You might also like
- 05 Data Storage ServicesDocument75 pages05 Data Storage ServicesFajri D RahmawanNo ratings yet
- Azure Synapse GuidebookDocument15 pagesAzure Synapse Guidebooktimmy montgomeryNo ratings yet
- Study Guide For Exam DP-203 - Data Engineering On Microsoft Azure - Microsoft LearnDocument4 pagesStudy Guide For Exam DP-203 - Data Engineering On Microsoft Azure - Microsoft Learnnirmalworks93No ratings yet
- DP 900t00a Enu Powerpoint 04Document23 pagesDP 900t00a Enu Powerpoint 04Susmita DeyNo ratings yet
- 02 Data Storage ServicesDocument55 pages02 Data Storage Serviceskanedakodama100% (1)
- Eb Cloud Data Lake Comparison Guide enDocument13 pagesEb Cloud Data Lake Comparison Guide enAsgharNo ratings yet
- 100 Dataengineering Interview Questions TRRaveendra 1694654407Document58 pages100 Dataengineering Interview Questions TRRaveendra 1694654407Sree KrithNo ratings yet
- 09 - Azure Data Engineering CheatsheetDocument37 pages09 - Azure Data Engineering CheatsheetancgateNo ratings yet
- Graph DatabseDocument2 pagesGraph DatabseUrickel SognaNo ratings yet
- What Is Azure Data EngineerDocument74 pagesWhat Is Azure Data EngineerBala Krishna ENo ratings yet
- Azure Data Factory Interview Questions and AnswerDocument12 pagesAzure Data Factory Interview Questions and AnswerMadhumitha PodishettyNo ratings yet
- DMDW 7Document30 pagesDMDW 7Anu agarwalNo ratings yet
- Big Data PDFDocument18 pagesBig Data PDFAnushka SinhaNo ratings yet
- Azure Data Lake Analytics and U-SQLDocument17 pagesAzure Data Lake Analytics and U-SQLRahaman AbdulNo ratings yet
- ALDA IntegrationDocument41 pagesALDA IntegrationSantiago Pérez GuerreroNo ratings yet
- Driving Value From Big Data Rre HadoopDocument10 pagesDriving Value From Big Data Rre HadoopfraNo ratings yet
- Integrating Diverse Data Sources in Tableau To Elevate PerformanceDocument5 pagesIntegrating Diverse Data Sources in Tableau To Elevate PerformanceInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Data Bricks - BDCSDocument6 pagesData Bricks - BDCSSliptnock MartinezNo ratings yet
- 2 Technology BlocksDocument29 pages2 Technology BlocksNaveen ReddyNo ratings yet
- Graph DatabaseDocument64 pagesGraph Databaserim-10-ansNo ratings yet
- Azure Databricks OverviewDocument4 pagesAzure Databricks Overviewtsoh100% (1)
- What Is Data?Document27 pagesWhat Is Data?Ivan Estuardo Echeverría CatalánNo ratings yet
- Devinder Gill - DE - ResumeDocument5 pagesDevinder Gill - DE - Resumeashish ojhaNo ratings yet
- Ebook Solving Business Needs With Delta Lakev2Document43 pagesEbook Solving Business Needs With Delta Lakev2awadheshNo ratings yet
- Data FactoryDocument26 pagesData FactoryParminder Singh Kailey100% (2)
- Google Cloud Fund M8 Big Data and Machine Learning in The CloudDocument44 pagesGoogle Cloud Fund M8 Big Data and Machine Learning in The CloudGiuseppe TrittoNo ratings yet
- Lakehouse AnalyticsDocument20 pagesLakehouse Analyticsnahuel.bourdichonNo ratings yet
- BDToolsDocument15 pagesBDToolsTanishq UpretiNo ratings yet
- BY K Madhavi Data ArchitectDocument24 pagesBY K Madhavi Data ArchitectMadhavi KareddyNo ratings yet
- Cloud Based Developer - RizwanShaikh (3y - 8m)Document1 pageCloud Based Developer - RizwanShaikh (3y - 8m)amenahrexecutiveNo ratings yet
- Naukri GRRamachandra (7y 6m)Document2 pagesNaukri GRRamachandra (7y 6m)Arup NaskarNo ratings yet
- Naukri Rajasekhar (13y 0m)Document3 pagesNaukri Rajasekhar (13y 0m)Arup NaskarNo ratings yet
- Architecting For The Cloud: ArchivedDocument50 pagesArchitecting For The Cloud: ArchivedArun KumarNo ratings yet
