You might also like
- Identifying Piaget's StagesDocument2 pagesIdentifying Piaget's StagesStephanie AltenhofNo ratings yet
- Unit-1Document23 pagesUnit-1Ashritha RokkamNo ratings yet
- MLT Q and ADocument19 pagesMLT Q and Aharigoutham627No ratings yet
- UNIT 1Document20 pagesUNIT 1moviedownloadasNo ratings yet
- Unit 4Document45 pagesUnit 4farhandevil111No ratings yet
- Module 2 PDFDocument26 pagesModule 2 PDFBirendra Kumar Baniya 1EW19CS024No ratings yet
- Introduction To Machine Learning: Prof. (DR.) Honey Sharma Reference BooksDocument26 pagesIntroduction To Machine Learning: Prof. (DR.) Honey Sharma Reference BooksDirector GGINo ratings yet
- Designing A Learning SystemDocument21 pagesDesigning A Learning SystembhavaniNo ratings yet
- Machine Learning Module 1 Introduction and Concept LearningDocument28 pagesMachine Learning Module 1 Introduction and Concept LearningTejas SharmaNo ratings yet
- Visit:: Join Telegram To Get Instant Updates: Contact: MAIL: Instagram: Instagram: Whatsapp ShareDocument27 pagesVisit:: Join Telegram To Get Instant Updates: Contact: MAIL: Instagram: Instagram: Whatsapp ShareSid MohammedNo ratings yet
- ML Lec 03 Machine Learning ProcessDocument42 pagesML Lec 03 Machine Learning ProcessGhulam RasoolNo ratings yet
- Intro - Types of Machine LearningDocument24 pagesIntro - Types of Machine LearningPratul PandeyNo ratings yet
- Video Tutorial: Machine Learning 17CS73Document27 pagesVideo Tutorial: Machine Learning 17CS73Mohammed Danish100% (2)
- Designing A Learning SystemDocument12 pagesDesigning A Learning SystemPooja DixitNo ratings yet
- Module 1Document27 pagesModule 1Devaraj DevNo ratings yet
- Unit 1Document8 pagesUnit 1vvvcxzzz3754No ratings yet
- ML Notes TBDocument5 pagesML Notes TBrayudu shivaNo ratings yet
- ML Unit1Document70 pagesML Unit1Hari Karthik ChowdaryNo ratings yet
- Machine LearningDocument6 pagesMachine LearningJudah PraiseNo ratings yet
- Module 1 Notes PDFDocument26 pagesModule 1 Notes PDFLaxmiNo ratings yet
- MachineLearning (All Module)Document33 pagesMachineLearning (All Module)Khateeb AhmadNo ratings yet
- ML-UNIT-1 - Introduction PART-1Document60 pagesML-UNIT-1 - Introduction PART-1Dheeraj Kandoor AITNo ratings yet
- Chapter 5 - LearningDocument16 pagesChapter 5 - LearningSeyo KasayeNo ratings yet
- 02 MLDocument23 pages02 MLSulax Suresh100% (2)
- Unit - 5.1 - Introduction To Machine LearningDocument38 pagesUnit - 5.1 - Introduction To Machine LearningHarsh officialNo ratings yet
- null-5Document16 pagesnull-5eshakalifathimaNo ratings yet
- Machine Learning IntroductionDocument3 pagesMachine Learning Introduction19- 5b7No ratings yet
- Designing A Learing SystemDocument5 pagesDesigning A Learing System19wh1a05h4 Taninki Keerthi PhanisreeNo ratings yet
- Unit 4 Machine Learning Tools, Techniques and ApplicationsDocument78 pagesUnit 4 Machine Learning Tools, Techniques and ApplicationsJyothi PulikantiNo ratings yet
- Introduction - ML NOTESDocument17 pagesIntroduction - ML NOTESAkash SinghNo ratings yet
- Unit-1 MLTDocument51 pagesUnit-1 MLTrishuraijaishreeramNo ratings yet
- Svit Dept of Computer Science and Engineering Machine Learning B.Tech IiiyrDocument53 pagesSvit Dept of Computer Science and Engineering Machine Learning B.Tech IiiyrManisha ManuNo ratings yet
- ML Unit IDocument43 pagesML Unit IVasu 22No ratings yet
- UNIT-1 Introduction To Machine LearningDocument21 pagesUNIT-1 Introduction To Machine LearningtimiNo ratings yet
