You might also like
- Redurex TCDocument38 pagesRedurex TCBogdan Dumitrache100% (2)
- Comparing The Areas Under Two or More Correlated Receiver Operating Characteristic Curves A Nonparametric ApproachDocument10 pagesComparing The Areas Under Two or More Correlated Receiver Operating Characteristic Curves A Nonparametric Approachajax_telamonioNo ratings yet
- CoolingDocument26 pagesCoolingShahrukh AnsariNo ratings yet
- Becker Ichino Pscore SJ 2002Document20 pagesBecker Ichino Pscore SJ 2002Juan ToapantaNo ratings yet
- Ordinal Logistic Regression: 13.1 BackgroundDocument15 pagesOrdinal Logistic Regression: 13.1 BackgroundShan BasnayakeNo ratings yet
- Bias-Corrected Matching Estimators ForDocument11 pagesBias-Corrected Matching Estimators ForMbengue ibNo ratings yet
- Sample Size and Optimal Design For Logistic Regression With Binary Interaction - Eugene DemidenkoDocument11 pagesSample Size and Optimal Design For Logistic Regression With Binary Interaction - Eugene DemidenkodbmestNo ratings yet
- General Method of MomentsDocument14 pagesGeneral Method of MomentsSantosh Mon AbrahamNo ratings yet
- The Efficient Use of Supplementary Information in Finite Population SamplingDocument73 pagesThe Efficient Use of Supplementary Information in Finite Population SamplingFlorentin SmarandacheNo ratings yet
- Ebalance A Stata Package For Entropy BalancingDocument18 pagesEbalance A Stata Package For Entropy BalancingGerardo DamianNo ratings yet
- Yazganetal Rev SonDocument11 pagesYazganetal Rev Sonapi-569985613No ratings yet
- Utad 016Document36 pagesUtad 016cao xiuzhenNo ratings yet
- Applications of Generalized Method of Moments Estimation: Jeffrey M. WooldridgeDocument14 pagesApplications of Generalized Method of Moments Estimation: Jeffrey M. WooldridgeLuca SomigliNo ratings yet
- Jep 15 4 87Document26 pagesJep 15 4 87Frann AraNo ratings yet
- Imbens Wooldridge NotesDocument473 pagesImbens Wooldridge NotesAlvaro Andrés PerdomoNo ratings yet
- Multiple Imputation of Predictor Variables Using Generalized Additive ModelsDocument27 pagesMultiple Imputation of Predictor Variables Using Generalized Additive ModelseduardoNo ratings yet
- Slides 1 Match7!30!07Document40 pagesSlides 1 Match7!30!07keyyongparkNo ratings yet
- Ols, M, S and Adaptive Estimation in Linear RegressionDocument7 pagesOls, M, S and Adaptive Estimation in Linear RegressionIAEME PublicationNo ratings yet
- Testing Significance of Mixing and Demixing Coefficients in IcaDocument8 pagesTesting Significance of Mixing and Demixing Coefficients in IcaManolo ParedesNo ratings yet
- Lecture # 2 (The Classical Linear Regression Model) PDFDocument3 pagesLecture # 2 (The Classical Linear Regression Model) PDFBatool SahabnNo ratings yet
- Probabilistic Considerations of The Consistency Index in Reciprocal MatricesDocument13 pagesProbabilistic Considerations of The Consistency Index in Reciprocal MatricesVali_TronaruNo ratings yet
- Instrumental Variable: Statistics Econometrics EpidemiologyDocument5 pagesInstrumental Variable: Statistics Econometrics EpidemiologyJude Agnello AlexNo ratings yet
- Handout 05 Regression and Correlation PDFDocument17 pagesHandout 05 Regression and Correlation PDFmuhammad aliNo ratings yet
- Estimation of Multivariate Probit Models: A Mixed Generalized Estimating/pseudo-Score Equations Approach and Some Nite Sample ResultsDocument19 pagesEstimation of Multivariate Probit Models: A Mixed Generalized Estimating/pseudo-Score Equations Approach and Some Nite Sample Resultsjmurray1022No ratings yet
- Sciencedirect: Categorical Principal Component Logistic Regression: A Case Study For Housing Loan ApprovalDocument7 pagesSciencedirect: Categorical Principal Component Logistic Regression: A Case Study For Housing Loan ApprovalAncyMariyaNo ratings yet
- Chi Square Test in Health SciencesDocument16 pagesChi Square Test in Health SciencesCrisPinosNo ratings yet
- Maruo Etal 2017Document15 pagesMaruo Etal 2017Andre Luiz GrionNo ratings yet
- 03 ES Regression CorrelationDocument14 pages03 ES Regression CorrelationMuhammad AbdullahNo ratings yet