- DA204 - DWC Road Map and StrategyDocument17 pagesDA204 - DWC Road Map and StrategyAlex ZiminNo ratings yet
- Unit 4 Spark CassendraDocument41 pagesUnit 4 Spark Cassendradownloadjain123No ratings yet
- AzureDataLake WhatWhyHow MelissaCoatesDocument66 pagesAzureDataLake WhatWhyHow MelissaCoatesChristopherNo ratings yet
- Unified Data Service: Databricks RuntimeDocument2 pagesUnified Data Service: Databricks RuntimerNo ratings yet
- BI Enhancement in SQL Server 2016Document44 pagesBI Enhancement in SQL Server 2016Atul SharmaNo ratings yet
- Azure DataEngineer TrainingDocument12 pagesAzure DataEngineer Trainingsrinivasarao dhanikondaNo ratings yet
- What Is A Data Lake - Definition From SearchDataManagementDocument11 pagesWhat Is A Data Lake - Definition From SearchDataManagementAhmed khaled mohamed seadaNo ratings yet
- Microsoft Defender For Cloud PDF-Slides-123Document53 pagesMicrosoft Defender For Cloud PDF-Slides-123Siddharth AbbineniNo ratings yet
- AWS To Azure Services Comparison High Level PDFDocument28 pagesAWS To Azure Services Comparison High Level PDFBhavanesh AsarNo ratings yet
- Azure Data FactoryDocument5 pagesAzure Data Factoryvr.sf99No ratings yet
- Azure Data Factory by Example: Practical Implementation for Data EngineersFrom EverandAzure Data Factory by Example: Practical Implementation for Data EngineersNo ratings yet
- Slides 111Document49 pagesSlides 111yoyoboy6996No ratings yet
- Jim Xiang: - Santa Clara, CADocument5 pagesJim Xiang: - Santa Clara, CANuclear WifeNo ratings yet
- DSX Developer Ebook4 FINAL PDFDocument27 pagesDSX Developer Ebook4 FINAL PDFrahulbisht1694No ratings yet
- Data Modeling: Jak Na CheatsheetDocument3 pagesData Modeling: Jak Na CheatsheetHanane Abdelmadjid AllalNo ratings yet
- 1 Data ModelDocument1 page1 Data ModelMe. FORTUSNo ratings yet
- M1 - Introduction To Data EngineeringDocument65 pagesM1 - Introduction To Data EngineeringEdgar SanchezNo ratings yet
- Saikiran Data - Engineer ResumeDocument7 pagesSaikiran Data - Engineer Resumeramu_uppadaNo ratings yet
- PDF NotesDocument79 pagesPDF Notespraveen kumarNo ratings yet
- DSBD Cae IiiDocument4 pagesDSBD Cae Iiihvg yughvbnjvNo ratings yet
- Azure Synapse AnalyticsDocument8 pagesAzure Synapse AnalyticsRahaman AbdulNo ratings yet
- Move Oracle Workloads and Data To Microsoft Azure With Shareplex by Quest Datasheet 158066Document2 pagesMove Oracle Workloads and Data To Microsoft Azure With Shareplex by Quest Datasheet 158066Kupusha CheteNo ratings yet
- Adbase Presentation Group 4Document60 pagesAdbase Presentation Group 4brittain markaleNo ratings yet
- Day 1 - Boot Camp Intro To GraphDocument138 pagesDay 1 - Boot Camp Intro To GraphĐức NguyễnNo ratings yet
- Nosql What Does It MeanDocument8 pagesNosql What Does It MeannadeemNo ratings yet
- 4 8 SQL Server Basics MaterialDocument6 pages4 8 SQL Server Basics MaterialMuhammad Arsalan AshrafNo ratings yet
- Gartner Reprint PDFDocument24 pagesGartner Reprint PDFEdwards TranNo ratings yet
- Palacio A. Distributed Data Systems With Azure Databricks 2021Document414 pagesPalacio A. Distributed Data Systems With Azure Databricks 2021JuniorFerreira100% (1)
- Pandas 6Document10 pagesPandas 6JuniorFerreiraNo ratings yet
- Learn Python The Right WayDocument456 pagesLearn Python The Right WayJuniorFerreira100% (1)
- Import As: Pandas PD Titanic - Data PD - Read - CSV Titanic - Data - HeadDocument12 pagesImport As: Pandas PD Titanic - Data PD - Read - CSV Titanic - Data - HeadJuniorFerreiraNo ratings yet
- Notes PythonDocument109 pagesNotes PythonJuniorFerreiraNo ratings yet
