You might also like
- IA Student Guide 2022Document10 pagesIA Student Guide 2022Miguel CarriquiryNo ratings yet
- How To Get Your PMP Application Approved On Your First Try PDFDocument21 pagesHow To Get Your PMP Application Approved On Your First Try PDFHung Nguyen Van100% (3)
- Programming Languages Research ReportDocument16 pagesProgramming Languages Research ReportdasmooveNo ratings yet
- Robust Design TaguchiDocument14 pagesRobust Design TaguchivinviaNo ratings yet
- Testing of TranformerDocument7 pagesTesting of Tranformerkanchan206100% (1)
- Netsuite GlossaryDocument42 pagesNetsuite Glossarymiguel barrosNo ratings yet
- Easy Mikrotik HotSpot SetupDocument5 pagesEasy Mikrotik HotSpot SetupBoy EloadNo ratings yet
- Object-Oriented Concepts For Database Design: Michael R. Blaha and William J. PremerlaniDocument9 pagesObject-Oriented Concepts For Database Design: Michael R. Blaha and William J. PremerlanikadalmonNo ratings yet
- Assessment ResultsDocument9 pagesAssessment Resultsabid100% (1)
- TC6 PROJECT SYNOPSIS KrishShetty VedantLandge 231106 101402Document13 pagesTC6 PROJECT SYNOPSIS KrishShetty VedantLandge 231106 101402Geeta patilNo ratings yet
- Neptune - Ai Hugging Face Pre-Trained ModelsDocument14 pagesNeptune - Ai Hugging Face Pre-Trained ModelsLeonNo ratings yet
- PaigeDocument17 pagesPaigeSHUBHAM POLNo ratings yet
- Ai Resume AnalyzerDocument13 pagesAi Resume Analyzersandeepghodeswar86No ratings yet
- Pos Thesis DocumentationDocument7 pagesPos Thesis Documentationpattyjosephpittsburgh100% (1)
- Software Development Thesis SampleDocument5 pagesSoftware Development Thesis Sampledqaucoikd100% (2)
- Java Interview QuestionsDocument8 pagesJava Interview QuestionsMeek KeeNo ratings yet
- Research ApproachDocument9 pagesResearch ApproachNoman Ahmed DayoNo ratings yet
- FirstTwounitsNotes OOSD (16oct23)Document97 pagesFirstTwounitsNotes OOSD (16oct23)Shreshtha RastogiNo ratings yet
- 40+ OOPs Interview Questions and Answers (2024) - InterviewBitDocument32 pages40+ OOPs Interview Questions and Answers (2024) - InterviewBitPardeep swamiNo ratings yet
- Vejin Hussein Younis, OopDocument11 pagesVejin Hussein Younis, OopVejiin KurdiNo ratings yet
- OOPS Interview QuestionsDocument17 pagesOOPS Interview Questionspaparos486No ratings yet
- Agile Software Development CDocument17 pagesAgile Software Development CAhsan ChNo ratings yet
- Section 1 Object Oriented Analysis and Design Lab: Structure Page NosDocument27 pagesSection 1 Object Oriented Analysis and Design Lab: Structure Page NosRamNo ratings yet
- Basic OOPs Interview QuestionsDocument17 pagesBasic OOPs Interview QuestionsJayant PawarNo ratings yet
- Teaching Formal Methods With Perfect DeveloperDocument4 pagesTeaching Formal Methods With Perfect Developerankitaverma82No ratings yet
- Object Oriented ProgrammingDocument5 pagesObject Oriented ProgrammingmandikianablessingNo ratings yet
- Ieee Research Papers On Natural Language Processing Filetype PDFDocument4 pagesIeee Research Papers On Natural Language Processing Filetype PDFkkxtkqundNo ratings yet
- (VI12241) Legal Case SummarizationDocument2 pages(VI12241) Legal Case SummarizationSAHITHI NALLANo ratings yet
- Notes Oopm Unit 1Document38 pagesNotes Oopm Unit 1elishasupreme30No ratings yet
- Evolution of OOP: Problem Solving in OO ParadigmDocument3 pagesEvolution of OOP: Problem Solving in OO ParadigmSarah Fatima100% (1)
