You might also like
- WizardLM - Empowering Large Language Models To Follow Complex InstructionsDocument39 pagesWizardLM - Empowering Large Language Models To Follow Complex InstructionswilhelmjungNo ratings yet
- HuggingGPT: Solving AI Tasks With ChatGPT and Its Friends in HuggingFaceDocument18 pagesHuggingGPT: Solving AI Tasks With ChatGPT and Its Friends in HuggingFaceGábor UjhelyiNo ratings yet
- ChatGPT KZ Feb2023 PDFDocument7 pagesChatGPT KZ Feb2023 PDFsamuel asefaNo ratings yet
- Compact Guide To Large Language ModelsDocument9 pagesCompact Guide To Large Language ModelsKashif KhanNo ratings yet
- Oracle Certification All Exam - Certifications - OracleDocument6 pagesOracle Certification All Exam - Certifications - OracleDavid 7890% (5)
- 1z0-066.exam: Number: 1z0-066 Passing Score: 800 Time Limit: 120 Min File Version: 1Document64 pages1z0-066.exam: Number: 1z0-066 Passing Score: 800 Time Limit: 120 Min File Version: 1Rosa Jiménez100% (1)
- Sap Fi Aa BBP DocumentDocument86 pagesSap Fi Aa BBP Documentsanjusivan100% (1)
- Wireless Sensor and Actuator NetworksDocument170 pagesWireless Sensor and Actuator NetworksakelionNo ratings yet
- POS and Inventory System Chapter 2 TemplateDocument5 pagesPOS and Inventory System Chapter 2 TemplateMuhammad Azim B. ShahidNo ratings yet
- TrueNAS 9.2.1.8 Administrator GuideDocument201 pagesTrueNAS 9.2.1.8 Administrator GuideMohamad Reza NazariNo ratings yet
- Copie de Restaurants Email ListDocument249 pagesCopie de Restaurants Email ListbilletonNo ratings yet
- 29920-Article Text-33974-1-2-20240324Document9 pages29920-Article Text-33974-1-2-20240324cfif20000612No ratings yet
- Intern LMDocument18 pagesIntern LMPeng LiNo ratings yet
- Llava 2304.08485Document19 pagesLlava 2304.08485arjun22_c3794No ratings yet
- Applsci 11 10915 v2Document17 pagesApplsci 11 10915 v2Bemenet BiniyamNo ratings yet
- Multi ModalDocument25 pagesMulti ModalSira juddinNo ratings yet
- A Comparison of Programming Languages in Economics (16-Jun-2014)Document16 pagesA Comparison of Programming Languages in Economics (16-Jun-2014)2023mc21517No ratings yet
- PoliMi-FlatEarthers at CheckThat! 2022: GPT-3 Applied To Claim DetectionDocument6 pagesPoliMi-FlatEarthers at CheckThat! 2022: GPT-3 Applied To Claim Detection64vn82fdgtNo ratings yet
- Unleashing The Power of Large Language Models FauberDocument4 pagesUnleashing The Power of Large Language Models FaubergoswamiuwuNo ratings yet
- NeurIPS 2020 Language Models Are Few Shot Learners PaperDocument25 pagesNeurIPS 2020 Language Models Are Few Shot Learners PaperBarqueros libros y papeleríaNo ratings yet
- 2021 Naacl-Main 185Document14 pages2021 Naacl-Main 185trimble2No ratings yet
- SMART: Robust and E Fficient Fine-Tuning For Pre-Trained Natural Language Models Through Principled Regularized OptimizationDocument21 pagesSMART: Robust and E Fficient Fine-Tuning For Pre-Trained Natural Language Models Through Principled Regularized OptimizationsamsNo ratings yet
- Sasha Rush - Interactive and Visual Prompt EngineeringDocument11 pagesSasha Rush - Interactive and Visual Prompt EngineeringGugo ManNo ratings yet
- Large Language ModelDocument38 pagesLarge Language Model21020641No ratings yet
- Data PipelineDocument7 pagesData Pipelinewujunda666No ratings yet
- DistilBERT, A Distilled Version of BERT: Smaller, Faster, Cheaper and LighterDocument5 pagesDistilBERT, A Distilled Version of BERT: Smaller, Faster, Cheaper and LighterAakash VermaNo ratings yet
