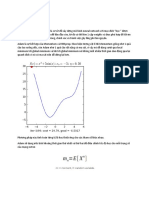
You might also like
- Chương 5 - Gradient DescentDocument16 pagesChương 5 - Gradient DescentNgọcNo ratings yet
- AdamDocument3 pagesAdamPhan Thị Diễm ThuýNo ratings yet
- Lập trình Gradient Descent, thuật toán tối ưu cốt lõi trong Machine learning bằng PythonDocument1 pageLập trình Gradient Descent, thuật toán tối ưu cốt lõi trong Machine learning bằng PythonThiên lNo ratings yet
- NguyenVanHoang 19110209 Tuan10 LythuyetDocument3 pagesNguyenVanHoang 19110209 Tuan10 LythuyetNguyễn HoàngNo ratings yet
- Dlbook Chap04Document19 pagesDlbook Chap04thuyanhnguyen164.workNo ratings yet
- Có Hai Cách Phổ Biến Phân Nhóm Các Thuật Toán Machine LearningDocument40 pagesCó Hai Cách Phổ Biến Phân Nhóm Các Thuật Toán Machine LearningTri PhanNo ratings yet
- MLP302x Regression 2Document10 pagesMLP302x Regression 2đức ngọc trầnNo ratings yet
- NguyenVanHoang 19110209 Tuan07 LythuyetDocument3 pagesNguyenVanHoang 19110209 Tuan07 LythuyetNguyễn HoàngNo ratings yet
- OverfittingDocument6 pagesOverfittinggreensummerprojectNo ratings yet
- Tìm Min, MaxDocument27 pagesTìm Min, Maxkhanhhotboy2910No ratings yet
- Hoi Quy Tuyen TinhDocument9 pagesHoi Quy Tuyen TinhDuyên NguyễnNo ratings yet
- BÀI THUYẾT TRÌNH XE TỰ HÀNH - lINEAR REGRESSION - CƠ ĐIỆN TỬ 01Document19 pagesBÀI THUYẾT TRÌNH XE TỰ HÀNH - lINEAR REGRESSION - CƠ ĐIỆN TỬ 01Lê Huỳnh Hải ĐăngNo ratings yet
- Tài liệu 3Document12 pagesTài liệu 3duy đạt phạmNo ratings yet
- Chương 1-Ham Co BanDocument52 pagesChương 1-Ham Co BanLinh Tống HoàiNo ratings yet
- Signal and SystemDocument9 pagesSignal and Systemvodinhdai379No ratings yet
- Tai Lieu PICDocument69 pagesTai Lieu PICPham Ba ToanNo ratings yet
- Machine LearningDocument9 pagesMachine LearningPhong DangNo ratings yet
- HJGTLDocument7 pagesHJGTLNguyễn PhongNo ratings yet
- New 1Document1 pageNew 1diemhuongnt.vlNo ratings yet
- HOWKTEAM.VN - Thuật toán Gradient Descent cho Linear RegressionDocument10 pagesHOWKTEAM.VN - Thuật toán Gradient Descent cho Linear RegressionTrung Võ Lê MinhNo ratings yet
- Sơ lược Ưu nhược điểm Ứng dụngDocument7 pagesSơ lược Ưu nhược điểm Ứng dụngvuongquocviet21No ratings yet
- Chương 4Document47 pagesChương 4Phạm Xuân TrungNo ratings yet
- CannyDocument18 pagesCannyWolf InvisibleNo ratings yet
- Xla MatlabDocument20 pagesXla MatlabMinh Thành NguyễnNo ratings yet
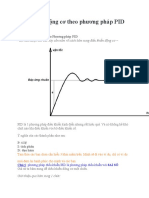
- Điều khiển động cơ theo phương pháp PIDDocument5 pagesĐiều khiển động cơ theo phương pháp PIDNguyễn Phươn NTPNo ratings yet
- Arithmetic OperationsDocument2 pagesArithmetic Operationskhanhnpse181959No ratings yet
