You might also like
- Systematic Reviews and Meta-AnalysesDocument3 pagesSystematic Reviews and Meta-AnalysesRifat HasanNo ratings yet
- Markov Siebert ISPOR SMDM Task Force 2012Document9 pagesMarkov Siebert ISPOR SMDM Task Force 2012JulivaiNo ratings yet
- Meta Analysis Nursing Literature ReviewDocument10 pagesMeta Analysis Nursing Literature Reviewea46krj6100% (1)
- Implant Supported ProsthesisDocument3 pagesImplant Supported ProsthesisAmar BhochhibhoyaNo ratings yet
- Literature Review BMJDocument8 pagesLiterature Review BMJc5qwqy8v100% (1)
- Evidence Based Medicine!: The Objectives of This Tutorial AreDocument3 pagesEvidence Based Medicine!: The Objectives of This Tutorial AreWildan MentalisNo ratings yet
- Rapid Response Teams: Is It Time To Reframe The Questions of Rapid Response Team Measurement?Document9 pagesRapid Response Teams: Is It Time To Reframe The Questions of Rapid Response Team Measurement?Syamsuryadi AdheNo ratings yet
- A Critical Realist Guide To Developing Theory With Systematic Literature ReviewsDocument4 pagesA Critical Realist Guide To Developing Theory With Systematic Literature Reviewsc5rh6rasNo ratings yet
- Jeehp 10 12Document7 pagesJeehp 10 12Fabio da CostaNo ratings yet
- Retrospective Chart Review GuidelinesDocument7 pagesRetrospective Chart Review GuidelinesconfusedmageNo ratings yet
- Classification and Regression Tree Analy PDFDocument10 pagesClassification and Regression Tree Analy PDFEduard MacoveiNo ratings yet
- Real World Data Applications and Relevance To CA 2023 Seminars in RadiationDocument12 pagesReal World Data Applications and Relevance To CA 2023 Seminars in RadiationFlavio GuimaraesNo ratings yet
- An Introduction To Classification and Regression TreeDocument15 pagesAn Introduction To Classification and Regression Treeo65346No ratings yet
- Alarid-Escudero Et Al. - 2020 - Cohort State-Transition Models in R A TutorialDocument48 pagesAlarid-Escudero Et Al. - 2020 - Cohort State-Transition Models in R A TutorialferalaesNo ratings yet
- Microsimulation Modeling For Health Decision Sciences Using R: A TutorialDocument23 pagesMicrosimulation Modeling For Health Decision Sciences Using R: A TutorialferalaesNo ratings yet
- Biostatistics Explored Through R Software: An OverviewFrom EverandBiostatistics Explored Through R Software: An OverviewRating: 3.5 out of 5 stars3.5/5 (2)
- Statnews #78 What Is Survival Analysis?Document3 pagesStatnews #78 What Is Survival Analysis?rahulsukhijaNo ratings yet
- Model Parameter Estimation and Uncertainy AnalysisDocument11 pagesModel Parameter Estimation and Uncertainy AnalysisFiromsa IbrahimNo ratings yet
- Difference Between Literature Review Systematic ReviewDocument8 pagesDifference Between Literature Review Systematic ReviewafdtzvbexNo ratings yet
- Fall PreventionDocument18 pagesFall PreventionJay DNo ratings yet
- Readmission Systematic ReviewDocument11 pagesReadmission Systematic ReviewchairunnisyaNo ratings yet
- Decision Analysis in PH AK PDFDocument67 pagesDecision Analysis in PH AK PDFJuwel RanaNo ratings yet
- Discrete Event Simulation The Preferred Technique for HealthDocument5 pagesDiscrete Event Simulation The Preferred Technique for Health6551209251No ratings yet
- Literature Review of Adverse EventsDocument5 pagesLiterature Review of Adverse Eventsafmabzmoniomdc100% (1)
- 10.1007@s00296 020 04740 ZDocument13 pages10.1007@s00296 020 04740 ZLuis LuengoNo ratings yet
- Pate2019 Uncertainty Risk Prediction Models Individual Decision MakingDocument16 pagesPate2019 Uncertainty Risk Prediction Models Individual Decision MakingbrecheisenNo ratings yet
- Sensitivity Analysis Chapter 11Document16 pagesSensitivity Analysis Chapter 11landabureNo ratings yet
- Literature Review Systematic Review DifferenceDocument8 pagesLiterature Review Systematic Review Differenceaflskfbue100% (1)
- Multivariate or Multivariable RegressionDocument2 pagesMultivariate or Multivariable Regressionaoi himeNo ratings yet