- 2 - 23 - A Survey of Vision-Language Pre-Training From The Lens of Multimodal Machine TranslationDocument10 pages2 - 23 - A Survey of Vision-Language Pre-Training From The Lens of Multimodal Machine TranslationPhạm Thanh TrườngNo ratings yet
- A Case Study On Prompt Engineering For Job Type ClassificationDocument16 pagesA Case Study On Prompt Engineering For Job Type ClassificationGuz KoutNo ratings yet
- This Item Is The Archived Peer-Reviewed Author-Version ofDocument16 pagesThis Item Is The Archived Peer-Reviewed Author-Version ofLeul ChanieNo ratings yet
- General-Purpose Multiparadigm Programming Languages: An Enabling Technology For Constructing Complex SystemsDocument8 pagesGeneral-Purpose Multiparadigm Programming Languages: An Enabling Technology For Constructing Complex SystemspostscriptNo ratings yet
- Minigpt-4 Enhancing Vision-Language Understanding With Advanced Large Language ModelsDocument15 pagesMinigpt-4 Enhancing Vision-Language Understanding With Advanced Large Language Modelsyym68686No ratings yet
- mt5 A Massively Multilingual Pre Trained Text To Text 9iojxtx56wDocument16 pagesmt5 A Massively Multilingual Pre Trained Text To Text 9iojxtx56wAbhishek JunghareNo ratings yet
- Mcs 024Document308 pagesMcs 024Rumita SenguptaNo ratings yet
- Kalyan 1 s2.0 S2949719123000456 MainDocument48 pagesKalyan 1 s2.0 S2949719123000456 MainjitterNo ratings yet
- Thesis On Internationalization ProcessDocument5 pagesThesis On Internationalization Processshaunajoysaltlakecity100% (1)
- C Programming CourseworkDocument6 pagesC Programming Courseworkafiwgjbkp100% (1)
- PlansformerDocument44 pagesPlansformeriamsamrajneeNo ratings yet
- Computers & Industrial Engineering: Ching-Ter Chang, Huang-Mu Chen, Zheng-Yun ZhuangDocument8 pagesComputers & Industrial Engineering: Ching-Ter Chang, Huang-Mu Chen, Zheng-Yun Zhuangtan phamNo ratings yet
- Cramming: Training A Language Model On A Single GPU in One Day (2022)Document27 pagesCramming: Training A Language Model On A Single GPU in One Day (2022)Salvation TivaNo ratings yet
- 17 Digi Comp FrameworksDocument11 pages17 Digi Comp FrameworksRaffaella CirilloNo ratings yet
- 2022 wmt-1 3Document31 pages2022 wmt-1 3ay noNo ratings yet
- Financial Markets Prediction With Deep LearningDocument8 pagesFinancial Markets Prediction With Deep LearningMarcus ViniciusNo ratings yet
- Language Models Are Unsupervised Multitask LearnersDocument24 pagesLanguage Models Are Unsupervised Multitask LearnersGabrielNo ratings yet
- Journal of Economic Dynamics & Control: S. Borağan Aruoba, Jesús Fernández-VillaverdeDocument9 pagesJournal of Economic Dynamics & Control: S. Borağan Aruoba, Jesús Fernández-VillaverdeHHHNo ratings yet
- (2023) Scaling DistillingDocument27 pages(2023) Scaling Distillingpolygalaceae0730No ratings yet
- Principles For Modeling Language Design: Richard F. Paige, Jonathan S. Ostroff, Phillip J. BrookeDocument23 pagesPrinciples For Modeling Language Design: Richard F. Paige, Jonathan S. Ostroff, Phillip J. BrookeAlexBurton21No ratings yet
- 5 Benchmarking Machine Learning Software andDocument22 pages5 Benchmarking Machine Learning Software andllsloiNo ratings yet
- P G - C 2: B L L M C R F: AN U Oder Oosting Arge Anguage Odels For Ode With Anking EedbackDocument15 pagesP G - C 2: B L L M C R F: AN U Oder Oosting Arge Anguage Odels For Ode With Anking EedbackhsgarrossNo ratings yet
