You might also like
- Applying The 2010 ASCE 7 Wind and Ice Requirements To Transmission Line DesignDocument12 pagesApplying The 2010 ASCE 7 Wind and Ice Requirements To Transmission Line Designwalter huNo ratings yet
- Towards The Use of Pretrained Language Models For Task-Oriented Dialogue SystemsDocument8 pagesTowards The Use of Pretrained Language Models For Task-Oriented Dialogue SystemsyadavrajeNo ratings yet
- The PileDocument39 pagesThe PileRicardo PietrobonNo ratings yet
- Discourse-Aware Soft Prompting For Text GenerationDocument20 pagesDiscourse-Aware Soft Prompting For Text GenerationcloudsmgNo ratings yet
- Rare WordsDocument9 pagesRare WordsAgata AlleruzzoNo ratings yet
- 2021 Mirror-Bert EmnlpDocument18 pages2021 Mirror-Bert Emnlprajesh716No ratings yet
- Go-Tuning: Improving Zero-Shot Learning Abilities of Smaller Language ModelsDocument9 pagesGo-Tuning: Improving Zero-Shot Learning Abilities of Smaller Language ModelsYm MNo ratings yet
- DOBF - A Deobfuscation Pre-Training Objective For Programming LanguagesDocument15 pagesDOBF - A Deobfuscation Pre-Training Objective For Programming LanguagesZedni ReNo ratings yet
- Survey On LLMDocument9 pagesSurvey On LLMRanger LosNo ratings yet
- Hello, It's GPT-2 - How Can I Help You?Document8 pagesHello, It's GPT-2 - How Can I Help You?Igor Velmud BanderoNo ratings yet
- ConSultantBERT Fine-Tuned Siamese Sentence-BERT ForDocument8 pagesConSultantBERT Fine-Tuned Siamese Sentence-BERT Forwanzhi xiaoNo ratings yet
- Controllable Fake Document Infilling For Cyber DeceptionDocument15 pagesControllable Fake Document Infilling For Cyber DeceptiongabiknightsanonymousNo ratings yet
- Voita - When A Good Translation Is Wrong in ContextDocument15 pagesVoita - When A Good Translation Is Wrong in ContextPedor RomerNo ratings yet
- 2021 Naacl-Main 185Document14 pages2021 Naacl-Main 185trimble2No ratings yet
- 5 2022 Bea-1 28Document16 pages5 2022 Bea-1 28Juan David Romero SuarezNo ratings yet
- GPT3 Similar Performance2009.07118Document11 pagesGPT3 Similar Performance2009.07118rNo ratings yet
- Bertweet: A Pre-Trained Language Model For English TweetsDocument6 pagesBertweet: A Pre-Trained Language Model For English TweetsNy Aina RazafindratsimaNo ratings yet
- Paper 2Document19 pagesPaper 2Pritesh SuroliaNo ratings yet
- Multi-Step Jailbreaking Privacy Attacks On ChatGPTDocument16 pagesMulti-Step Jailbreaking Privacy Attacks On ChatGPTmarcellinocovaraNo ratings yet
- Retgen: A Joint Framework For Retrieval and Grounded Text Generation ModelingDocument15 pagesRetgen: A Joint Framework For Retrieval and Grounded Text Generation Modelingahmad raihanNo ratings yet
- 2 - 23 - A Survey of Vision-Language Pre-Training From The Lens of Multimodal Machine TranslationDocument10 pages2 - 23 - A Survey of Vision-Language Pre-Training From The Lens of Multimodal Machine TranslationPhạm Thanh TrườngNo ratings yet
- 2021 emnlp-main 92论文Document14 pages2021 emnlp-main 92论文aslina akwaNo ratings yet
- Do Massively Pretrained Language Models Make Better Storytellers?Document19 pagesDo Massively Pretrained Language Models Make Better Storytellers?Alwindo SiskiNo ratings yet