- An Introductory Tutorial On Cohort State-Transition Models in R Using A Cost-Effectiveness Analysis ExampleDocument31 pagesAn Introductory Tutorial On Cohort State-Transition Models in R Using A Cost-Effectiveness Analysis ExampleferalaesNo ratings yet
- NHMRC Literature ReviewDocument4 pagesNHMRC Literature Reviewafdttqbna100% (1)
- Sample Size - How Many PartcipantsDocument7 pagesSample Size - How Many PartcipantsAKNTAI002No ratings yet
- Bio StatisticsDocument20 pagesBio StatisticskatyNo ratings yet
- Estadística 3Document8 pagesEstadística 3Ezequiel ZacañinoNo ratings yet
- Perspective: Comparative Effectiveness: Asking The Right Questions, Choosing The Right MethodDocument5 pagesPerspective: Comparative Effectiveness: Asking The Right Questions, Choosing The Right MethodamkroegeNo ratings yet
- An Introduction To Classification and Regression Tree (CART) AnalysisDocument15 pagesAn Introduction To Classification and Regression Tree (CART) AnalysisNyimas SharimaNo ratings yet
- Inter Per Ting Clinical TrialsDocument10 pagesInter Per Ting Clinical TrialsJulianaCerqueiraCésarNo ratings yet
- Primary Health Care Literature ReviewDocument4 pagesPrimary Health Care Literature Reviewafdtbluwq100% (1)
- Sample Size Determination in Health StudiesDocument88 pagesSample Size Determination in Health Studiesedwinclifford100% (1)
- Most Frequently Used Terms in Biostatistics: Your LogoDocument44 pagesMost Frequently Used Terms in Biostatistics: Your LogocainbelzebubNo ratings yet
- Cross-Sectional Studies - What Are They Good ForDocument6 pagesCross-Sectional Studies - What Are They Good Formirabel IvanaliNo ratings yet
- Patient Centred Variables With Univariateassociations With Unplanned ICU Admissiona Systematic ReviewDocument9 pagesPatient Centred Variables With Univariateassociations With Unplanned ICU Admissiona Systematic ReviewsarintiNo ratings yet
- Laboratory Activity 01Document10 pagesLaboratory Activity 01Christine Mae CionNo ratings yet
- Literature Review On Alternative MedicineDocument8 pagesLiterature Review On Alternative Medicinefrqofvbnd100% (1)
- Evaluating Clinical Rating Scales For Evidence Based Derm - 2005 - DermatologicDocument4 pagesEvaluating Clinical Rating Scales For Evidence Based Derm - 2005 - DermatologicMilena MonteiroNo ratings yet
- Systematic Review and Meta-Analysis of The Literature Regarding The Diagnosis of Sleep ApneaDocument4 pagesSystematic Review and Meta-Analysis of The Literature Regarding The Diagnosis of Sleep Apneafuhukuheseg2No ratings yet
- Big Data in Healthcare: Statistical Analysis of the Electronic Health RecordFrom EverandBig Data in Healthcare: Statistical Analysis of the Electronic Health RecordNo ratings yet
- Simulation ArticleDocument11 pagesSimulation ArticleGameNo ratings yet
- U03a1 Analytics Internship Executive Summary 1 Group Hal HagoodDocument9 pagesU03a1 Analytics Internship Executive Summary 1 Group Hal HagoodHalHagoodNo ratings yet
- Risk Assessment Research PaperDocument8 pagesRisk Assessment Research Paperh02ngq6c100% (1)
- Using Latent Class Analysis To Model Prescription Medications in The Measurement of Falling Among A Community Elderly PopulationDocument7 pagesUsing Latent Class Analysis To Model Prescription Medications in The Measurement of Falling Among A Community Elderly PopulationIcaroNo ratings yet
- 1471-2288-10-66Document12 pages1471-2288-10-66Azzahra ZaydNo ratings yet
- Systematic Literature Review EpidemiologyDocument6 pagesSystematic Literature Review Epidemiologyc5qx9hq5100% (1)
- Comprehensive Literature Review and Statistical Considerations For Microarray Meta-AnalysisDocument6 pagesComprehensive Literature Review and Statistical Considerations For Microarray Meta-Analysisea442225No ratings yet
- Descriptive Epidemiology Research PaperDocument7 pagesDescriptive Epidemiology Research Paperfvg2005k100% (1)
- Meta-Analysis of Screening and Diagnostic TestsDocument12 pagesMeta-Analysis of Screening and Diagnostic TestsLaurens KramerNo ratings yet
