You might also like
- Pyt Manual 1Document85 pagesPyt Manual 1Hrithik KumarNo ratings yet
- Titanic DataDocument5 pagesTitanic DataDhanasekarNo ratings yet
- Model and Apply ModelDocument8 pagesModel and Apply ModelMichael O. AdegbenroNo ratings yet
- Heart Disease Classification ML Assignment - Jupyter NotebookDocument7 pagesHeart Disease Classification ML Assignment - Jupyter Notebookfurole sammyceNo ratings yet
- Pandas: Import As Import AsDocument40 pagesPandas: Import As Import Asacaro222No ratings yet
- Tutorial Data Visualization Pandas Matplotlib SeabornDocument32 pagesTutorial Data Visualization Pandas Matplotlib Seabornbida22-016No ratings yet
- Instructions:: Mltest2question - Jupyter NotebookDocument6 pagesInstructions:: Mltest2question - Jupyter NotebookAniruddha TrivediNo ratings yet
- 7-8 Feature Engineering 101-NormalizationDocument8 pages7-8 Feature Engineering 101-NormalizationKhan RafiNo ratings yet
- 01-Logistic Regression With PythonDocument12 pages01-Logistic Regression With PythonHellem BiersackNo ratings yet
- Titanic Dataset 1677256844Document27 pagesTitanic Dataset 1677256844Mariappan RNo ratings yet
- Decision Tree Algorithm 1677030641Document9 pagesDecision Tree Algorithm 1677030641juanNo ratings yet
- C2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsDocument38 pagesC2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsSarah Mendes100% (1)
- STA1007S Lab 3: Plots (II) and Sub-Setting: "Sample"Document10 pagesSTA1007S Lab 3: Plots (II) and Sub-Setting: "Sample"mlunguNo ratings yet
- Project Logistic RegressionDocument14 pagesProject Logistic RegressionCalo Soft100% (1)
- 1.diagnosis Using MLDocument69 pages1.diagnosis Using MLChoral WealthNo ratings yet
- Lab4-IDA - Ipynb - ColaboratoryDocument8 pagesLab4-IDA - Ipynb - ColaboratoryUditNo ratings yet
- PandasDocument82 pagesPandasaacharyadhruv1310No ratings yet
- Advanced Python Unit5 PandasDocument24 pagesAdvanced Python Unit5 Pandasanupamtripathi3656No ratings yet
- Loading The Dataset: Import As Import As Import As Import As From Import From Import From Import From Import From ImportDocument3 pagesLoading The Dataset: Import As Import As Import As Import As From Import From Import From Import From Import From ImportDivyani ChavanNo ratings yet
- What Are Decision Trees?Document9 pagesWhat Are Decision Trees?eng_mahesh1012No ratings yet
- Ai Tools and Applications-LabDocument33 pagesAi Tools and Applications-Labsinguru shankarNo ratings yet
- MainDocument8 pagesMainbwqsouza.cicNo ratings yet
- Pandas Day 4Document7 pagesPandas Day 4Ali KhokharNo ratings yet
- Logistic Regression On Titanic DatasetDocument6 pagesLogistic Regression On Titanic DatasetrajNo ratings yet
- Quiz Coding Question 1Document9 pagesQuiz Coding Question 1Jay PatelNo ratings yet
- EDA Lab ManualDocument93 pagesEDA Lab ManualYash Rox100% (2)
- Pandas NotesDocument54 pagesPandas NotesSáñtôsh KùmãrNo ratings yet
- Python Assignment 1.ipynb - ColaboratoryDocument3 pagesPython Assignment 1.ipynb - ColaboratoryAmritaRupiniNo ratings yet
- 10 - Eda To Prediction DietanicDocument21 pages10 - Eda To Prediction DietanicKhan RafiNo ratings yet