- Jia Et Al. - 2021 - Scaling Up Visual and Vision-Language RepresentatiDocument11 pagesJia Et Al. - 2021 - Scaling Up Visual and Vision-Language RepresentatiIghor VGNo ratings yet
- Socratic Models ML AI LM 2204.00598Document20 pagesSocratic Models ML AI LM 2204.00598michetraviNo ratings yet
- Tacl A 00544Document23 pagesTacl A 00544Brent BaumgartnerNo ratings yet
- Cross-Modal Language Generation Using Pivot Stabilization For Web-Scale Language CoverageDocument11 pagesCross-Modal Language Generation Using Pivot Stabilization For Web-Scale Language CoverageHarishNandanNo ratings yet
- Building A Role Specified Open-Domain Dialogue System Leveraging Large-Scale Language ModelsDocument23 pagesBuilding A Role Specified Open-Domain Dialogue System Leveraging Large-Scale Language Modelsjackk venomNo ratings yet
- Evaluate LLMDocument27 pagesEvaluate LLMarunkumarl87No ratings yet
- How To Unleash The Power of Large Language Models For Few-Shot Relation ExtractionDocument11 pagesHow To Unleash The Power of Large Language Models For Few-Shot Relation Extractionxzj294197164No ratings yet
- Retro Model Deep-MindDocument43 pagesRetro Model Deep-Minddjame seddahNo ratings yet
- Sasha Rush - Interactive and Visual Prompt EngineeringDocument11 pagesSasha Rush - Interactive and Visual Prompt EngineeringGugo ManNo ratings yet
- Whisper OpenaiDocument28 pagesWhisper OpenaiChris HeNo ratings yet
- Whisper PDFDocument28 pagesWhisper PDFzakariNo ratings yet
- 2023 Acl-Long 66Document16 pages2023 Acl-Long 66会爆炸的小米NoteNo ratings yet
- How To Fine-Tune BERT For Text Classification?: Corresponding Author The Source Codes Are Available atDocument10 pagesHow To Fine-Tune BERT For Text Classification?: Corresponding Author The Source Codes Are Available atSYNERGY USMSNo ratings yet
- Multi-Task Deep Neural Networks For Natural Language UnderstandingDocument10 pagesMulti-Task Deep Neural Networks For Natural Language UnderstandingSana KhanNo ratings yet
- Universal Sentence EncoderDocument7 pagesUniversal Sentence Encoderviterbi kkkNo ratings yet
- Multimodal Chain of Thought Reasoning in Language ModelsDocument19 pagesMultimodal Chain of Thought Reasoning in Language ModelsBlerim HasaNo ratings yet
- Formal Mathematics Statement Curriculum LearningDocument26 pagesFormal Mathematics Statement Curriculum LearningKevin YoungNo ratings yet
- Instruction Position Matters in Sequence Generation With Large Language ModelsDocument11 pagesInstruction Position Matters in Sequence Generation With Large Language ModelsIsmail NajimNo ratings yet
- MSP: Multi-Stage Prompting For Making Pre-Trained Language Models Better TranslatorsDocument9 pagesMSP: Multi-Stage Prompting For Making Pre-Trained Language Models Better Translatorsmehar bhatiaNo ratings yet
- Tips Reference 1Document42 pagesTips Reference 1Vadlamudi DhyanamalikaNo ratings yet
- MTEB: Massive Text Embedding BenchmarkDocument24 pagesMTEB: Massive Text Embedding BenchmarkChrisHaldenNo ratings yet
- BASE TTS: Lessons From Building A Billion-Parameter Text-to-Speech Model On 100K Hours of Data (2402.08093)Document27 pagesBASE TTS: Lessons From Building A Billion-Parameter Text-to-Speech Model On 100K Hours of Data (2402.08093)JohnNo ratings yet