- Dissertation Randomised Controlled TrialDocument4 pagesDissertation Randomised Controlled TrialBuyAPaperOnlineUK100% (1)
- Research 1 FinalsDocument81 pagesResearch 1 FinalsKaiken DukeNo ratings yet
- How To Do A Meta-Analysis Literature ReviewDocument6 pagesHow To Do A Meta-Analysis Literature Reviewaflsbbesq100% (1)
- Literature Review Developing Competencies For Health Promotion Deliverable 3bDocument10 pagesLiterature Review Developing Competencies For Health Promotion Deliverable 3bxfeivdsifNo ratings yet
- Gas Turbines A Manual PDFDocument74 pagesGas Turbines A Manual PDFHenry Pannell100% (1)
- Mil HDBK 1390 PDFDocument31 pagesMil HDBK 1390 PDFsleepanon4362No ratings yet
- NAVSEA RCM Handbook DTD 18 April 2007Document105 pagesNAVSEA RCM Handbook DTD 18 April 2007glanchezNo ratings yet
- Healthy Heart Solution Kit - Cookbook - v01Document23 pagesHealthy Heart Solution Kit - Cookbook - v01sleepanon4362100% (2)
- 5 Heart Healthy Grocery ItemsDocument3 pages5 Heart Healthy Grocery Itemssleepanon4362100% (2)
- Model Cooling Tower Maintenance Program PDFDocument41 pagesModel Cooling Tower Maintenance Program PDFMyo SeinNo ratings yet
- Western Turbine Users, Inc. (WTUI) Orap For LM6000 Users 2020 ConferenceDocument19 pagesWestern Turbine Users, Inc. (WTUI) Orap For LM6000 Users 2020 Conferencesleepanon4362No ratings yet
- 4 - Canaanite Child Sacrifice - Smith 90 125 PDFDocument36 pages4 - Canaanite Child Sacrifice - Smith 90 125 PDFsleepanon4362No ratings yet
- Detection of Valve Leakage in Reciprocat PDFDocument9 pagesDetection of Valve Leakage in Reciprocat PDFsleepanon4362No ratings yet
- Application of Axiomatic Design Concept To Toaster Design - A Case StudyDocument24 pagesApplication of Axiomatic Design Concept To Toaster Design - A Case StudyJorgeCanoRamirezNo ratings yet
- RAND - MG205 - Improving The Army's Management of Reparable Spare PartsDocument111 pagesRAND - MG205 - Improving The Army's Management of Reparable Spare Partssleepanon4362No ratings yet
- A Data-Driven Model For Software Reliability PredictionDocument32 pagesA Data-Driven Model For Software Reliability Predictionsleepanon4362No ratings yet
- Corrective Action and Preventive Action Plan: Name of Establishment: Address: Inspector/s: Inspection DatesDocument3 pagesCorrective Action and Preventive Action Plan: Name of Establishment: Address: Inspector/s: Inspection Datessleepanon4362No ratings yet
- Designing Logistics Support SystemsDocument181 pagesDesigning Logistics Support Systemssleepanon4362No ratings yet
- Reliability Simulation of Component-Based Software Systems (1998)Document21 pagesReliability Simulation of Component-Based Software Systems (1998)sleepanon4362No ratings yet
- RAM Guide 080305Document266 pagesRAM Guide 080305Ned H. CriscimagnaNo ratings yet
- Detection of Valve Leakage in Reciprocat PDFDocument9 pagesDetection of Valve Leakage in Reciprocat PDFsleepanon4362No ratings yet
- Entropy 19 00291Document10 pagesEntropy 19 00291sleepanon4362No ratings yet
- From HALT Results To An Accurate Field MTBF - PresentationDocument27 pagesFrom HALT Results To An Accurate Field MTBF - Presentationsleepanon4362No ratings yet
- Are Inventions InevitableDocument17 pagesAre Inventions Inevitablesleepanon4362No ratings yet
- MTBF M2Document47 pagesMTBF M2sleepanon4362No ratings yet
- SPM 169 Suo Halt and HassDocument154 pagesSPM 169 Suo Halt and Hasssleepanon4362No ratings yet
- SPM 169 Suo Halt and HassDocument154 pagesSPM 169 Suo Halt and Hasssleepanon4362No ratings yet
- Traffic AnalysiTraffic Analysis With Wiresharks With WiresharkDocument51 pagesTraffic AnalysiTraffic Analysis With Wiresharks With WiresharkJuztYooNo ratings yet
- Quality and Reliability MethodsDocument340 pagesQuality and Reliability Methodssleepanon4362No ratings yet
- 1201 4604Document26 pages1201 4604sleepanon4362No ratings yet
- SPM 169 Suo Halt and HassDocument154 pagesSPM 169 Suo Halt and Hasssleepanon4362No ratings yet
- Bayes' Estimators of Generalized EntropiesDocument16 pagesBayes' Estimators of Generalized Entropiessleepanon4362No ratings yet