- Statistical Power As A Function of Cronbach Alpha of Instrument Questionnaire ItemsDocument9 pagesStatistical Power As A Function of Cronbach Alpha of Instrument Questionnaire ItemsAngelo PeraNo ratings yet
- Rosenbaum 1983Document15 pagesRosenbaum 1983Cassiano SouzaNo ratings yet
- 1 Matching: M. Anderson, Lecture Notes 6, ARE 213 Spring 2008Document22 pages1 Matching: M. Anderson, Lecture Notes 6, ARE 213 Spring 2008Khánh MinhNo ratings yet
- Analysis of Correlation Structures Using Generalized Estimating Equation Approach For Longitudinal Binary DataDocument13 pagesAnalysis of Correlation Structures Using Generalized Estimating Equation Approach For Longitudinal Binary Datarenzo_ortizNo ratings yet
- alturkAMS21 24 2017Document32 pagesalturkAMS21 24 2017medixbtcNo ratings yet
- Yang2013 - Fuzzy AHP For Flood RiskDocument18 pagesYang2013 - Fuzzy AHP For Flood RiskLi BertNo ratings yet
- Regression and CorrelationDocument13 pagesRegression and CorrelationzNo ratings yet
- Casero - Etal - 2014 - Finite Element Updating Using Cross-Entropy Combined With Random Field TheoryDocument13 pagesCasero - Etal - 2014 - Finite Element Updating Using Cross-Entropy Combined With Random Field TheoryArturoNo ratings yet
- MIT14 382S17 Lec6Document26 pagesMIT14 382S17 Lec6jarod_kyleNo ratings yet
- Prop ScoresDocument77 pagesProp ScoresAlexander KorovinNo ratings yet
- GeeDocument40 pagesGeeHector GarciaNo ratings yet
- Weighted Quantile Regression For Longitudinal DataDocument22 pagesWeighted Quantile Regression For Longitudinal DataAgossou Alex AgbahideNo ratings yet
- Mean Absolute Deviation About Median As A Tool ofDocument7 pagesMean Absolute Deviation About Median As A Tool ofMuhammad SatriyoNo ratings yet
- Robust Mediation Analysis - The R Package RobmedDocument45 pagesRobust Mediation Analysis - The R Package RobmedLeonardo Daniel Rivera ValdezNo ratings yet
- Entropy: Entropic Uncertainty Relations Via Direct-Sum Majorization Relation For Generalized MeasurementsDocument14 pagesEntropy: Entropic Uncertainty Relations Via Direct-Sum Majorization Relation For Generalized MeasurementsPudretexDNo ratings yet
- SCH Luc HterDocument21 pagesSCH Luc HterlindaNo ratings yet
- A Tutorial On Correlation CoefficientsDocument13 pagesA Tutorial On Correlation CoefficientsJust MahasiswaNo ratings yet
- This Content Downloaded From 117.227.34.195 On Fri, 18 Nov 2022 17:23:35 UTCDocument11 pagesThis Content Downloaded From 117.227.34.195 On Fri, 18 Nov 2022 17:23:35 UTCsherlockholmes108No ratings yet
- Statistical Tests of Models That Include Mediating VariablesDocument14 pagesStatistical Tests of Models That Include Mediating VariablesSergioSilvaNo ratings yet
- A Trip Mode Choice Model With Endogeneity in Explanatory Variables A Trip Mode Choice Model With Endogeneity in Explanatory Variables A Trip Mode Choice Model With Endogeneity inDocument8 pagesA Trip Mode Choice Model With Endogeneity in Explanatory Variables A Trip Mode Choice Model With Endogeneity in Explanatory Variables A Trip Mode Choice Model With Endogeneity inimamrohaniNo ratings yet
- Module 6 RM: Advanced Data Analysis TechniquesDocument23 pagesModule 6 RM: Advanced Data Analysis TechniquesEm JayNo ratings yet
- ch02 Edit v2Document69 pagesch02 Edit v222000492No ratings yet
- AIMS-Lukacs Burnman Anderson-2010Document9 pagesAIMS-Lukacs Burnman Anderson-2010Dick LiangNo ratings yet
- Spearman's Rank Correlation: XX X, and Y, With Sample Values X Y With Sample ValuesDocument8 pagesSpearman's Rank Correlation: XX X, and Y, With Sample Values X Y With Sample ValuesIshtar Katherine ChanNo ratings yet
- Sciencedirect: Categorical Principal Component Logistic Regression: A Case Study For Housing Loan ApprovalDocument7 pagesSciencedirect: Categorical Principal Component Logistic Regression: A Case Study For Housing Loan ApprovallaylaNo ratings yet
- Case Studies in PK Manual 22-23Document98 pagesCase Studies in PK Manual 22-23Rasha MohammadNo ratings yet
- Nannicini 2007 Simulation Based Sensitivity Analysis For Matching EstimatorsDocument17 pagesNannicini 2007 Simulation Based Sensitivity Analysis For Matching EstimatorsVulcana IvoneteNo ratings yet