- Multi-Task Sequence To Sequence LearningDocument10 pagesMulti-Task Sequence To Sequence LearningShri KrishnaNo ratings yet
- Hugginggpt: Solving Ai Tasks With Chatgpt and Its Friends in Hugging FaceDocument18 pagesHugginggpt: Solving Ai Tasks With Chatgpt and Its Friends in Hugging FaceLéo GiammarinaroNo ratings yet
- The State-Of-Art Applications of NLP: Evidence From ChatGPTDocument7 pagesThe State-Of-Art Applications of NLP: Evidence From ChatGPTMagno MacielNo ratings yet
- Research Paper On Linear ProgrammingDocument6 pagesResearch Paper On Linear Programmingtrsrpyznd100% (3)
- Big Data Analytics (BDA) : Name of The Faculty: Affiliation: Teaching AreaDocument8 pagesBig Data Analytics (BDA) : Name of The Faculty: Affiliation: Teaching AreaSai GaneshNo ratings yet
- 1 s2.0 S2095809922006324 MainDocument20 pages1 s2.0 S2095809922006324 MainJuan ZarateNo ratings yet
- Genai PrinciplesDocument12 pagesGenai Principlesgawihe2261No ratings yet
- Organisation: Statistics Norway Author(s) : Thivyesh Ahilathasan, Tatsiana Pekarskaya Date: 07.02.2020Document7 pagesOrganisation: Statistics Norway Author(s) : Thivyesh Ahilathasan, Tatsiana Pekarskaya Date: 07.02.2020vinceNo ratings yet
- Thesis LLMsForDocVQADocument29 pagesThesis LLMsForDocVQAThrow AwayNo ratings yet
- 2022 Emnlp-Demos 40Document10 pages2022 Emnlp-Demos 40Insaf KraidiaNo ratings yet
- Hugginggpt: Solving Ai Tasks With Chatgpt and Its Friends in Hugging FaceDocument27 pagesHugginggpt: Solving Ai Tasks With Chatgpt and Its Friends in Hugging Faceddurkee83No ratings yet
- PPL223 Module2and3 Gemma+GibagaDocument10 pagesPPL223 Module2and3 Gemma+GibagaSophia AntonioNo ratings yet
- Paint Industry - Product Mix PDFDocument10 pagesPaint Industry - Product Mix PDFHarsh SaxenaNo ratings yet
- Layout XLMDocument10 pagesLayout XLMVaroonNo ratings yet
- Evaluating Next Generation NLG Models For Graph To Text Generation With Fine-Tuning Vs Generalized Model For Longer Generated TextsDocument5 pagesEvaluating Next Generation NLG Models For Graph To Text Generation With Fine-Tuning Vs Generalized Model For Longer Generated TextsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Scaling (Down) CLIP A Comprehensive Analysis of Data, Architecture, and Training StrategiesDocument19 pagesScaling (Down) CLIP A Comprehensive Analysis of Data, Architecture, and Training StrategiesKiên Dương NgôNo ratings yet
- 2021 Multilingual-T5 Xue-GoogleDocument17 pages2021 Multilingual-T5 Xue-Googlerajesh716No ratings yet
- Milmo:Minority Multilingual Pre-Trained Language ModelDocument7 pagesMilmo:Minority Multilingual Pre-Trained Language ModelbilletonNo ratings yet
- Conti Inc.: Understanding The Internal Discussions of A Large Ransomware-as-a-Service Operator With Machine LearningDocument10 pagesConti Inc.: Understanding The Internal Discussions of A Large Ransomware-as-a-Service Operator With Machine LearningbilletonNo ratings yet
- Business Process Text Sketch Automation Generation Using Large Language ModelDocument10 pagesBusiness Process Text Sketch Automation Generation Using Large Language ModelbilletonNo ratings yet
- B C: A Benchmark For Bioinformatics Code Generation With Contextual Pragmatic KnowledgeDocument72 pagesB C: A Benchmark For Bioinformatics Code Generation With Contextual Pragmatic KnowledgebilletonNo ratings yet