- Human Activity Recognition Using Smartphone DataDocument18 pagesHuman Activity Recognition Using Smartphone DataofficialimranebenNo ratings yet
- MiniProject - ML - Ipynb - ColaboratoryDocument26 pagesMiniProject - ML - Ipynb - ColaboratoryNight MusicNo ratings yet
- 1 Import and Handling Data - Jupyter NotebookDocument9 pages1 Import and Handling Data - Jupyter Notebookvenkatesh mNo ratings yet
- Day44 KNN ClassificationDocument2 pagesDay44 KNN ClassificationIgor FernandesNo ratings yet
- Eda and Prediction On Titanic Dataset: Import LibrariesDocument15 pagesEda and Prediction On Titanic Dataset: Import LibrariesRUSHIRAJ DASU100% (1)
- ML File 211173Document19 pagesML File 211173NANDINI AGGARWAL 211131No ratings yet
- EDA Pipeline FinalDocument7 pagesEDA Pipeline FinalShrikant BadheNo ratings yet
- DL (Pra 01)Document9 pagesDL (Pra 01)Dhanashri SalunkheNo ratings yet
- PandasDocument49 pagesPandassubodhaade2No ratings yet
- CnpartaDocument64 pagesCnpartahema manjunathNo ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document11 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- InitializationDocument16 pagesInitializationlexNo ratings yet
- CATEGORICAL FEATURES With PYTHONDocument24 pagesCATEGORICAL FEATURES With PYTHONNaresha aNo ratings yet
- Import Numpy As NP Import Pandas As PDDocument7 pagesImport Numpy As NP Import Pandas As PDShripad HNo ratings yet
- Ai/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050Document5 pagesAi/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050testNo ratings yet
- LogisticDocument5 pagesLogisticavnimote121No ratings yet
- Machine LearningDocument136 pagesMachine LearningKenssy100% (2)
- Heart Failure PredictionDocument41 pagesHeart Failure PredictionAKKALA VIJAYGOUD100% (1)
- CN Record ManualDocument100 pagesCN Record ManualnekkantisudheerNo ratings yet
- Practical File Questions With AnswersDocument7 pagesPractical File Questions With AnswersPriyanshu KumarNo ratings yet
- Arboles y K-NN - Ipynb - ColaboratoryDocument17 pagesArboles y K-NN - Ipynb - ColaboratoryCharles MaldonadoNo ratings yet
- Fashion MNIST-6Document10 pagesFashion MNIST-6akif barbaros dikmenNo ratings yet
- CS3361 Set2Document6 pagesCS3361 Set2hodit.itNo ratings yet
- Big Data Analytics: LAB 4: - Dynamic ProgrammingDocument7 pagesBig Data Analytics: LAB 4: - Dynamic ProgrammingPrathamesh MoreNo ratings yet
- Logistic RegDocument8 pagesLogistic RegMithila RNo ratings yet
- 6.datawrangling: Data VisulationDocument27 pages6.datawrangling: Data VisulationAnish pandeyNo ratings yet
- Salary Prediction LinearRegressionDocument7 pagesSalary Prediction LinearRegressionYagnesh Vyas100% (1)
- Maxbox Starter100 Data Science StoryDocument10 pagesMaxbox Starter100 Data Science StoryMax KleinerNo ratings yet
- Preprocessing ch.1Document24 pagesPreprocessing ch.1oml78531No ratings yet
- Palacio A. Distributed Data Systems With Azure Databricks 2021Document414 pagesPalacio A. Distributed Data Systems With Azure Databricks 2021JuniorFerreira100% (1)
- Pandas 6Document10 pagesPandas 6JuniorFerreiraNo ratings yet
- Python 2021Document192 pagesPython 2021Miguel Aranda Bilbao100% (1)
- SQL Cheat Sheet For Data Scientists by Tomi Mester PDFDocument12 pagesSQL Cheat Sheet For Data Scientists by Tomi Mester PDFhiren waghela100% (1)
