You might also like
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesFrom EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesRating: 5 out of 5 stars5/5 (3)
- ConfidenceDocument15 pagesConfidenceJohn BallestaNo ratings yet
- Afna 4Document10 pagesAfna 4Babad BagusNo ratings yet
- Nama: Dewa Ayu Putu Mayuni Fortuna CS Statistika Tugas 1 NIM: 19211138 Kelas: D IV MPH E/4Document3 pagesNama: Dewa Ayu Putu Mayuni Fortuna CS Statistika Tugas 1 NIM: 19211138 Kelas: D IV MPH E/4mayuni fortunaNo ratings yet
- ISO Metric CoarseDocument1 pageISO Metric CoarsematjazNo ratings yet
- Tugas1 - Gebbriloa Anjeni Sadewa 002Document8 pagesTugas1 - Gebbriloa Anjeni Sadewa 002GabbyNo ratings yet
- Deposit - AlumnosDocument7 pagesDeposit - AlumnosGabriel Inostroza MedinaNo ratings yet
- 06 LawLargeNumbersDocument22 pages06 LawLargeNumbersrasha assafNo ratings yet
- Template First Quarter Fil10!22!23Document22 pagesTemplate First Quarter Fil10!22!23CHERYL IGNACIONo ratings yet
- Faktor-Faktor Kejadian Hipertensi Pada Lansia Di Puskesmas ManggisDocument10 pagesFaktor-Faktor Kejadian Hipertensi Pada Lansia Di Puskesmas ManggisIntan ReskiNo ratings yet
- Sample Size EstimatorDocument8 pagesSample Size EstimatorRiyan MardiyantaNo ratings yet
- 06 LawLargeNumbersDocument22 pages06 LawLargeNumbersrasha assafNo ratings yet
- Table of SpecificationsDocument6 pagesTable of SpecificationsJMXNo ratings yet
- Table of SpecificationsDocument6 pagesTable of SpecificationsJMXNo ratings yet
- 3 3Document3 pages3 3bryan.zabala.mnlNo ratings yet
- 2.PDA Ciasem-Curug AgungDocument14 pages2.PDA Ciasem-Curug AgungigitNo ratings yet
- Chart Title Chart TitleDocument3 pagesChart Title Chart TitleAlex BaldwinNo ratings yet
- Hasil Analisa DataDocument4 pagesHasil Analisa Dataeni gusliNo ratings yet
- Sample Item AnalysisDocument3 pagesSample Item AnalysisFunny Videos of all TimeNo ratings yet
- Tugas p4 Annisa Nur OktaviaDocument2 pagesTugas p4 Annisa Nur Oktaviaaulya adibbaNo ratings yet
- Act1 MidtermDocument1 pageAct1 MidtermMicah joy BalagatNo ratings yet
- Lampiran Efas Dan Ifas: 1. EFAS (External Factors Analysis Strategy)Document3 pagesLampiran Efas Dan Ifas: 1. EFAS (External Factors Analysis Strategy)Heri NugrohoNo ratings yet
- DecisionTree Addhealth 1Document7 pagesDecisionTree Addhealth 1Fajar DNo ratings yet
- Report Generated by Graseed - Ai Test Id: R Date: R Test Variety: R Name: R Organization: R Email: R Comments: RDocument3 pagesReport Generated by Graseed - Ai Test Id: R Date: R Test Variety: R Name: R Organization: R Email: R Comments: RCarey JohnNo ratings yet
- Logistic RegressionDocument12 pagesLogistic RegressionKagade AjinkyaNo ratings yet
- Parametric Test Pearson R November 18 2023Document11 pagesParametric Test Pearson R November 18 2023garciarhodjeannemarthaNo ratings yet
- Inv. TaskDocument5 pagesInv. TaskJiho JunNo ratings yet
- Airline PassengersDocument2 pagesAirline Passengerskrashn007No ratings yet
- Week 14Document46 pagesWeek 14Eid IbrahimNo ratings yet
- BKTK 6.29Document2 pagesBKTK 6.29Putri RahmaNo ratings yet
- BKTK 1Document2 pagesBKTK 1Putri RahmaNo ratings yet
- Speaking Test Grading Sheet: Modulo: Grading Teacher: Exam DateDocument6 pagesSpeaking Test Grading Sheet: Modulo: Grading Teacher: Exam DatePaula ZapataNo ratings yet
- Polestico - Assessment ReportDocument15 pagesPolestico - Assessment ReportIrish PolesticoNo ratings yet
- USIADocument2 pagesUSIAANITA PUJI RAHAYUNo ratings yet