- Towards Spontaneous Style Modeling With Semi-Supervised Pre-Training For Conversational Text-to-Speech SynthesisDocument5 pagesTowards Spontaneous Style Modeling With Semi-Supervised Pre-Training For Conversational Text-to-Speech SynthesisbilletonNo ratings yet
- Toddlerberta: Exploiting Babyberta For Grammar Learning and Language UnderstandingDocument10 pagesToddlerberta: Exploiting Babyberta For Grammar Learning and Language UnderstandingbilletonNo ratings yet
- BLSP: B L - S P - B A C - W: Ootstrapping Anguage Peech RE Training Via Ehavior Lignment of Ontinu Ation RitingDocument11 pagesBLSP: B L - S P - B A C - W: Ootstrapping Anguage Peech RE Training Via Ehavior Lignment of Ontinu Ation RitingbilletonNo ratings yet
- Knowledge Distillation From Non-Streaming To Streaming ASR Encoder Using Auxiliary Non-Streaming LayerDocument5 pagesKnowledge Distillation From Non-Streaming To Streaming ASR Encoder Using Auxiliary Non-Streaming LayerbilletonNo ratings yet
- Link Prediction For Wikipedia Articles As A Natural Language Inference TaskDocument4 pagesLink Prediction For Wikipedia Articles As A Natural Language Inference TaskbilletonNo ratings yet
- Generalised Winograd Schema and Its Contextuality: Kin Ian Lo Mehrnoosh Sadrzadeh Shane MansfieldDocument16 pagesGeneralised Winograd Schema and Its Contextuality: Kin Ian Lo Mehrnoosh Sadrzadeh Shane MansfieldbilletonNo ratings yet
- Knowledge-Grounded Natural Language Recommendation ExplanationDocument15 pagesKnowledge-Grounded Natural Language Recommendation ExplanationbilletonNo ratings yet
- Mera: Merging Pretrained Adapters For Few-Shot LearningDocument6 pagesMera: Merging Pretrained Adapters For Few-Shot LearningbilletonNo ratings yet
- Towards One-Shot Learning For Text Classification Using Inductive Logic ProgrammingDocument11 pagesTowards One-Shot Learning For Text Classification Using Inductive Logic ProgrammingbilletonNo ratings yet
- LL SM: L L S M: A Arge Anguage and Peech OdelDocument8 pagesLL SM: L L S M: A Arge Anguage and Peech OdelbilletonNo ratings yet
- The Nordic Pile: A 1.2TB Nordic Dataset For Language ModelingDocument14 pagesThe Nordic Pile: A 1.2TB Nordic Dataset For Language ModelingbilletonNo ratings yet
- Linktransformer:: A Unified Package For Record Linkage With Transformer Language ModelsDocument16 pagesLinktransformer:: A Unified Package For Record Linkage With Transformer Language ModelsbilletonNo ratings yet
- Lm-I: S O - F L G - L L M: Nfinite Imple N THE LY Ength Ener Alization For Arge Anguage OdelsDocument14 pagesLm-I: S O - F L G - L L M: Nfinite Imple N THE LY Ength Ener Alization For Arge Anguage OdelsbilletonNo ratings yet
- SPDX1Document21 pagesSPDX1billetonNo ratings yet
- P T P: U F A A L L - M: Eering Hrough References Nraveling Eedback Cquisition For Ligning Arge AN Guage OdelsDocument24 pagesP T P: U F A A L L - M: Eering Hrough References Nraveling Eedback Cquisition For Ligning Arge AN Guage OdelsbilletonNo ratings yet
- FPTQ: F - P - T Q - L L M: INE Grained OST Raining Uantiza Tion For Arge Anguage OdelsDocument17 pagesFPTQ: F - P - T Q - L L M: INE Grained OST Raining Uantiza Tion For Arge Anguage OdelsbilletonNo ratings yet
- Quantifying and Analyzing Entity-Level Memorization in Large Language ModelsDocument9 pagesQuantifying and Analyzing Entity-Level Memorization in Large Language ModelsbilletonNo ratings yet