- Chatbot and Text SummarizationDocument5 pagesChatbot and Text SummarizationBRAHMINo ratings yet
- Service-Oriented Architecture: Prof Ehab E. Hassanien Dr. Dina EzzatDocument14 pagesService-Oriented Architecture: Prof Ehab E. Hassanien Dr. Dina EzzatMuhammed AbdallahNo ratings yet
- ML Projects For Final YearDocument7 pagesML Projects For Final YearAlia KhanNo ratings yet
- Modern Object-Oriented Software DevelopmentDocument13 pagesModern Object-Oriented Software DevelopmentNirmal PatleNo ratings yet
- Software Development Thesis IdeasDocument8 pagesSoftware Development Thesis Ideasuxgzruwff100% (2)
- Software Development Thesis PDFDocument7 pagesSoftware Development Thesis PDFdianawalkermilwaukee100% (2)
- QU Master ProjectDocument6 pagesQU Master ProjectAndriyan SaputraNo ratings yet
- Resume Parser ProgressDocument11 pagesResume Parser ProgressLouis OdhiamboNo ratings yet
- MCSL 036 Lab ManualDocument52 pagesMCSL 036 Lab Manualjrajesh50% (1)
- Structured Programming Vs Object OrientedDocument10 pagesStructured Programming Vs Object OrientedMustafa100% (1)
- UQ Healthcare ProjectDocument5 pagesUQ Healthcare ProjectAndriyan SaputraNo ratings yet
- List of Topics For Research Paper in Software EngineeringDocument8 pagesList of Topics For Research Paper in Software Engineeringcaq5kzrgNo ratings yet
- QUT Capstone ProjectDocument5 pagesQUT Capstone ProjectAndriyan SaputraNo ratings yet
- 02 2 Progamming Paradigms - StudentvDocument6 pages02 2 Progamming Paradigms - StudentvDaina McKenzieNo ratings yet
- Thesis Software DevelopmentDocument4 pagesThesis Software DevelopmentHelpWritingACollegePaperArlington100% (1)
- Face Recognition Literature ReviewDocument7 pagesFace Recognition Literature Reviewea53sm5w100% (1)
- Oops PDFDocument27 pagesOops PDFRohit KhannaNo ratings yet
- Hostel Management System Project Literature ReviewDocument7 pagesHostel Management System Project Literature Reviewea6p1e99No ratings yet
- Advantages of OOPDocument3 pagesAdvantages of OOPMouniNo ratings yet
- 1.1introduction To Project: 1.2 Objective and Scope of Project ObjectiveDocument11 pages1.1introduction To Project: 1.2 Objective and Scope of Project ObjectiveAbhishek ChavanNo ratings yet
- Research Paper On Machine LearningDocument7 pagesResearch Paper On Machine Learningjbuulqvkg100% (1)
- CheatDocument8 pagesCheatGUCI NKCNo ratings yet
- Unit-Ii - SeDocument25 pagesUnit-Ii - SevivekparasharNo ratings yet
- Unit - 1: Introduction To Object Oriented ProgrammingDocument19 pagesUnit - 1: Introduction To Object Oriented ProgrammingMUdit TiWariNo ratings yet
- PAPER PUBLISH - EditedDocument9 pagesPAPER PUBLISH - EditedKranti SriNo ratings yet
- Govt. Murray College Sialkot: Software EngineeringDocument5 pagesGovt. Murray College Sialkot: Software EngineeringMian Talha RiazNo ratings yet
- Student Result SystemDocument12 pagesStudent Result Systemgayan wickramarathnaNo ratings yet
- Oop L-1Document13 pagesOop L-1Habiba ShifaNo ratings yet
- Programming Patterns and Design Patterns in The Introductory Computer Science CourseDocument5 pagesProgramming Patterns and Design Patterns in The Introductory Computer Science Courseウズマキ ナルトNo ratings yet
- Lakera - Ai-The Ultimate Guide To LLM Fine Tuning Best Practices Amp ToolsDocument13 pagesLakera - Ai-The Ultimate Guide To LLM Fine Tuning Best Practices Amp Toolsuday samalaNo ratings yet
- Research Papers On Software Design PatternsDocument5 pagesResearch Papers On Software Design Patternsefecep7d100% (1)