- HW5-Group02 FinalDocument25 pagesHW5-Group02 FinalJanay MosleyNo ratings yet
- USIADocument2 pagesUSIAANITA PUJI RAHAYUNo ratings yet
- USIADocument2 pagesUSIAANITA PUJI RAHAYUNo ratings yet
- Results Descriptives: Droga - A Cortisol Globulina Leucocitos PlaquetasDocument4 pagesResults Descriptives: Droga - A Cortisol Globulina Leucocitos PlaquetasThomás GuerreiroNo ratings yet
- Pre-Test Results Item AnalysisDocument2 pagesPre-Test Results Item AnalysisRonald ArtilleroNo ratings yet
- OutputDocument5 pagesOutputAnother YogaNo ratings yet
- Baliola, Jenny Activity-3Document37 pagesBaliola, Jenny Activity-3Season YamzNo ratings yet
- Grafik 1. M Vs NDocument3 pagesGrafik 1. M Vs NDIKANo ratings yet
- Formato - Múltiple - de - Pago - de - La - Tesorería - VER ANEXODocument3 pagesFormato - Múltiple - de - Pago - de - La - Tesorería - VER ANEXOInternet Nelly 2No ratings yet
- Predicting Customer ChurnDocument285 pagesPredicting Customer ChurnFurqanTariqNo ratings yet
- Frequencies: Frequencies Variables Penjualan Gender /order AnalysisDocument3 pagesFrequencies: Frequencies Variables Penjualan Gender /order AnalysisIghack ToolNo ratings yet
- Stump Socket 1 Stump Socket 2 Stump Socket 3Document3 pagesStump Socket 1 Stump Socket 2 Stump Socket 3Aazam GunnyNo ratings yet
- FrequenciesDocument6 pagesFrequenciesbeni prasetyoFENo ratings yet
- Excel 211Document7 pagesExcel 211Santi barretoNo ratings yet
- Grafica de T Vs (Xa, Ya)Document2 pagesGrafica de T Vs (Xa, Ya)franciscoNo ratings yet
- Website Has Effect Towards Students' Achievements in Fractions? This Question Requires AnalysisDocument4 pagesWebsite Has Effect Towards Students' Achievements in Fractions? This Question Requires Analysistrajes77No ratings yet
- Correlation With Other MeasuresDocument25 pagesCorrelation With Other MeasuresLópez García Ángeles LucíaNo ratings yet
- Libro 1Document17 pagesLibro 1Andres RicoNo ratings yet
- Mata Kuliah Statistik GloriousDocument4 pagesMata Kuliah Statistik Gloriousjatmiko.purwantonoNo ratings yet
- Index of DifficultyDocument15 pagesIndex of DifficultyYanHong100% (1)
- No Kedalaman D Waktu 1 2 3 4 5 6 7 8 Jarak Dari Titik Awal Posisi Alat Ukur Jumlah Putaran Putaran/detik NDocument2 pagesNo Kedalaman D Waktu 1 2 3 4 5 6 7 8 Jarak Dari Titik Awal Posisi Alat Ukur Jumlah Putaran Putaran/detik NAkhmad RezaNo ratings yet
- SpssDocument5 pagesSpssIrwanNo ratings yet
- CH05 AirlinePassengerstxt ExcelDocument4 pagesCH05 AirlinePassengerstxt ExcelJenn AmaroNo ratings yet
- Gestao de BancaDocument27 pagesGestao de BancazwierzykowskiadrianoNo ratings yet
- Statistik IusDocument4 pagesStatistik IusPetrus ChandraNo ratings yet
- Nama: Berat Badan: Sex: Tinggi Badan: Umur: AktivitasDocument4 pagesNama: Berat Badan: Sex: Tinggi Badan: Umur: AktivitasJeumpa SyahranaNo ratings yet
- Hindu Temples Models of A Fractal Universe by Prof - Kriti TrivediDocument7 pagesHindu Temples Models of A Fractal Universe by Prof - Kriti TrivediAr ReshmaNo ratings yet
- 5R55W-S Repair DiagnosisDocument70 pages5R55W-S Repair Diagnosisaxallindo100% (2)
- Geomorphic Evidences of Recent Tectonic Activity in The Forearc, Southern PeruDocument11 pagesGeomorphic Evidences of Recent Tectonic Activity in The Forearc, Southern PeruVayolait BardNo ratings yet
- DC Power Supply and Voltage RegulatorsDocument73 pagesDC Power Supply and Voltage RegulatorsRalph Justine NevadoNo ratings yet