- DS Cheat SheetsDocument18 pagesDS Cheat SheetspunmapiNo ratings yet
- Python CheatsheetDocument51 pagesPython CheatsheetArjun g100% (2)
- Clean Architectures in PythonDocument153 pagesClean Architectures in PythonAlejandra MartínNo ratings yet
- TheCourse Python V2.2Document63 pagesTheCourse Python V2.2September RainNo ratings yet
- Notes PythonDocument109 pagesNotes PythonJuniorFerreiraNo ratings yet
- SQL BasicsDocument58 pagesSQL Basicsjotiba jagtapNo ratings yet
- Pandas 4Document299 pagesPandas 4JuniorFerreiraNo ratings yet
- Pandas 4Document299 pagesPandas 4JuniorFerreiraNo ratings yet
- Learn Python The Right WayDocument456 pagesLearn Python The Right WayJuniorFerreira100% (1)
- Notes PythonDocument109 pagesNotes PythonJuniorFerreiraNo ratings yet
- Pandas TutorialDocument172 pagesPandas TutorialAditya VardhanNo ratings yet
- NosenseDocument115 pagesNosenseJuniorFerreiraNo ratings yet
- CSV PythonaDocument7 pagesCSV PythonaJuniorFerreiraNo ratings yet
- 4 CaminhoDocument90 pages4 CaminhoJuniorFerreiraNo ratings yet
- Nicoll Commentari4Document275 pagesNicoll Commentari4alenpalaNo ratings yet
- BuiltinDocument1 pageBuiltinJuniorFerreiraNo ratings yet
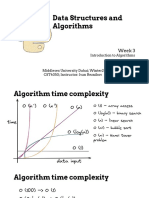
- Data Structures and Algorithms: Week 3Document13 pagesData Structures and Algorithms: Week 3JuniorFerreiraNo ratings yet
- 4 CaminhoDocument90 pages4 CaminhoJuniorFerreiraNo ratings yet
- Nicoll - Psychological Commentaries Vol II GurdjieffDocument410 pagesNicoll - Psychological Commentaries Vol II Gurdjieffapi-3704910100% (2)
- Nicoll - Psychological Commentaries Vol III. Gurdjieff.Document453 pagesNicoll - Psychological Commentaries Vol III. Gurdjieff.api-3704910100% (7)
- Department of Education: Republic of The PhilippinesDocument2 pagesDepartment of Education: Republic of The PhilippinesTips & Tricks TVNo ratings yet
- 28-11-21 - JR - Iit - Star Co-Sc (Model-A) - Jee Adv - 2015 (P-I) - Wat-29 - Key & SolDocument8 pages28-11-21 - JR - Iit - Star Co-Sc (Model-A) - Jee Adv - 2015 (P-I) - Wat-29 - Key & SolasdfNo ratings yet
- Easy Way To Spot Elliott Waves With Just One Secret Tip PDFDocument4 pagesEasy Way To Spot Elliott Waves With Just One Secret Tip PDFJack XuanNo ratings yet
- Dokumen PDFDocument4 pagesDokumen PDFI Komang Agus Adi Merta 07No ratings yet
- 111196688bed Odl TimetabaleDocument1 page111196688bed Odl TimetabaleVIVEK MURDHANINo ratings yet
- Statistics For Business and EconomicsDocument19 pagesStatistics For Business and EconomicsSai MeenaNo ratings yet
- EARTH SCIENCE 2nd Pre Activities Wk1Document11 pagesEARTH SCIENCE 2nd Pre Activities Wk1Rowell PantilaNo ratings yet
- Gemuruh Jiwa: Far Away From HomeDocument1 pageGemuruh Jiwa: Far Away From HomeIvy TingNo ratings yet
- Chemical EtchDocument18 pagesChemical EtchznpfgNo ratings yet
- Once Per Year (RPM Vision Planner) : How To Schedule Your RPM Plan UpdatesDocument1 pageOnce Per Year (RPM Vision Planner) : How To Schedule Your RPM Plan Updatestrav bae0% (1)
- Why Are Engineers Considered An Important Segment of The Society?Document2 pagesWhy Are Engineers Considered An Important Segment of The Society?Angellete D. GacayanNo ratings yet