- ML Techniques PresentationDocument45 pagesML Techniques PresentationfareenfarzanawahedNo ratings yet
- AI - Module-III (Introduction To ML)Document20 pagesAI - Module-III (Introduction To ML)AnkushNo ratings yet
- Machine Learning Tutorial: A Complete Guide to ML ConceptsDocument44 pagesMachine Learning Tutorial: A Complete Guide to ML Conceptsvepowo LandryNo ratings yet
- Machine LearningDocument111 pagesMachine LearningDghddfNo ratings yet
- Machine Learning Concepts and GoalsDocument22 pagesMachine Learning Concepts and Goalsravi joshiNo ratings yet
- Introduction to Machine Learning in 40 CharactersDocument59 pagesIntroduction to Machine Learning in 40 CharactersJAYACHANDRAN J 20PHD0157No ratings yet
- Introduction To MLDocument50 pagesIntroduction To MLshankar patil100% (1)
- Aiml McaDocument38 pagesAiml McaVishal AnandNo ratings yet
- Unit 2Document63 pagesUnit 2Mdv PrasadNo ratings yet
- Unit1_class4_ML_modelsDocument50 pagesUnit1_class4_ML_modelsTanush ReddyNo ratings yet
- Unit 4 Machine LearningDocument51 pagesUnit 4 Machine Learningshahidshaikh9936No ratings yet
- Machine Learning Types and ApplicationsDocument27 pagesMachine Learning Types and ApplicationsnagabushanamNo ratings yet
- Machine Learning NotesDocument19 pagesMachine Learning NotesAbir BaidyaNo ratings yet
- Machine Learning: What is it and Top ApplicationsDocument8 pagesMachine Learning: What is it and Top Applicationsshreya sarkarNo ratings yet
- Machine Learning: Presentation By: C. Vinoth Kumar SSN College of EngineeringDocument15 pagesMachine Learning: Presentation By: C. Vinoth Kumar SSN College of EngineeringLekshmiNo ratings yet
- Mod3 - Learning TheoryDocument10 pagesMod3 - Learning TheoryKnightfury MilanNo ratings yet
- ML Unit-1 Material WORDDocument27 pagesML Unit-1 Material WORDafreed khanNo ratings yet
- Flow Diagram of Machine Learning or Life Cycle of Machine LearningDocument91 pagesFlow Diagram of Machine Learning or Life Cycle of Machine LearningJay MangukiyaNo ratings yet
- Unit I Notes Machine Learning Techniques 1Document21 pagesUnit I Notes Machine Learning Techniques 1Ayush SinghNo ratings yet
- Internship ReportDocument31 pagesInternship ReportNitesh BishtNo ratings yet
- ML PPTS MergedDocument514 pagesML PPTS MergedPGNo ratings yet
- Multi Purposed Question Answer Generator With NLPDocument7 pagesMulti Purposed Question Answer Generator With NLPabir040995.hosenNo ratings yet
- Machine Learning with PythonDocument36 pagesMachine Learning with PythonsdbfhvsdfhvsdhvdsNo ratings yet
- ML UNIT-1 Notes PDFDocument22 pagesML UNIT-1 Notes PDFAnil KrishnaNo ratings yet
- Next Level Deep Machine Learning: Complete Tips and Tricks to Deep Machine LearningFrom EverandNext Level Deep Machine Learning: Complete Tips and Tricks to Deep Machine LearningNo ratings yet
- Jumpstart Your ML Journey: A Beginner's Handbook to SuccessFrom EverandJumpstart Your ML Journey: A Beginner's Handbook to SuccessNo ratings yet
- Mastering Machine Learning Basics: A Beginner's CompanionFrom EverandMastering Machine Learning Basics: A Beginner's CompanionNo ratings yet
- Synopsis Format (BASR)Document7 pagesSynopsis Format (BASR)Muhammad Tanzeel Qaisar DogarNo ratings yet
- Class Size and Academic Performance of Primary Grade Learners in The City Schools Division of MeycauayanDocument15 pagesClass Size and Academic Performance of Primary Grade Learners in The City Schools Division of MeycauayanLope Adrian C. AcapulcoNo ratings yet