- Database Programming With SQL 12-3: DEFAULT Values, MERGE, and Multi-Table Inserts Practice ActivitiesDocument2 pagesDatabase Programming With SQL 12-3: DEFAULT Values, MERGE, and Multi-Table Inserts Practice ActivitiesFlorin CatalinNo ratings yet
- Degree of ComparisonDocument23 pagesDegree of Comparisonesalisa23No ratings yet
- Oculus SDK OverviewDocument47 pagesOculus SDK OverviewparaqueimaNo ratings yet
- Book Review: Laser Fundamentals, 2nd Edition by William T. SilfvastDocument2 pagesBook Review: Laser Fundamentals, 2nd Edition by William T. SilfvastAbhishekNo ratings yet
- Ug CR RPTSTDDocument1,014 pagesUg CR RPTSTDViji BanuNo ratings yet
- Network Command - HPUXDocument5 pagesNetwork Command - HPUXRashid NihalNo ratings yet
- Data and Specifications: HMR Regulated MotorsDocument21 pagesData and Specifications: HMR Regulated MotorsBeniamin KowollNo ratings yet
- 16620YDocument17 pages16620YbalajivangaruNo ratings yet
- Ny-Damecaax500 Brochure Juli-2019Document8 pagesNy-Damecaax500 Brochure Juli-2019Shavin FernandoNo ratings yet
- Exercise 1 - Revision StringDocument2 pagesExercise 1 - Revision StringKu H6No ratings yet
- Systems - of - EquationsDocument39 pagesSystems - of - EquationsAnonymous 5aPb088W100% (1)
- Fire Dynamic Damper Installation InstructionsDocument18 pagesFire Dynamic Damper Installation InstructionsJohnMerrNo ratings yet
- Technical Data: Series Allclean AcnpDocument1 pageTechnical Data: Series Allclean AcnpBoško IvanovićNo ratings yet
- SM700 E WebDocument4 pagesSM700 E WebrobertwebberNo ratings yet
- Dielectric Properties of SolidsDocument15 pagesDielectric Properties of SolidsMahesh Lohith K.S100% (11)
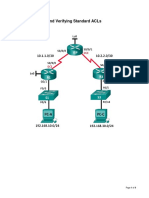
- Lab 3.1 - Configuring and Verifying Standard ACLsDocument9 pagesLab 3.1 - Configuring and Verifying Standard ACLsRas Abel BekeleNo ratings yet
- Test Bank Chapter (4) : Choose The Correct AnswerDocument2 pagesTest Bank Chapter (4) : Choose The Correct AnswerteafNo ratings yet
- Which Is The Best Solid Modelling - Dhyan AcademyDocument3 pagesWhich Is The Best Solid Modelling - Dhyan Academydhyanacademy engineersNo ratings yet
- A Tutorial On Spectral Sound Processing Using Max/MSP and JitterDocument16 pagesA Tutorial On Spectral Sound Processing Using Max/MSP and Jittertramazio0% (1)
- Product Specifications: Handheld Termination AidDocument1 pageProduct Specifications: Handheld Termination AidnormNo ratings yet
- X-Plane Mobile ManualDocument66 pagesX-Plane Mobile ManualRafael MunizNo ratings yet
- How Convert A Document PDF To JpegDocument1 pageHow Convert A Document PDF To Jpegblasssm7No ratings yet
- Same Virtus: Alarm ListDocument23 pagesSame Virtus: Alarm ListLacatusu Mircea100% (1)
- WEEK 1, Grade 10Document2 pagesWEEK 1, Grade 10Sheela BatterywalaNo ratings yet
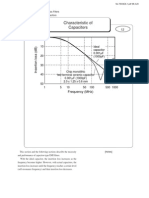
- Murata Data Caps ESR ESLDocument6 pagesMurata Data Caps ESR ESLecl_manNo ratings yet
- Disc Brake System ReportDocument20 pagesDisc Brake System ReportGovindaram Rajesh100% (1)
- TEF Canada Expression Écrite : 150 Topics To SucceedFrom EverandTEF Canada Expression Écrite : 150 Topics To SucceedRating: 4.5 out of 5 stars4.5/5 (17)
- 1,001 Questions & Answers for the CWI Exam: Welding Metallurgy and Visual Inspection Study GuideFrom Everand1,001 Questions & Answers for the CWI Exam: Welding Metallurgy and Visual Inspection Study GuideRating: 3.5 out of 5 stars3.5/5 (7)