- Task-Based Moe For Multitask Multilingual Machine TranslationDocument11 pagesTask-Based Moe For Multitask Multilingual Machine TranslationbilletonNo ratings yet
- Tronik Data BankDocument35 pagesTronik Data BankbilletonNo ratings yet
- Hugva Usd Price ListDocument1 pageHugva Usd Price ListbilletonNo ratings yet
- Nandani Product ListDocument8 pagesNandani Product ListbilletonNo ratings yet
- 2020 Golden Rose Price List-1Document6 pages2020 Golden Rose Price List-1billetonNo ratings yet
- 2308 16474Document6 pages2308 16474billetonNo ratings yet
- Twosisters OODocument1 pageTwosisters OObilletonNo ratings yet
- Tarjeta BitcoinDocument2 pagesTarjeta BitcoinbilletonNo ratings yet
- Machine Learning For Kids:: Teachers' Notes: SetupDocument1 pageMachine Learning For Kids:: Teachers' Notes: SetupSamer MaaraouiNo ratings yet
- Operation Spy Cloud - EngDocument21 pagesOperation Spy Cloud - EngDavis MallyaNo ratings yet
- 12 Link AnalysisDocument47 pages12 Link AnalysisBenny Sukma NegaraNo ratings yet
- Snowflake MLPFDocument7 pagesSnowflake MLPFjahnavi208No ratings yet
- What Is The Best Video Generator From TextDocument10 pagesWhat Is The Best Video Generator From TextJames SakuraiNo ratings yet
- EN Marius Costache CVDocument2 pagesEN Marius Costache CVMarius GCNo ratings yet
- Aix ChecklistDocument1 pageAix ChecklistgnpaulNo ratings yet
- 14 Creating Dictionaries: 13.8 Custom Sample File RequiredDocument5 pages14 Creating Dictionaries: 13.8 Custom Sample File RequiredAlojaaNo ratings yet
- 2 Exercises On ConcurrencyDocument15 pages2 Exercises On ConcurrencyMaico XuriNo ratings yet
- Unit 1: Course Introduction: Week 1: Core Planning CapabilitiesDocument7 pagesUnit 1: Course Introduction: Week 1: Core Planning CapabilitiesRamesh PagidalaNo ratings yet
- Setting Up FRITZ!App Fon FRITZ!App Fon AVM InternationalDocument8 pagesSetting Up FRITZ!App Fon FRITZ!App Fon AVM InternationalMango110No ratings yet
- Exchange Server 2010 Introduction To Supporting AdministrationDocument78 pagesExchange Server 2010 Introduction To Supporting AdministrationRazdolbaitusNo ratings yet
- UnitTesting TechniquesDocument53 pagesUnitTesting TechniquesBurlacu LucianNo ratings yet
- Suprema Access Control 2015 enDocument32 pagesSuprema Access Control 2015 enLuis Zelada VargasNo ratings yet
- Julian Anderson: About MeDocument2 pagesJulian Anderson: About Mesira1No ratings yet
- Rockbox Round: Full ManualDocument7 pagesRockbox Round: Full ManualCasanova ReloadedNo ratings yet
- Poly CCX Business Media Phones With Microsoft Teams: User GuideDocument17 pagesPoly CCX Business Media Phones With Microsoft Teams: User GuideAnthony VoNo ratings yet
- VTU Model Question Papers VI Sem ECE - TCEDocument44 pagesVTU Model Question Papers VI Sem ECE - TCEMr Ashutosh SrivastavaNo ratings yet
- Graham - Denning Security Model - DushanthaDocument12 pagesGraham - Denning Security Model - Dushanthaericpush1No ratings yet
- MCQ - 26 PDFDocument6 pagesMCQ - 26 PDFNida Bagoyboy NatichoNo ratings yet
- Dell 1908fpcDocument79 pagesDell 1908fpcIstván GerencsérNo ratings yet
- Grade 7 & 8 Curriculum MapDocument13 pagesGrade 7 & 8 Curriculum MapRussell SanicoNo ratings yet
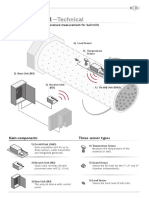
- KIMA SmartFill TechnicalDocument6 pagesKIMA SmartFill Technicalyoussef tabetNo ratings yet
- Software Platform".: Common Language Runtime (CLR)Document4 pagesSoftware Platform".: Common Language Runtime (CLR)Himawan_Budi_L_7947No ratings yet