You might also like
- Hardening Oracle Linux ServerDocument4 pagesHardening Oracle Linux ServerTran HieuNo ratings yet
- SREye - Fisheye Image Dewarping Module For NVR and Viewer PDFDocument16 pagesSREye - Fisheye Image Dewarping Module For NVR and Viewer PDFyshim_4No ratings yet
- Nat Reviewer Set B - Math 10Document2 pagesNat Reviewer Set B - Math 10Jo Mai Hann90% (10)
- 1 s2.0 S026322412200673X MainDocument11 pages1 s2.0 S026322412200673X MainAlexan Anca RoxanaNo ratings yet
- Robusthuman 2017Document22 pagesRobusthuman 2017sushanprazNo ratings yet
- Vmdjoo2016 Reload XltsDocument6 pagesVmdjoo2016 Reload XltsvictormocioiuNo ratings yet
- Human Activity Recognition With SmartphoneDocument8 pagesHuman Activity Recognition With SmartphoneIJRASETPublicationsNo ratings yet
- Journal Pre-Proofs: MeasurementDocument28 pagesJournal Pre-Proofs: MeasurementG.R.Mahendrababau AP - ECE departmentNo ratings yet
- Sensors: Cloud-Based Behavioral Monitoring in Smart HomesDocument16 pagesSensors: Cloud-Based Behavioral Monitoring in Smart HomestubdownloadNo ratings yet
- Classifying Human Activity from On-Body AccelerometersDocument18 pagesClassifying Human Activity from On-Body AccelerometersElvis HuvNo ratings yet
- Research Paper 1Document5 pagesResearch Paper 1Prem BorseNo ratings yet
- Recognizing User Context Using MobileDocument5 pagesRecognizing User Context Using MobileAshwin Kishor BangarNo ratings yet
- Human Activity Recognition SynopsisDocument4 pagesHuman Activity Recognition SynopsisAPS PlacementsNo ratings yet
- Sensors: New Sensor Data Structuring For Deeper Feature Extraction in Human Activity RecognitionDocument26 pagesSensors: New Sensor Data Structuring For Deeper Feature Extraction in Human Activity RecognitionkirubhaNo ratings yet
- Wearable Sensor Data Based Human Activity Recognition Using Machine Learning A New ApproachDocument6 pagesWearable Sensor Data Based Human Activity Recognition Using Machine Learning A New ApproachK. AndriantoNo ratings yet
- ReportDocument27 pagesReportgamer GamesloverNo ratings yet
- Real Time Human Activity Recognition On Smartphones Using LSTM NetworksDocument6 pagesReal Time Human Activity Recognition On Smartphones Using LSTM NetworksAditi DoraNo ratings yet
- Real-Time Human Activity Recognition From Smart Phone Using Linear Support Vector MachinesDocument10 pagesReal-Time Human Activity Recognition From Smart Phone Using Linear Support Vector MachinesTELKOMNIKANo ratings yet
- Scalable Daily Human Behavioral Pattern Mining From Multivariate Temporal DataDocument15 pagesScalable Daily Human Behavioral Pattern Mining From Multivariate Temporal DataBala ChowdappaNo ratings yet
- Human Activity Recognition Using Smart PhoneDocument8 pagesHuman Activity Recognition Using Smart PhoneNarendra Vetalkar100% (1)
- Ullah 2019Document6 pagesUllah 2019Dinar TASNo ratings yet
- Accurate Indoor Positioning Using Learning Prediction SensorsDocument27 pagesAccurate Indoor Positioning Using Learning Prediction Sensorsvalerio modugnoNo ratings yet
- Advanced Patient or Elder Fall Detection Based On Movement and Sound DataDocument5 pagesAdvanced Patient or Elder Fall Detection Based On Movement and Sound DataHitesh ವಿಟ್ಟಲ್ ShettyNo ratings yet
- Research Article Lora-Based Smart Iot Application For Smart City: An Example of Human Posture DetectionDocument15 pagesResearch Article Lora-Based Smart Iot Application For Smart City: An Example of Human Posture DetectionSatnam SinghNo ratings yet
