Clodes Class Data ScienceDocument14 pagesClodes Class Data ScienceSantanu BoralNo ratings yet
- Probabilitas & Statsitika: Bayu Widodo, ST MTDocument8 pagesProbabilitas & Statsitika: Bayu Widodo, ST MTMuhammad Ilham NugrahaNo ratings yet
- Cse3506 - Essentials of Data Analytics: Logistic Regression AimDocument16 pagesCse3506 - Essentials of Data Analytics: Logistic Regression AimAbdul RaufNo ratings yet
- Caterpillar AssignmentDocument2 pagesCaterpillar AssignmentthirunavookarasuNo ratings yet
- Data Visualization Using R-ProgrammingDocument16 pagesData Visualization Using R-ProgrammingMahaboob BashaNo ratings yet
- HW1 Hadi AliDocument5 pagesHW1 Hadi Alikhmerboy100No ratings yet
- R CodeDocument3 pagesR Codebong hui chenNo ratings yet
- R NoteDocument56 pagesR NoteSuchismita SahuNo ratings yet
- Follow The Trend1.1Document11 pagesFollow The Trend1.1S Radhakrishna BhandaryNo ratings yet
- Library Library LibraryDocument3 pagesLibrary Library LibraryLina Paola CastañedaNo ratings yet
- Riska TianaDocument13 pagesRiska TianaRISKA TIANANo ratings yet
- CH 06Document7 pagesCH 06刘奕涵No ratings yet
- Logistic RegressionDocument1 pageLogistic RegressionRagulNo ratings yet
- DAV Practical 8Document3 pagesDAV Practical 8potake7704No ratings yet
- Fitting The Nelson-Siegel-Svensson Model With Differential EvolutionDocument10 pagesFitting The Nelson-Siegel-Svensson Model With Differential Evolutionhappy_24471No ratings yet
- IBDDocument5 pagesIBDGabriel DequigiovanniNo ratings yet
- (3.12) Exercise:: ObservationDocument1 page(3.12) Exercise:: ObservationSam ShankarNo ratings yet
- COVIDDocument4 pagesCOVIDPegasus indiaNo ratings yet
- Cengizhan SahinDocument26 pagesCengizhan Sahindummy accountNo ratings yet
- List of CodesDocument30 pagesList of CodesDipak SinghNo ratings yet
- R FunctionsDocument6 pagesR FunctionsShreya GhoshNo ratings yet
- Helium V 6.4.2 US30Document5 pagesHelium V 6.4.2 US30Himanshu HimanshuNo ratings yet
- EXP9 To EXP12 20BEC1351Document17 pagesEXP9 To EXP12 20BEC1351ASampath mihirNo ratings yet
- The Beta DistributionDocument11 pagesThe Beta DistributionawelNo ratings yet
- Clase1 R PEF (Final)Document3 pagesClase1 R PEF (Final)Juan Camilo ErasoNo ratings yet
- BDA Project CodesDocument20 pagesBDA Project CodesalyshaNo ratings yet
- 20bce1499 Cse3020 Lab-1Document11 pages20bce1499 Cse3020 Lab-1Venkataraman BalanandNo ratings yet
- Lab 5 EADocument4 pagesLab 5 EAAndrew TrejoNo ratings yet
- "Cps - TXT" "Education" "South" "SEX" "Experience" "Union" "WAGE" "AGE" "RACE" "Occupat Ion" "Sector" "MARR"Document9 pages"Cps - TXT" "Education" "South" "SEX" "Experience" "Union" "WAGE" "AGE" "RACE" "Occupat Ion" "Sector" "MARR"Alper Tamay ArslanNo ratings yet
- Praktikum IVDocument6 pagesPraktikum IVPujiyantiNo ratings yet
- Toc ch1Document9 pagesToc ch1Sahil SheteNo ratings yet
- VitorDocument61 pagesVitorVitor PereiraNo ratings yet
- FinalDocument25 pagesFinalAbdul-Basit Tanvir KhanNo ratings yet
- R Code ECON ProjDocument10 pagesR Code ECON ProjNora SoualhiNo ratings yet
- Re Pandas PD Glob Scipy - Cluster.hierarchy Matplotlib Shutil Os PathlibDocument2 pagesRe Pandas PD Glob Scipy - Cluster.hierarchy Matplotlib Shutil Os PathlibMarco LongobardiNo ratings yet
- 21bme145 Exp 4Document3 pages21bme145 Exp 421bme145No ratings yet
- ML Exp8Document3 pagesML Exp8godizlatanNo ratings yet
- Code 3Document6 pagesCode 3Nuriel AguilarNo ratings yet
- Tgarch 11Document2 pagesTgarch 11Raymond WidjajaNo ratings yet
- R ProgrammingDocument9 pagesR Programmingouahib.chafiai1No ratings yet
- Discrete Math Ass2Document3 pagesDiscrete Math Ass2phuongnha922017No ratings yet
- MA Directional TableDocument8 pagesMA Directional TableramaNo ratings yet