- Huang Lee Ullah Steinlike Shrinkage 2018Document35 pagesHuang Lee Ullah Steinlike Shrinkage 2018HandisNo ratings yet
- Estimation For Multivariate Linear Mixed ModelsDocument6 pagesEstimation For Multivariate Linear Mixed ModelsFir DausNo ratings yet
- Jurnal Kultura 2013Document8 pagesJurnal Kultura 2013Cut LatifahNo ratings yet
- Jurnal Kultura 2013Document8 pagesJurnal Kultura 2013Cut LatifahNo ratings yet
- Research Article: Bootstrapping Nonparametric Prediction Intervals For Conditional Value-at-Risk With HeteroscedasticityDocument7 pagesResearch Article: Bootstrapping Nonparametric Prediction Intervals For Conditional Value-at-Risk With HeteroscedasticityAyudikta Fitri SalaamNo ratings yet
- Answer Key Assignment No. 3 Chapters 11 12 (AY2021-2022 (2nd Sem)Document8 pagesAnswer Key Assignment No. 3 Chapters 11 12 (AY2021-2022 (2nd Sem)REGINE CUEVASNo ratings yet
- WIBO-THINK Wi-Fi Robot Controller Module: 2-1: Pin DescriptionDocument13 pagesWIBO-THINK Wi-Fi Robot Controller Module: 2-1: Pin DescriptionAbolfazl HabibiNo ratings yet
- NLT Canadian Design Construction Guide PDFDocument150 pagesNLT Canadian Design Construction Guide PDFCatalina MirandaNo ratings yet
- Hardware Development Guide For The MIMXRT1020 Processor: Application NoteDocument24 pagesHardware Development Guide For The MIMXRT1020 Processor: Application NoteKaganovichNo ratings yet
- Hwa 2Document10 pagesHwa 2imryuk19No ratings yet
- Titulaciones en Medios No AcuososDocument6 pagesTitulaciones en Medios No Acuosospepe_nabasNo ratings yet
- One Mark in Visual Basic 6.0Document4 pagesOne Mark in Visual Basic 6.0vijayakumar2k9398367% (3)
- Guemisa: A-MAC-B97Document1 pageGuemisa: A-MAC-B97Gustavo YbañezNo ratings yet
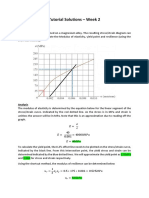
- Week 2 - Tutorial SolutionsDocument4 pagesWeek 2 - Tutorial SolutionsAsian JesusNo ratings yet
- FARM Machinery and Implements ModuleDocument71 pagesFARM Machinery and Implements Moduledesta aberaNo ratings yet
- Redlion MPiec Modbus Configuration W Crimson2 v007Document14 pagesRedlion MPiec Modbus Configuration W Crimson2 v007minhtutran1983No ratings yet
- Conceptual Database DesignDocument22 pagesConceptual Database DesignMunNo ratings yet
- What Is X-Ray? X-Rays Are Short-Wavelength and High-Energy Beams of Electromagnetic RadiationDocument7 pagesWhat Is X-Ray? X-Rays Are Short-Wavelength and High-Energy Beams of Electromagnetic RadiationZahir Rayhan JhonNo ratings yet
- R7220402 Control SystemsDocument1 pageR7220402 Control SystemssivabharathamurthyNo ratings yet
- 2020 Book IntroductionToPermanentPlugAndDocument285 pages2020 Book IntroductionToPermanentPlugAndCarlos Garrido100% (5)
- Test Sample 1 - May 30 2020 Easergy P3U30 Settings Report 2020-05-30 14 - 43 - 09Document255 pagesTest Sample 1 - May 30 2020 Easergy P3U30 Settings Report 2020-05-30 14 - 43 - 09jobpei2No ratings yet
- 6 STD Text Book Part 2Document112 pages6 STD Text Book Part 2Parthasarathy SeshadriNo ratings yet
- 2 Block SystemDocument25 pages2 Block SystemSovia DumiyantiNo ratings yet
- Doppler Effect, Red Shift and Hubble's LawDocument13 pagesDoppler Effect, Red Shift and Hubble's LawNayeem HakimNo ratings yet
- S7500 Troubleshooting PDFDocument53 pagesS7500 Troubleshooting PDFDaniel CekulNo ratings yet
- Burner 3.4 P LamborghiniDocument18 pagesBurner 3.4 P LamborghiniJose Guillermo Vasquez LagosNo ratings yet
- Respon KognitifDocument123 pagesRespon KognitifSyaeful GunawanNo ratings yet
- Sharp Interview QuestionsDocument133 pagesSharp Interview Questionsparit_qa8946No ratings yet
- Computer SC Specimen QP Class XiDocument7 pagesComputer SC Specimen QP Class XiAshutosh Raj0% (1)
- ModdingDocument24 pagesModdingsg 85No ratings yet
- Cve40001 Kho+lee+tan PVD Sem1 2015Document29 pagesCve40001 Kho+lee+tan PVD Sem1 2015alexheeNo ratings yet
- Convertisseur Interface Manageable X21 V35 E1 E1 Loop E1500 2sDocument5 pagesConvertisseur Interface Manageable X21 V35 E1 E1 Loop E1500 2sgaryelingenieroNo ratings yet
- LET ReviewerDocument4 pagesLET ReviewerJaycee Silveo SeranNo ratings yet