- Alotaibi 2020Document12 pagesAlotaibi 2020Santhana KrishnanNo ratings yet
- Project Seminar Report-97,99Document19 pagesProject Seminar Report-97,99Jaswanth NathNo ratings yet
- Human Activity Recognition Using Machine LearningDocument8 pagesHuman Activity Recognition Using Machine LearningIJRASETPublicationsNo ratings yet
- Embedded Systems App Areas: Wearables, Healthcare, Sensing, RecognitionDocument8 pagesEmbedded Systems App Areas: Wearables, Healthcare, Sensing, RecognitionSurr LaLaNo ratings yet
- CNNs Improve Activity Recognition with Mobile SensorsDocument18 pagesCNNs Improve Activity Recognition with Mobile SensorsAlan BensonNo ratings yet
- Activity Recognition System For Smart CampusDocument9 pagesActivity Recognition System For Smart CampusIJRASETPublicationsNo ratings yet
- Model Human Activity From Smartphone Accelerometer DataDocument38 pagesModel Human Activity From Smartphone Accelerometer DataWaqas HameedNo ratings yet
- A Novel Semisupervised Deep Learning Method For Human Activity Recognition PDFDocument10 pagesA Novel Semisupervised Deep Learning Method For Human Activity Recognition PDFaqibmumtazNo ratings yet
- Vision Based Anomalous Human Behaviour Detection Using CNN and Transfer LearningDocument6 pagesVision Based Anomalous Human Behaviour Detection Using CNN and Transfer LearningIJRASETPublicationsNo ratings yet
- SynopsisDocument14 pagesSynopsisYash VermaNo ratings yet
- Lightweight Motion-Capture for Clinical Gait AnalysisDocument7 pagesLightweight Motion-Capture for Clinical Gait Analysismookow410No ratings yet
- SM3315Document19 pagesSM3315Riky Tri YunardiNo ratings yet
- Human Activity Recognition Based On Time Series Analysis Using U-NetDocument21 pagesHuman Activity Recognition Based On Time Series Analysis Using U-NetEzequiel França Dos SantosNo ratings yet
- Human Tracking SystemDocument13 pagesHuman Tracking SystemtechmindzNo ratings yet
- 3D Human Gait Reconstruction and Monitoring Using Body-Worn Inertial Sensors and Kinematic ModelingDocument9 pages3D Human Gait Reconstruction and Monitoring Using Body-Worn Inertial Sensors and Kinematic ModelingCristian HoyNo ratings yet
- A Study On Human Activity Recognition Using Accelerometer Data From SmartphonesDocument8 pagesA Study On Human Activity Recognition Using Accelerometer Data From SmartphonesMartin AlcarazNo ratings yet
- Smartphone Sensor Accuracy Varies From Device To DDocument12 pagesSmartphone Sensor Accuracy Varies From Device To DyovNo ratings yet
- Sensors: Human Physical Activity Recognition Using Smartphone SensorsDocument18 pagesSensors: Human Physical Activity Recognition Using Smartphone SensorsrahulNo ratings yet
- Wearable API for mHealth DevelopmentDocument26 pagesWearable API for mHealth DevelopmentNursyifa AzizahNo ratings yet
- A Study of Accelerometer and Gyroscope PDFDocument22 pagesA Study of Accelerometer and Gyroscope PDFHenrique OliveiraNo ratings yet
- Human Activity Recognition Using Inertial Physiological and Environmental Sensors A Comprehensive SurveyDocument21 pagesHuman Activity Recognition Using Inertial Physiological and Environmental Sensors A Comprehensive SurveyducksgomooNo ratings yet
- Human Activity Recognition Using Machine LearningDocument10 pagesHuman Activity Recognition Using Machine LearningSita Putra TejaNo ratings yet