- Make It Stick by Peter C. Brown, Henry L. Roediger III, Mark A. McDaniel - Book Summary: The Science of Successful LearningFrom EverandMake It Stick by Peter C. Brown, Henry L. Roediger III, Mark A. McDaniel - Book Summary: The Science of Successful LearningRating: 4.5 out of 5 stars4.5/5 (55)
- ATI TEAS Study Guide: The Most Comprehensive and Up-to-Date Manual to Ace the Nursing Exam on Your First Try with Key Practice Questions, In-Depth Reviews, and Effective Test-Taking StrategiesFrom EverandATI TEAS Study Guide: The Most Comprehensive and Up-to-Date Manual to Ace the Nursing Exam on Your First Try with Key Practice Questions, In-Depth Reviews, and Effective Test-Taking StrategiesNo ratings yet
- IELTS Speaking Vocabulary Builder (Band 5-6): Master Phrases and Expressions for the IELTS Speaking ExamFrom EverandIELTS Speaking Vocabulary Builder (Band 5-6): Master Phrases and Expressions for the IELTS Speaking ExamRating: 5 out of 5 stars5/5 (1)
- Straight-A Study Skills: More Than 200 Essential Strategies to Ace Your Exams, Boost Your Grades, and Achieve Lasting Academic SuccessFrom EverandStraight-A Study Skills: More Than 200 Essential Strategies to Ace Your Exams, Boost Your Grades, and Achieve Lasting Academic SuccessRating: 3.5 out of 5 stars3.5/5 (6)
- RBT Registered Behavior Technician Exam Audio Crash Course Study Guide to Practice Test Question With Answers and Master the ExamFrom EverandRBT Registered Behavior Technician Exam Audio Crash Course Study Guide to Practice Test Question With Answers and Master the ExamNo ratings yet
- 700 Driving Theory Test Questions & Answers: Updated Study Guide With Over 700 Official Style Practise Questions For Cars - Based Off the Highway CodeFrom Everand700 Driving Theory Test Questions & Answers: Updated Study Guide With Over 700 Official Style Practise Questions For Cars - Based Off the Highway CodeNo ratings yet
- The Everything Guide to Study Skills: Strategies, tips, and tools you need to succeed in school!From EverandThe Everything Guide to Study Skills: Strategies, tips, and tools you need to succeed in school!Rating: 4.5 out of 5 stars4.5/5 (6)
- 71 Ways to Practice English Reading: Tips for ESL/EFL LearnersFrom Everand71 Ways to Practice English Reading: Tips for ESL/EFL LearnersRating: 5 out of 5 stars5/5 (2)
- Practice Makes Perfect Mastering GrammarFrom EverandPractice Makes Perfect Mastering GrammarRating: 5 out of 5 stars5/5 (21)
- Concept Based Practice Questions for AWS Solutions Architect Certification Latest Edition 2023From EverandConcept Based Practice Questions for AWS Solutions Architect Certification Latest Edition 2023No ratings yet
- Learning Outside The Lines: Two Ivy League Students With Learning Disabilities And Adhd Give You The Tools For Academic Success and Educational RevolutionFrom EverandLearning Outside The Lines: Two Ivy League Students With Learning Disabilities And Adhd Give You The Tools For Academic Success and Educational RevolutionRating: 4 out of 5 stars4/5 (19)
- LMSW Passing Score: Your Comprehensive Guide to the ASWB Social Work Licensing ExamFrom EverandLMSW Passing Score: Your Comprehensive Guide to the ASWB Social Work Licensing ExamRating: 5 out of 5 stars5/5 (1)
- Learning Outside The Lines: Two Ivy League Students with Learning Disabilities and ADHD Give You the Tools for Academic Success and Educational RevolutionFrom EverandLearning Outside The Lines: Two Ivy League Students with Learning Disabilities and ADHD Give You the Tools for Academic Success and Educational RevolutionRating: 4 out of 5 stars4/5 (17)