- NosenseDocument115 pagesNosenseJuniorFerreiraNo ratings yet
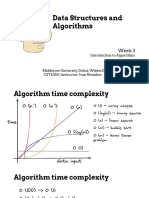
- Data Structures and Algorithms: Week 3Document13 pagesData Structures and Algorithms: Week 3JuniorFerreiraNo ratings yet
- Pandas 4Document299 pagesPandas 4JuniorFerreiraNo ratings yet
- CSV PythonaDocument7 pagesCSV PythonaJuniorFerreiraNo ratings yet
- 4 CaminhoDocument90 pages4 CaminhoJuniorFerreiraNo ratings yet
- HVR WhitePaper Continuous Data IntegrationDocument8 pagesHVR WhitePaper Continuous Data Integrationrobin69hNo ratings yet
- Etl VS EltDocument8 pagesEtl VS EltShashank GangadharabhatlaNo ratings yet
- ASUG82186 - SAP S4HANA and SAP Analytics (Focus On SAP Analytics Cloud) Where To Do WhatDocument58 pagesASUG82186 - SAP S4HANA and SAP Analytics (Focus On SAP Analytics Cloud) Where To Do Whatepreddy1100% (3)
- Multi Version Two-Phase Locking ProtocolDocument2 pagesMulti Version Two-Phase Locking ProtocolAnjali Ganesh Jivani100% (9)
- ISO27k 27001 Maltego Mind MapDocument51 pagesISO27k 27001 Maltego Mind MapTannyk Ponce100% (1)
- CV Faisal BalochDocument3 pagesCV Faisal BalochChaudry NadeemNo ratings yet
- Lecture 6 BigDataDocument61 pagesLecture 6 BigDataحذيفة فلاحNo ratings yet
- Petries Case StudyDocument3 pagesPetries Case Studytengkukieyra67% (3)
- Understand MD - FK - REFDocument2 pagesUnderstand MD - FK - REFVIVEK VERMANo ratings yet
- Agile Data ModelingDocument5 pagesAgile Data ModelingBlitz DocumentNo ratings yet
- Making Big Data Simple With DatabricksDocument25 pagesMaking Big Data Simple With DatabrickstoddsawickiNo ratings yet
- Faculty - Computer Sciences and Mathematic - 2020 - Session 1 - Degree - Isp581Document4 pagesFaculty - Computer Sciences and Mathematic - 2020 - Session 1 - Degree - Isp581Faiza ZainNo ratings yet
- Computer Applications Presentation: Name-Anurag Kumar ROLL NO. - 12407Document14 pagesComputer Applications Presentation: Name-Anurag Kumar ROLL NO. - 12407Manish YadavNo ratings yet
- DSS - Final Bank QuestionDocument50 pagesDSS - Final Bank Questionيوسف ميلاد يوسف جريس ١٩١٠٠٢٣٩No ratings yet
- Federal Government Data Maturity ModelDocument8 pagesFederal Government Data Maturity ModelPedro Guillermo Martínez FernándezNo ratings yet
- Oracle Dba Resume 8+ YearsDocument5 pagesOracle Dba Resume 8+ YearsFederico Candia50% (2)
- SAP - ERP IntroductionDocument5 pagesSAP - ERP IntroductionPhine TanayNo ratings yet
- Supply Chain Management at FoxconnDocument28 pagesSupply Chain Management at FoxconnPaddy Wong0% (1)
- SQL DatabaseDocument1 pageSQL Databasehot_ice28No ratings yet
- 5v Big Data ImpletamentationDocument1 page5v Big Data ImpletamentationMaira Liceth GARCIA PEREZNo ratings yet
- Ds SalariesDocument94 pagesDs SalariesVictorSanchesNo ratings yet
- BI AssignmentDocument14 pagesBI AssignmentDunil RiviruNo ratings yet
- Data Archiving Sap Business WarehouseDocument66 pagesData Archiving Sap Business Warehousesmiks100% (1)
- Introduction To DocumentDB A NoSQL JSONDocument697 pagesIntroduction To DocumentDB A NoSQL JSONAlberto FasceNo ratings yet
- OBIEE Interview QuestionsDocument59 pagesOBIEE Interview QuestionsKritika GuptaNo ratings yet
- NormalizationDocument39 pagesNormalizationiasiimwe2No ratings yet
- Dev OpsDocument29 pagesDev Opssama akramNo ratings yet
- 1 - Pengenalan Enterprise ArchitectureDocument37 pages1 - Pengenalan Enterprise ArchitectureSILVERNo ratings yet
- Summary-Booklet - Jenna TutorialsDocument15 pagesSummary-Booklet - Jenna TutorialsjdsterNo ratings yet
- Properties & States of TransactionDocument2 pagesProperties & States of Transactiondibyajyoti prustyNo ratings yet