- 6 Use of Artificial IntelliganceDocument20 pages6 Use of Artificial IntelliganceHossam HashieshNo ratings yet
- JSF - Chapter 5 - Ethnopragmatics PDFDocument2 pagesJSF - Chapter 5 - Ethnopragmatics PDFJudith FetalverNo ratings yet
- Methods of Foreign Language Education SyllabusDocument11 pagesMethods of Foreign Language Education SyllabusAiym MaratNo ratings yet
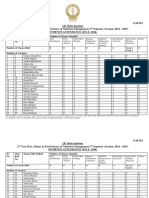
- Annual Statistics of Colleges Affiliated To Visvesvaraya Technological University Belgaum YEAR 2019-2020Document42 pagesAnnual Statistics of Colleges Affiliated To Visvesvaraya Technological University Belgaum YEAR 2019-2020Harsha GuptaNo ratings yet
- Reaction To Frustration TestDocument7 pagesReaction To Frustration TestRushikesh MaidNo ratings yet
- Used Car Price PredictionDocument20 pagesUsed Car Price Predictionbasantadc12No ratings yet
- Chapter 9. Responsible SelfDocument12 pagesChapter 9. Responsible SelfJaya CajalneNo ratings yet
- Human Resource Development: BY Dhirendra SinghDocument15 pagesHuman Resource Development: BY Dhirendra Singhdhirendrasisodia78% (9)
- STUDENT ATTENDANCEDocument2 pagesSTUDENT ATTENDANCErewtasNo ratings yet
- BookDocument166 pagesBookBalcha bulaNo ratings yet
- Applicationof Systems Theoryin EducationDocument5 pagesApplicationof Systems Theoryin Educationmary cristine veñegasNo ratings yet
- Levels of ComprehensionDocument3 pagesLevels of ComprehensionMikaela Mae MercadoNo ratings yet
- Building Social Literacy Skills in EducationDocument11 pagesBuilding Social Literacy Skills in EducationKim ArdaisNo ratings yet
- Analisa Situasi Sistem Informasi Kesehatan NasionalDocument9 pagesAnalisa Situasi Sistem Informasi Kesehatan NasionalSulalita SaraswatiNo ratings yet
- Format For Research Paper (Immersion)Document4 pagesFormat For Research Paper (Immersion)Dayanara LabardaNo ratings yet
- Basic Engineering Measurement AGE 2310Document20 pagesBasic Engineering Measurement AGE 2310ahmed gamalNo ratings yet
- Modified Criteria-1Document22 pagesModified Criteria-1GEOGI100% (1)
- SHS UCSP Week 7 - Review w1-3Document100 pagesSHS UCSP Week 7 - Review w1-3Eric EscobarNo ratings yet
- Developing a Product Team ChecklistDocument5 pagesDeveloping a Product Team ChecklistMohammad AmirNo ratings yet
- City of Seattle Generative Artificial Intelligence PolicyDocument5 pagesCity of Seattle Generative Artificial Intelligence PolicyGeekWireNo ratings yet
- How Culture Impacts Brand Perceptions Across NationsDocument12 pagesHow Culture Impacts Brand Perceptions Across NationsFlorencia IgnarioNo ratings yet
- Candidate Elimination AlgoDocument13 pagesCandidate Elimination AlgodibankarndNo ratings yet
- Functions of Code Switching in ELT ClassroomsDocument19 pagesFunctions of Code Switching in ELT Classroomsnero daunaxilNo ratings yet
- Feedback For Unit 2 Assignment Dropbox - CE340 Introduction To Autism Spectrum Disorder in Young Children - Purdue University GlobalDocument4 pagesFeedback For Unit 2 Assignment Dropbox - CE340 Introduction To Autism Spectrum Disorder in Young Children - Purdue University GlobalyaiteNo ratings yet
- Module 2 Variables and DataDocument5 pagesModule 2 Variables and DataMyles DaroyNo ratings yet
- The Use of A Bar Model Drawing To Teach Word Problem Solving To Students With Mathematics Difficulties - Lisa LDocument7 pagesThe Use of A Bar Model Drawing To Teach Word Problem Solving To Students With Mathematics Difficulties - Lisa Lapi-518387243No ratings yet
- Lesson 3 EthicsDocument26 pagesLesson 3 EthicsCharles MateoNo ratings yet