- ScnfinalDocument5 pagesScnfinalaryasNo ratings yet
- ML Lab CodesDocument14 pagesML Lab CodesThorNo ratings yet
- MFIS PostmidDocument11 pagesMFIS PostmidAkshara SharmaNo ratings yet
- Theory BADocument4 pagesTheory BAAkshara SharmaNo ratings yet
- 64ef02e4c2f9f HCCB FinanceDocument4 pages64ef02e4c2f9f HCCB FinanceThe ProfessorNo ratings yet
- Book 1Document1 pageBook 1Akshara SharmaNo ratings yet
- JV Punj Lloyd - SICIMDocument9 pagesJV Punj Lloyd - SICIMBarock NaturelNo ratings yet
- PDPR Bahasa Inggeris Tahun 5 12 July 2021 / MondayDocument12 pagesPDPR Bahasa Inggeris Tahun 5 12 July 2021 / MondayKiran KaurNo ratings yet
- Assignment#1: Water Engineering CEE-307Document7 pagesAssignment#1: Water Engineering CEE-307Muhammad ShahzaibNo ratings yet
- Credit Cards: Personal FinanceDocument36 pagesCredit Cards: Personal FinanceAmara MaduagwuNo ratings yet
- The Seventh Spark Knights of The TrinityDocument57 pagesThe Seventh Spark Knights of The TrinityNetNo ratings yet
- ePDQ DirectLink en OriginalDocument24 pagesePDQ DirectLink en Originalsoleone9378No ratings yet
- Rich Dad, Poor Dad What The Rich Teach Their Kids About Money - That The Poor and Middle Class Do Not by Robert T. Kiyosaki, Sharon L. LechterDocument130 pagesRich Dad, Poor Dad What The Rich Teach Their Kids About Money - That The Poor and Middle Class Do Not by Robert T. Kiyosaki, Sharon L. LechternuonuoluNo ratings yet
- 2014.03.27 Volume 2 Design ENDocument134 pages2014.03.27 Volume 2 Design ENSalman KaziNo ratings yet
- 8MA0 21 Que 20211014Document16 pages8MA0 21 Que 20211014S1mple GamingNo ratings yet
- Topic 7. X-Ray, Luminescent and Transilluminating Diagnostics: The Indication ToDocument2 pagesTopic 7. X-Ray, Luminescent and Transilluminating Diagnostics: The Indication ToHERO RescueNo ratings yet
- Smed PDFDocument10 pagesSmed PDFSakline MinarNo ratings yet
- Human Cloning - Another YouDocument17 pagesHuman Cloning - Another Youpratyushkarn100% (1)
- Witches Loaves Analysis PrejudiceDocument2 pagesWitches Loaves Analysis PrejudiceNaveenGowdaBangloreNo ratings yet
- Doorsopenforforeign Univs 4-Yrugwithexit Option, Flexiblemaster'SDocument18 pagesDoorsopenforforeign Univs 4-Yrugwithexit Option, Flexiblemaster'SPranesh RamalingamNo ratings yet
- Financial CrisisDocument53 pagesFinancial CrisisMehedi Hassan RanaNo ratings yet
- Fiche Eleves Saint PatrickDocument10 pagesFiche Eleves Saint PatrickAndreea MarcinNo ratings yet
- ISO 19011 - 2018 WhitepaperDocument14 pagesISO 19011 - 2018 WhitepaperJORGE MEJIA100% (1)
- Dip Obst (SA) Past Papers - 2020 1st Semester 1-6-2023Document1 pageDip Obst (SA) Past Papers - 2020 1st Semester 1-6-2023Neo Latoya MadunaNo ratings yet
- Public Health ResearchDocument124 pagesPublic Health ResearchAsmitNo ratings yet
- Hull Cut Off Equation Electron Motion in Cylindrical MagnetronDocument6 pagesHull Cut Off Equation Electron Motion in Cylindrical Magnetronkalalala0186% (7)
- Lesson PlanDocument6 pagesLesson Plannurulhuda287No ratings yet
- Sbo43sp2 Whats New enDocument14 pagesSbo43sp2 Whats New enPierreNo ratings yet
- Present Value, Annuity, and PerpetuityDocument42 pagesPresent Value, Annuity, and PerpetuityEdwin OctorizaNo ratings yet
- 20th Century Arch'ReDocument6 pages20th Century Arch'ReRachelleGomezLatrasNo ratings yet
- Enforcement Question 3Document2 pagesEnforcement Question 3Tan Chen WuiNo ratings yet
- BSC It Syllabus Mumbai UniversityDocument81 pagesBSC It Syllabus Mumbai UniversitysanNo ratings yet
- Municipality of Paniqui Term PaperDocument23 pagesMunicipality of Paniqui Term PaperNhevia de GuzmanNo ratings yet
- AssignmentDocument6 pagesAssignmentAkshay MehtaNo ratings yet