- OopusingcDocument9 pagesOopusingcapi-213911742No ratings yet
- CPP With Oop NotesDocument64 pagesCPP With Oop NotesFor RewardsNo ratings yet
- Java ProgrammingDocument6 pagesJava Programminggayathri90No ratings yet
- Experiment No. 1: Name: Juili Maruti Kadu Te A Roll No: 19 UID: 118CP1102B Sub: Software EngineeringDocument32 pagesExperiment No. 1: Name: Juili Maruti Kadu Te A Roll No: 19 UID: 118CP1102B Sub: Software EngineeringJuili KNo ratings yet
- SAP FI/CO (Finance and Controlling) Notes Version: SAP 6.0 ECC ECC: Enterprise Central ComponentDocument203 pagesSAP FI/CO (Finance and Controlling) Notes Version: SAP 6.0 ECC ECC: Enterprise Central ComponentCarlos GrossiNo ratings yet
- X.509 and Its NeedDocument21 pagesX.509 and Its NeedDhirBagulNo ratings yet
- Catalogo ImportsumaryDocument50 pagesCatalogo ImportsumaryMatthew EnglandNo ratings yet
- Lotus Notes Shortcut KeyDocument2 pagesLotus Notes Shortcut KeydatdNo ratings yet
- Amiga 3000T Service ManualDocument16 pagesAmiga 3000T Service ManualexileofanubisNo ratings yet
- 1.2D Viewing TransformationsDocument127 pages1.2D Viewing TransformationsAbhigyan HarshaNo ratings yet
- Lecture 1 of 5Document30 pagesLecture 1 of 5awangpaker xxNo ratings yet
- ZW3D CAD Tips How To Design A A Popular QQ DollDocument10 pagesZW3D CAD Tips How To Design A A Popular QQ DollAbu Mush'ab Putra HaltimNo ratings yet
- Ds 1621Document16 pagesDs 1621AnassFouadNo ratings yet
- C++11 Is A Version of The Standard For The ProgrammingDocument56 pagesC++11 Is A Version of The Standard For The ProgrammingYvzNo ratings yet
- Back-UPS®RS BR400G-JP & 550G-JPDocument8 pagesBack-UPS®RS BR400G-JP & 550G-JPcezarignatNo ratings yet
- Manual Druck DPI 145Document150 pagesManual Druck DPI 145Tarcio CarvalhoNo ratings yet
- 50+ Data Analysis Projects With Python by Aman Kharwal MediumDocument12 pages50+ Data Analysis Projects With Python by Aman Kharwal Mediumpradito_bhimoNo ratings yet
- GE Mac 400 - Quick GuideDocument7 pagesGE Mac 400 - Quick GuideEduard Stiven MarinNo ratings yet
- Digitalk: An Analysis of Linguistic Features and Their Functions in Filipino Computer-Mediated CommunicationDocument6 pagesDigitalk: An Analysis of Linguistic Features and Their Functions in Filipino Computer-Mediated CommunicationEvan UmaliNo ratings yet
- Midterm Replacement (Jasrey Raznizar Bin Eriansah)Document6 pagesMidterm Replacement (Jasrey Raznizar Bin Eriansah)JASREY RAZNIZAR BIN ERIANSAHNo ratings yet
- Pioneer HDD/DVD Recorder DVR-550H-SDocument142 pagesPioneer HDD/DVD Recorder DVR-550H-SdesNo ratings yet
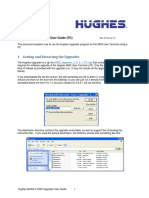
- Hughes 9502 Upgrader User Instructions PC v3.5 0Document7 pagesHughes 9502 Upgrader User Instructions PC v3.5 0Derek RogerNo ratings yet
- Alienware 17 R4 Service Manual: Computer Model: Alienware 17 R4 Regulatory Model: P31E Regulatory Type: P31E001Document133 pagesAlienware 17 R4 Service Manual: Computer Model: Alienware 17 R4 Regulatory Model: P31E Regulatory Type: P31E001Diki Fernando SaputraNo ratings yet
- CH 1Document24 pagesCH 1Chew Ting LiangNo ratings yet
- GCE Advanced Level - ICT - தரவுத்தள முகாமைத்துவ முறைமைDocument57 pagesGCE Advanced Level - ICT - தரவுத்தள முகாமைத்துவ முறைமைThanuNo ratings yet
- Manual EncoderDocument4 pagesManual EncoderDoc_LACNo ratings yet
- Jet Airways Web Booking ETicket (YFHOWT) - Puthiya VeetilDocument3 pagesJet Airways Web Booking ETicket (YFHOWT) - Puthiya VeetilpetrishiaNo ratings yet