- 3 Paradigm 2: Prompt-Based Learning: Table 2: Example Prompt Designs For Learning From In-StructionsDocument10 pages3 Paradigm 2: Prompt-Based Learning: Table 2: Example Prompt Designs For Learning From In-StructionsMortimer MeunierNo ratings yet
- LLaMA Open and Efficient Foundation Language ModelsDocument27 pagesLLaMA Open and Efficient Foundation Language Modelscortox1006No ratings yet
- Adapting Language Models For Zero-Shot Learning by Meta-Tuning On Dataset and Prompt CollectionsDocument26 pagesAdapting Language Models For Zero-Shot Learning by Meta-Tuning On Dataset and Prompt Collectionswalter huNo ratings yet
- Do We Need To Create Big Datasets To Learn A Task?Document5 pagesDo We Need To Create Big Datasets To Learn A Task?刘中坤No ratings yet
- No Training Required Exploring Random Encoders For Sentence ClassificationDocument16 pagesNo Training Required Exploring Random Encoders For Sentence ClassificationMoonlight DancerNo ratings yet
- Baselines and AnalysisDocument6 pagesBaselines and Analysisbelay beyenaNo ratings yet
- Generating Personalized Dialogues Using GPT-3Document20 pagesGenerating Personalized Dialogues Using GPT-3Max ZhouNo ratings yet
- Pre-Training Is A Hot Topic: Contextualized Document Embeddings Improve Topic CoherenceDocument8 pagesPre-Training Is A Hot Topic: Contextualized Document Embeddings Improve Topic CoherenceamriteshworkNo ratings yet
- AlbNews: A Corpus of Headlines For Topic Modeling in AlbanianDocument5 pagesAlbNews: A Corpus of Headlines For Topic Modeling in AlbanianForNo ratings yet
- Codebert PaperDocument12 pagesCodebert PapernaklidNo ratings yet
- DIET: Lightweight Language Understanding For Dialogue SystemsDocument9 pagesDIET: Lightweight Language Understanding For Dialogue Systemsahmad raihanNo ratings yet
- Scaling Down To Scale Up: A Guide To Parameter-Efficient Fine-TuningDocument21 pagesScaling Down To Scale Up: A Guide To Parameter-Efficient Fine-TuningChrisHaldenNo ratings yet
- 29 - Multi-Task Deep Neural Networks For Natural Language UnderstandingDocument10 pages29 - Multi-Task Deep Neural Networks For Natural Language UnderstandingOffice WorkNo ratings yet
- VIMA - General Robot Manipulation With Multimodal PromptsDocument48 pagesVIMA - General Robot Manipulation With Multimodal Promptselisio.silvaNo ratings yet
- Learning Transferable Visual Models From Natural Language SupervisionDocument47 pagesLearning Transferable Visual Models From Natural Language Supervisionbob cellNo ratings yet
- Analytical Study of Certain Magnetohydrodynamic-α Models: Jasmine S. Linshiz and Edriss S. TitiDocument26 pagesAnalytical Study of Certain Magnetohydrodynamic-α Models: Jasmine S. Linshiz and Edriss S. Titiwalter huNo ratings yet
- CGC Basics Tips 0 12Document2 pagesCGC Basics Tips 0 12walter huNo ratings yet
- 1703.06259Document28 pages1703.06259walter huNo ratings yet
- My Trip: Ethiopian Airlines (ET) 607Document1 pageMy Trip: Ethiopian Airlines (ET) 607walter huNo ratings yet
- The Kastler-Kalau-Walze Type Theorem For 6-Dimensional Manifolds With BoundaryDocument15 pagesThe Kastler-Kalau-Walze Type Theorem For 6-Dimensional Manifolds With Boundarywalter huNo ratings yet
- Challenges Changes ChoicesDocument32 pagesChallenges Changes Choiceswalter huNo ratings yet
- 1609 00027Document85 pages1609 00027walter huNo ratings yet