- Graph Neural Network for Smartphone Sensor-based Human Activity RecognitionDocument8 pagesGraph Neural Network for Smartphone Sensor-based Human Activity RecognitionΓιάννης ΜανουσαρίδηςNo ratings yet
- Adaptive Real Time Data Mining Methodology For Wireless Body Area Network Based Healthcare ApplicationsDocument12 pagesAdaptive Real Time Data Mining Methodology For Wireless Body Area Network Based Healthcare ApplicationsAnonymous IlrQK9HuNo ratings yet
- Identification of Spatio-Temporal and Kinematics Parameters For 2-D Optical Gait Analysis System Using Passive MarkersDocument7 pagesIdentification of Spatio-Temporal and Kinematics Parameters For 2-D Optical Gait Analysis System Using Passive MarkerssanahujalidiaNo ratings yet
- Expert Systems With Applications: ReviewDocument29 pagesExpert Systems With Applications: ReviewmemoNo ratings yet
- Libby Peak DetectionDocument16 pagesLibby Peak DetectionwisesoarNo ratings yet
- A Study To Find Facts Behind Preprocessing On Deep Learning AlgorithmsDocument11 pagesA Study To Find Facts Behind Preprocessing On Deep Learning AlgorithmsEsclet PHNo ratings yet
- 陌陌陌陌莫迪Document9 pages陌陌陌陌莫迪363331272No ratings yet
- Jocm (E)Document9 pagesJocm (E)Nguyễn Văn VũNo ratings yet
- Human Activity Recognition Using Machine Learning: Presented byDocument11 pagesHuman Activity Recognition Using Machine Learning: Presented byJoshua Prudhvi RajNo ratings yet
- Unit 4 - Internet of Things - WWW - Rgpvnotes.in PDFDocument12 pagesUnit 4 - Internet of Things - WWW - Rgpvnotes.in PDFVinutha MNo ratings yet
- [5] Webber, M., & Rojas, R. F. (2021). Human Activity Recognition With Accelerometer and Gyroscope a Data Fusion Approach. IEEE Sensors Journal, 21(15), 16979–16989. Httpsdoi.org10.1109jsen.2021.3079883Document13 pages[5] Webber, M., & Rojas, R. F. (2021). Human Activity Recognition With Accelerometer and Gyroscope a Data Fusion Approach. IEEE Sensors Journal, 21(15), 16979–16989. Httpsdoi.org10.1109jsen.2021.3079883Thanh HùngNo ratings yet
- Data Transmission in Wearable Sensor Network For Human Activity Monitoring Using Embedded Classifier TechniqueDocument10 pagesData Transmission in Wearable Sensor Network For Human Activity Monitoring Using Embedded Classifier TechniqueIJRASETPublicationsNo ratings yet
- Exploratory Data Analysis of Acceleration Signals To Select Light-Weight and Accurate Features For Real-Time Activity Recognition On SmartphonesDocument25 pagesExploratory Data Analysis of Acceleration Signals To Select Light-Weight and Accurate Features For Real-Time Activity Recognition On SmartphonesMo SaNo ratings yet
- Divya Phase 2 ReportDocument51 pagesDivya Phase 2 ReportMost WantedNo ratings yet
- Human Activity Recognition Method Using Joint Deep Learning and Acceleration SignalDocument9 pagesHuman Activity Recognition Method Using Joint Deep Learning and Acceleration SignalIAES IJAINo ratings yet
- Bascom Avr Demonstration BoardDocument8 pagesBascom Avr Demonstration BoardNitish KumarNo ratings yet
- Logic 3Document33 pagesLogic 3Kim Abigelle GarciaNo ratings yet
- FOG HORN Suppressors and Shooting AngleDocument2 pagesFOG HORN Suppressors and Shooting AngleTwobirds Flying PublicationsNo ratings yet
- Unirub Techno India PVT 7Document7 pagesUnirub Techno India PVT 7BalajiYachawadNo ratings yet