- Quality and Reliability Process Characterisation, Evaluation and Improvement in Product DesignDocument7 pagesQuality and Reliability Process Characterisation, Evaluation and Improvement in Product Designsleepanon4362No ratings yet
- Math Patterns Power PointDocument19 pagesMath Patterns Power Pointsleepanon436250% (2)
- MKO Mental Wellness Initiative Request For Proposals RFP FINALDocument3 pagesMKO Mental Wellness Initiative Request For Proposals RFP FINALManitoba Keewatinowi OkimakanakNo ratings yet
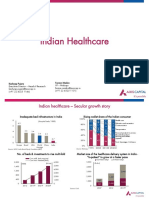
- Indian healthcare - A secular growth storyDocument20 pagesIndian healthcare - A secular growth storyDoshi VaibhavNo ratings yet
- Infectious Diseases For InternsDocument60 pagesInfectious Diseases For InternsMaya SwariNo ratings yet
- PHG111 AssignmentDocument7 pagesPHG111 AssignmentKermina Elkomos Wissa Azmy FanousNo ratings yet
- Psychometric Evaluation of The Energy Conservation Strategies SurveyDocument7 pagesPsychometric Evaluation of The Energy Conservation Strategies SurveyJennifer HoggNo ratings yet
- UnderstaffingDocument13 pagesUnderstaffingIrish Docoy PatesNo ratings yet
- Dializer Hollow FiberDocument6 pagesDializer Hollow FiberdinamariaNo ratings yet
- Histrionic Personality DisorderDocument2 pagesHistrionic Personality DisorderMarietta JuaniteNo ratings yet
- Bipolar Disorder Mixed Episode Case StudyDocument14 pagesBipolar Disorder Mixed Episode Case Studyapi-658874568No ratings yet
- Fundamentals Exam 3Document2 pagesFundamentals Exam 3JackieNo ratings yet
- Insect Arthropod RepellantDocument3 pagesInsect Arthropod RepellantBatanNo ratings yet
- Facts About Ventricular Septal DefectDocument4 pagesFacts About Ventricular Septal DefectAlfiaaNo ratings yet
- The Neonatal Intensive Care Unit-2Document28 pagesThe Neonatal Intensive Care Unit-2api-457873289No ratings yet
- Sex, Sleep or Scrabble? by DR Phil Hammond ExtractDocument36 pagesSex, Sleep or Scrabble? by DR Phil Hammond ExtractBlack & White PublishingNo ratings yet
- Practical Raptor Nutrition Neil Forbes PDFDocument9 pagesPractical Raptor Nutrition Neil Forbes PDFWisnu JuliastitoNo ratings yet
- Ajahzi Gardner - SlimThicc Training GuideDocument155 pagesAjahzi Gardner - SlimThicc Training GuideMary-Joe Semaani100% (1)
- MYP Unit Planner Sample: Powering Your CurriculumDocument14 pagesMYP Unit Planner Sample: Powering Your CurriculumNigarNo ratings yet
- Physical Education 10 Las No.1 Week1 2 Fourth QuarterDocument2 pagesPhysical Education 10 Las No.1 Week1 2 Fourth QuarterTheresa Vasquez Vicente100% (1)
- #44 Ravanera, Adiel A. CED 11-201A MissionDocument4 pages#44 Ravanera, Adiel A. CED 11-201A MissionAdielNo ratings yet
- Cravings and Fad Diet WorkshopDocument19 pagesCravings and Fad Diet Workshopapi-487922974No ratings yet
- Obstetric Referrals at Saint Paul'S Hospital Millennium Medical College (SPHMMC) : Pre-Referral Care and AppropriatenessDocument7 pagesObstetric Referrals at Saint Paul'S Hospital Millennium Medical College (SPHMMC) : Pre-Referral Care and AppropriatenessTaklu Marama M. BaatiiNo ratings yet
- Bagic Apollo MunichDocument3 pagesBagic Apollo Munichrajkamal rNo ratings yet
- WHO Assessment RiskDocument90 pagesWHO Assessment RiskJuliana VelosoNo ratings yet
- Lisie College of Nursing Master PlanDocument1 pageLisie College of Nursing Master PlanDinesh JoyNo ratings yet
- Forward IMRT Breast PDFDocument54 pagesForward IMRT Breast PDFmitza05100% (1)
- Gender & Mental HealthDocument25 pagesGender & Mental HealthMarcNo ratings yet
- Cancer: Causes, Diagnosis & TreatmentDocument2 pagesCancer: Causes, Diagnosis & TreatmentNitesh kuraheNo ratings yet
- ERP Bridging Document Rev 00Document21 pagesERP Bridging Document Rev 00herisusantoNo ratings yet
- Pmjay - Cmchis FaqDocument3 pagesPmjay - Cmchis FaqPrabandio ButhiranNo ratings yet
- Human Behavior and The Social Environment I 1590508065Document1,310 pagesHuman Behavior and The Social Environment I 1590508065prim100% (1)