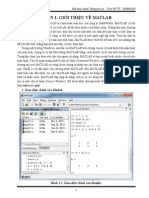
- Buổi 1 - Giới thiệu MatlabDocument12 pagesBuổi 1 - Giới thiệu MatlabNguyễn Văn KhoaNo ratings yet
- Chapter 2.2 OverfittingDocument23 pagesChapter 2.2 Overfittingha quanNo ratings yet
- dọc thử CDocument6 pagesdọc thử CVũ Phương NgânNo ratings yet
- File Báo CáoDocument8 pagesFile Báo Cáoado30025061No ratings yet
- Phương pháp lặpDocument13 pagesPhương pháp lặpNgoTienSy100% (1)
- NguyenVanHoang 19110209 Tuan08 LythuyetDocument4 pagesNguyenVanHoang 19110209 Tuan08 LythuyetNguyễn HoàngNo ratings yet
- Bài 7: Gradient Descent (phần 1/2) : 1. Giới thiệuDocument13 pagesBài 7: Gradient Descent (phần 1/2) : 1. Giới thiệuphanthikieuvy0612No ratings yet
- Machine LearningDocument29 pagesMachine LearningNguyễn HoàngNo ratings yet
- HOWKTEAM - VN - Normal Equation Cho Linear RegressionDocument4 pagesHOWKTEAM - VN - Normal Equation Cho Linear Regressionlamdhhe180848No ratings yet
- Thuyet TrinhDocument3 pagesThuyet TrinhTrương Văn KhảiNo ratings yet
- Hiện tượng đa cộng tuyếnDocument4 pagesHiện tượng đa cộng tuyếnTuan Nguyen NgocNo ratings yet
- Symbolic Trong MatlabDocument2 pagesSymbolic Trong Matlab月野姮娥No ratings yet
- Dlbook Chap02Document22 pagesDlbook Chap02thuyanhnguyen164.workNo ratings yet
- Xe Dò LineDocument2 pagesXe Dò LineTrí Chốt100% (1)
- Bai Tap 4Document6 pagesBai Tap 4Vũ Minh Hiếu - B19DCCN262No ratings yet
- G I Ý PTIT Round 6Document3 pagesG I Ý PTIT Round 6Bùi KiênNo ratings yet
- Bu I 3Document11 pagesBu I 3HuyenVoNo ratings yet
- How To Use Iterative ImputationDocument3 pagesHow To Use Iterative ImputationVĩnh HưngNo ratings yet
- Tổng hợp các phương pháp giải toán trên máy tính CasioDocument13 pagesTổng hợp các phương pháp giải toán trên máy tính CasioChickencn NguyenNo ratings yet
- Chuong 2Document50 pagesChuong 2Hiếu Nguyễn MinhNo ratings yet
- tóm tắt phần 4Document8 pagestóm tắt phần 4hien09694No ratings yet
- Chapter 5.1-Logistic RegressionDocument18 pagesChapter 5.1-Logistic Regressionha quanNo ratings yet
- Solution 13/11: Bài 1. XorsecondDocument5 pagesSolution 13/11: Bài 1. XorsecondtrangtrangvndangiuNo ratings yet
- Chuong 2Document161 pagesChuong 2nguyen vipNo ratings yet
- HCMUS-Toán NG D NG-Đ Án 2Document22 pagesHCMUS-Toán NG D NG-Đ Án 2flj2056No ratings yet
- Chương 1:: A. Discrete (R I R C) B. Cardinal C. Ordinal D. NominalDocument101 pagesChương 1:: A. Discrete (R I R C) B. Cardinal C. Ordinal D. NominalQuỳnh HuỳnhNo ratings yet
- Gioi Thieu Cac HamDocument46 pagesGioi Thieu Cac HamsacpjntimNo ratings yet