- Sika Anchorfix®-3030: Product Data SheetDocument5 pagesSika Anchorfix®-3030: Product Data SheetReab SimanthNo ratings yet
- Questions - Homework - 10th - Science - 2021-11-24T05 - 39Document14 pagesQuestions - Homework - 10th - Science - 2021-11-24T05 - 39Saurabh BhattacharyaNo ratings yet
- Cl-9 E. Lang B, Term-1, Week-1, Student Book, PG 4-12, 27-29 July 21, Sub 13.06.21Document9 pagesCl-9 E. Lang B, Term-1, Week-1, Student Book, PG 4-12, 27-29 July 21, Sub 13.06.218C-Ahmed Musawwir - Dj067No ratings yet
- Handbook of Music and Emotion Theory Research Applications 0199230145 9780199230143 CompressDocument990 pagesHandbook of Music and Emotion Theory Research Applications 0199230145 9780199230143 CompressSmyth1702No ratings yet
- China Domestic Style Test ProcessDocument2 pagesChina Domestic Style Test ProcessPopper JohnNo ratings yet
- SANS 182-2 Conductors For Overhead Electrical Transmission Lines. AACDocument16 pagesSANS 182-2 Conductors For Overhead Electrical Transmission Lines. AACLaxmishankar Katiyar100% (1)
- Year 9 Mathematics Term 2 Exam PaperDocument20 pagesYear 9 Mathematics Term 2 Exam PaperAyemyanandar KyiNo ratings yet
- Northern Cebu Colleges, Inc. San Vicente ST., Bogo City, Cebu Flexible Instruction Delivery Plan (FIDP)Document6 pagesNorthern Cebu Colleges, Inc. San Vicente ST., Bogo City, Cebu Flexible Instruction Delivery Plan (FIDP)Jilmore Caseda Cantal100% (1)
- Effect of Oxygen On Surface Tension of Liquid Ag-Sn AlloysDocument5 pagesEffect of Oxygen On Surface Tension of Liquid Ag-Sn AlloysBurak ÖZBAKIRNo ratings yet
- DMGTDocument139 pagesDMGTPatil TanishkNo ratings yet
- ADMN-2-002, Issue 01, Procedure For Personal Hygiene, Employee Facility and HousekeepingDocument4 pagesADMN-2-002, Issue 01, Procedure For Personal Hygiene, Employee Facility and HousekeepingSmsajid WaqasNo ratings yet
- Time Schedule of Subjects International Class Program (Icp) Fmipa Unm Biology Department, Odd Semester, Academic Year 2010/2011Document2 pagesTime Schedule of Subjects International Class Program (Icp) Fmipa Unm Biology Department, Odd Semester, Academic Year 2010/2011El MuertoNo ratings yet
- Awra Amba RJ 300612 EN BDDocument86 pagesAwra Amba RJ 300612 EN BDTop ListorsNo ratings yet
- Fault Detection System of Underground Power Line (1) (1) (AutoRecovered)Document4 pagesFault Detection System of Underground Power Line (1) (1) (AutoRecovered)Surya RtzNo ratings yet
- Do Global Economic and Political Integrations Bring More Harm To The Philippines and The Filipinos or Not? Articulate Your StanceDocument3 pagesDo Global Economic and Political Integrations Bring More Harm To The Philippines and The Filipinos or Not? Articulate Your StancenonononowayNo ratings yet
- E702.3M-18 - Acceptance of Concrete Compressive Strength Test Results According To ACI 318M-14Document6 pagesE702.3M-18 - Acceptance of Concrete Compressive Strength Test Results According To ACI 318M-14Christos Leptokaridis100% (1)
- Wiring DM 1wDocument20 pagesWiring DM 1wAnan NasutionNo ratings yet
- Statistics 1Document149 pagesStatistics 1Zaid AhmedNo ratings yet
- Esia Report: Sustainable Akkar Wind Farm, LebanonDocument738 pagesEsia Report: Sustainable Akkar Wind Farm, LebanonAnderson Martins Dos SantosNo ratings yet