- FPGA Based Implementation of Symmetrical Switching in SVPWM For Three Level NPC ConverterDocument6 pagesFPGA Based Implementation of Symmetrical Switching in SVPWM For Three Level NPC ConvertersateeshNo ratings yet
- CB1 - Key Concepts in Biology (Paper 1 and 2)Document2 pagesCB1 - Key Concepts in Biology (Paper 1 and 2)Alhaji SowNo ratings yet
- Advances in Methods and Applications of Quantum Systems in Chemistry, Physics, and BiologyDocument361 pagesAdvances in Methods and Applications of Quantum Systems in Chemistry, Physics, and BiologyVan De BeerNo ratings yet
- ISI Students' Brochure Details B.Stat. (Hons.) CurriculumDocument45 pagesISI Students' Brochure Details B.Stat. (Hons.) CurriculumDr. Mousumi BoralNo ratings yet
- RPM 00342Document3 pagesRPM 00342Iswahyudi AprilyastonoNo ratings yet
- Sizechange Calculator V 0.6Document1 pageSizechange Calculator V 0.6Arthur Dutra ReccoNo ratings yet
- E11+WR1 OHL Andoolo 2 Test ReportDocument31 pagesE11+WR1 OHL Andoolo 2 Test ReportMuhammad Adrianto LubisNo ratings yet
- NORSOK BULK SYSTEM STANDARDDocument3 pagesNORSOK BULK SYSTEM STANDARDnurwinanto01No ratings yet
- Equations Needed Full Answers and Working Redox Reaction Theory Qualitative AnalysisDocument13 pagesEquations Needed Full Answers and Working Redox Reaction Theory Qualitative AnalysisEmmaNo ratings yet
- Confined Space Safety GuideDocument6 pagesConfined Space Safety GuiderigelNo ratings yet
- Class Exercise Simpleregression Ceo-SalaryDocument1 pageClass Exercise Simpleregression Ceo-Salaryсимона златковаNo ratings yet
- PVF Pvaf CVF Cvaf Tables For Financial ManagementDocument11 pagesPVF Pvaf CVF Cvaf Tables For Financial Managementvikas25% (4)
- Short Questions... DbmsDocument10 pagesShort Questions... DbmsMuhammad Jamal ShahNo ratings yet
- Ieee 1471-2000Document28 pagesIeee 1471-2000Suzanne StewartNo ratings yet
- 7805T Ecg-960Document2 pages7805T Ecg-960bellscbNo ratings yet
- Electric Field Mapping: Experiment 1Document5 pagesElectric Field Mapping: Experiment 1Pi PoliNo ratings yet
- MRI ScriptDocument1 pageMRI ScriptPeter BolocelliNo ratings yet
- Factors That Determine Reaction SpontaneityDocument5 pagesFactors That Determine Reaction SpontaneityDavid PetalcurinNo ratings yet
- Igcse Chemistry Section 5 Lesson 1Document62 pagesIgcse Chemistry Section 5 Lesson 1XX OniiSan XXNo ratings yet
- PLC SCADA Based Temperature Control SystemDocument5 pagesPLC SCADA Based Temperature Control SystemSaurav TiwariNo ratings yet
- RRB Clerk Prelims Day - 13 e (1) 168804293277Document27 pagesRRB Clerk Prelims Day - 13 e (1) 168804293277sahilNo ratings yet
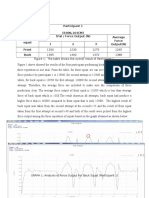
- Result: Participant 1 (630N, 164CM) Type of Squat Trial / Force Output (N) Average Force Output (N) 1 2 3 Front BackDocument5 pagesResult: Participant 1 (630N, 164CM) Type of Squat Trial / Force Output (N) Average Force Output (N) 1 2 3 Front BackpatenggNo ratings yet
- MCQ Questions For Class 10 Science Electricity With Answers: Run Windows On MacDocument3 pagesMCQ Questions For Class 10 Science Electricity With Answers: Run Windows On Macshashank srivastavaNo ratings yet
























































![[5] Webber, M., & Rojas, R. F. (2021). Human Activity Recognition With Accelerometer and Gyroscope a Data Fusion Approach. IEEE Sensors Journal, 21(15), 16979–16989. Httpsdoi.org10.1109jsen.2021.3079883](https://imgv2-2-f.scribdassets.com/img/document/723642252/149x198/d3ac625cbb/1713285612?v=1)