- Cohomology and Versal Deformations of Hom-Leibniz AlgebrasDocument22 pagesCohomology and Versal Deformations of Hom-Leibniz Algebraswalter huNo ratings yet
- Parent Booklet - enDocument29 pagesParent Booklet - enwalter huNo ratings yet
- A Semiclassical Heat Kernel Proof of The Poincaré-Hopf TheoremDocument29 pagesA Semiclassical Heat Kernel Proof of The Poincaré-Hopf Theoremwalter huNo ratings yet
- T. Tao Derived Similar Results IndependentlyDocument37 pagesT. Tao Derived Similar Results Independentlywalter huNo ratings yet
- 1 (Log Q) 1.9828mDocument16 pages1 (Log Q) 1.9828mwalter huNo ratings yet
- Large-Small Equivalence in String TheoryDocument12 pagesLarge-Small Equivalence in String Theorywalter huNo ratings yet
- 2006 08250Document79 pages2006 08250walter huNo ratings yet
- Intersection Theory, Integrable Hierarchies and Topological Field TheoryDocument73 pagesIntersection Theory, Integrable Hierarchies and Topological Field Theorywalter huNo ratings yet
- Sharp Complexity Phase Transitions Generated by EntanglementDocument21 pagesSharp Complexity Phase Transitions Generated by Entanglementwalter huNo ratings yet
- Backward Feature Correction: How Deep Learning Performs Deep (Hierarchical) LearningDocument93 pagesBackward Feature Correction: How Deep Learning Performs Deep (Hierarchical) Learningwalter huNo ratings yet
- QRT19 QRT20Document27 pagesQRT19 QRT20walter huNo ratings yet
- Localization For Wilson Loops in Chern-Simons TheoryDocument228 pagesLocalization For Wilson Loops in Chern-Simons Theorywalter huNo ratings yet
- Tri69 Tri69 KM61 Fre82 LW90 LW97 HK93Document47 pagesTri69 Tri69 KM61 Fre82 LW90 LW97 HK93walter huNo ratings yet
- 2109 02851Document34 pages2109 02851walter huNo ratings yet
- 2201 02380Document19 pages2201 02380walter huNo ratings yet
- 2201 01263Document26 pages2201 01263walter huNo ratings yet
- The Binary Goldbach ProblemDocument18 pagesThe Binary Goldbach Problemwalter huNo ratings yet
- 2201 01328Document23 pages2201 01328walter huNo ratings yet
- An Evaluation of Local Shape-Based Features For Pedestrian DetectionDocument10 pagesAn Evaluation of Local Shape-Based Features For Pedestrian Detectionwalter huNo ratings yet
- ApproximationDocument12 pagesApproximationwalter huNo ratings yet
- A Variational Method For The Recovery of Dense 3D Structure From MotionDocument11 pagesA Variational Method For The Recovery of Dense 3D Structure From Motionwalter huNo ratings yet
- The Three Millennium Problem Solutions (RH, NSE, YME) and A Hilbert Scale Based GeometrodynamicsDocument22 pagesThe Three Millennium Problem Solutions (RH, NSE, YME) and A Hilbert Scale Based Geometrodynamicswalter huNo ratings yet
- ENN103F: Tutorial Letter 101/3/2018Document21 pagesENN103F: Tutorial Letter 101/3/2018Matlhodi Pholoso MashapaNo ratings yet
- Factors Affecting Students' Adoption of ICT Tools in Higher Education InstitutionsDocument13 pagesFactors Affecting Students' Adoption of ICT Tools in Higher Education InstitutionsMadhavaiahChendragiriNo ratings yet
- Service Level Agreement (Including Process Map)Document3 pagesService Level Agreement (Including Process Map)Keti ImnadzeNo ratings yet
- HR ModuleDocument4 pagesHR Modulemani vannanNo ratings yet
- Dhruvkumar Rameshkumar Joshi: ObjectiveDocument2 pagesDhruvkumar Rameshkumar Joshi: ObjectiveNishit TNo ratings yet
- Strong Thesis Statements For 1984Document5 pagesStrong Thesis Statements For 1984afcnugzpd100% (2)
- Result Based MonitoringDocument11 pagesResult Based MonitoringdmugalloyNo ratings yet
- "The Address" Documentary QuestionsDocument4 pages"The Address" Documentary Questionsapi-254583609No ratings yet
- Cycle 2-Annotated Bibliography 1Document4 pagesCycle 2-Annotated Bibliography 1api-343815626100% (1)
- Prep 121 P1-3 Classroom Study Writing Booklet - StudentDocument39 pagesPrep 121 P1-3 Classroom Study Writing Booklet - StudentkdkskfkskfskfjNo ratings yet
- Nurse Licensure Examination Review QuestionsDocument2 pagesNurse Licensure Examination Review Questionssixterz750% (2)
- Shravan Kumar DasariDocument3 pagesShravan Kumar DasariDasari Shràván KümârNo ratings yet
- Department of Education: Learning Activity SheetDocument2 pagesDepartment of Education: Learning Activity SheetCecile Lhet Fernandez CatindigNo ratings yet
- Final Teachworthy LPG Assignment 2Document3 pagesFinal Teachworthy LPG Assignment 2api-628110603100% (2)
- The 3 R's (Reading, 'Riting, and 'Rithmetic)Document3 pagesThe 3 R's (Reading, 'Riting, and 'Rithmetic)El Comedor Benedict100% (1)
- A.D. Henderson University School/FAU High School 2021-2022 School CalendarDocument2 pagesA.D. Henderson University School/FAU High School 2021-2022 School CalendarCampo VecchioNo ratings yet
- Pratyush Shukla JavaDocument9 pagesPratyush Shukla JavaSanjaNo ratings yet
- DR AgarwalDocument3 pagesDR AgarwalYv SantoshNo ratings yet
- Lumanog, Ronalyn L. (Detailed Lesson Plan in English 3)Document8 pagesLumanog, Ronalyn L. (Detailed Lesson Plan in English 3)Ronalyn LumanogNo ratings yet
- It Case Study FBIDocument9 pagesIt Case Study FBIsuriakumaranNo ratings yet
- BU-F-GS-4 Request For Dropping and Adding SubjectsDocument1 pageBU-F-GS-4 Request For Dropping and Adding Subjectsdaren.tejadaNo ratings yet
- Final Project Basket BallDocument40 pagesFinal Project Basket BallUlrike Regina0% (1)
- (Practical: Teaching The Pressure-Flow Hypothesis of Phloem Transport in A Problem-Solving SessionDocument6 pages(Practical: Teaching The Pressure-Flow Hypothesis of Phloem Transport in A Problem-Solving Sessionkikkabuttigieg1466No ratings yet
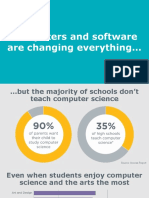
- Computer Science AdvocacyDocument26 pagesComputer Science AdvocacyhjkNo ratings yet
- Scheme of Work IIDocument17 pagesScheme of Work IIFaiz FahmiNo ratings yet
- Prevention of Childhood Obesity 1Document9 pagesPrevention of Childhood Obesity 1MrSomnambululNo ratings yet
- Microproject of I Year (21-22) PHY & ICTDocument7 pagesMicroproject of I Year (21-22) PHY & ICTSharvil DharmikNo ratings yet
- Xamarin Cross-Platform Development Cookbook - Sample ChapterDocument43 pagesXamarin Cross-Platform Development Cookbook - Sample ChapterPackt Publishing100% (1)
- Alignment of The Language and Literacy Domains: Group 1Document37 pagesAlignment of The Language and Literacy Domains: Group 1Daniel TomnobNo ratings yet
- Collaborative Project Management - WikipediaDocument7 pagesCollaborative Project Management - Wikipediasindhuja eswarNo ratings yet