You might also like
- Programming Logic and Design, 9th Edition. Chapter 1Document19 pagesProgramming Logic and Design, 9th Edition. Chapter 1John0% (3)
- Programming Paradigms CSI2120: Jochen Lang EECS, University of Ottawa CanadaDocument24 pagesProgramming Paradigms CSI2120: Jochen Lang EECS, University of Ottawa Canadaaziz spamNo ratings yet
- NLP Using PythonDocument12 pagesNLP Using PythonAshish Gupta100% (3)
- TransCoder - YDATA SeminarDocument32 pagesTransCoder - YDATA SeminarChuy MoralesNo ratings yet
- Good Programming Practices: Andrew Showers, Salles Viana AlacDocument38 pagesGood Programming Practices: Andrew Showers, Salles Viana Alacmaham sabirNo ratings yet
- Word Embeddings ClassificationDocument52 pagesWord Embeddings ClassificationOuriNo ratings yet
- AI4youngster - 6 - Topic NLPDocument66 pagesAI4youngster - 6 - Topic NLPChi Le MinhNo ratings yet
- An Introduction To Dynamic Analysis For R.E. (2020) PDFDocument30 pagesAn Introduction To Dynamic Analysis For R.E. (2020) PDFJustin PierceNo ratings yet
- Compiler Construction - CS606 Power Point Slides Lecture 01Document20 pagesCompiler Construction - CS606 Power Point Slides Lecture 01Mashavia100% (1)
- Generative AI RoadmapDocument36 pagesGenerative AI RoadmapRushi KhandareNo ratings yet
- Data Science Master Program SyllabusDocument28 pagesData Science Master Program Syllabussai ramNo ratings yet
- Mod - 1-Programming ConceptsDocument34 pagesMod - 1-Programming ConceptsSeanPharrell18 OfficialNo ratings yet
- C U1 NotesDocument163 pagesC U1 NotesthisisthefirstmegaNo ratings yet
- Mod 1 Programming ConceptsDocument34 pagesMod 1 Programming Conceptsjerome grajalesNo ratings yet
- Mod - 1 Programming ConceptsDocument34 pagesMod - 1 Programming ConceptsmargelynmijaresNo ratings yet
- Large Language ModelDocument38 pagesLarge Language Model21020641No ratings yet
- ds2 3 MapreduceDocument41 pagesds2 3 MapreduceKristóf KássaNo ratings yet
- 3 Sequence and Language ModelingDocument56 pages3 Sequence and Language ModelingOuriNo ratings yet
- Lecture 1: Briefing & C IntroDocument54 pagesLecture 1: Briefing & C IntroSandbox Creator INDNo ratings yet
- PPS Lab File With SolutionDocument70 pagesPPS Lab File With SolutionSomesh ShuklaNo ratings yet
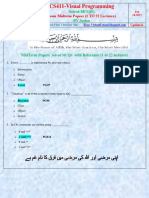
- CS411MidTermMCQsWithReferenceSolvedByArslan PDFDocument65 pagesCS411MidTermMCQsWithReferenceSolvedByArslan PDFMuhammad Usman100% (1)
- CW Sequence AnalysisDocument9 pagesCW Sequence Analysisshk93359No ratings yet
- Compiler Design Lab ManualDocument55 pagesCompiler Design Lab ManualvishnuNo ratings yet
- 01 PythonIntroDocument46 pages01 PythonIntroyavuzselimtazegul2005No ratings yet
- Long Answers PPLDocument19 pagesLong Answers PPLVishnu ReddyNo ratings yet
- Programming Languages, Technologies and ParadigmsDocument66 pagesProgramming Languages, Technologies and ParadigmsEric TBNo ratings yet
- Compiler Design Lab ManualDocument39 pagesCompiler Design Lab ManualSri Prince PriyatharsanNo ratings yet
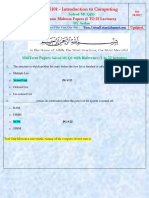
- CS101-MidTerm MCQs With Reference Solved by ArslanDocument39 pagesCS101-MidTerm MCQs With Reference Solved by Arslanifrah100% (4)
- EmbeddedSWEConcepts PDFDocument4 pagesEmbeddedSWEConcepts PDFhiwarkarvinayNo ratings yet
- Module 1.1 PDFDocument28 pagesModule 1.1 PDFAbhishek KumarNo ratings yet
- Infiltrate Ghidra SlidesDocument105 pagesInfiltrate Ghidra SlidesAnonymous xWybHZ3U100% (3)
- SynthesisDocument98 pagesSynthesisROBI PAUL100% (1)
- Community Session - PromptEngineering-Fine-TuningDocument34 pagesCommunity Session - PromptEngineering-Fine-TuningSani KamalNo ratings yet
- Coding Basics 2Document79 pagesCoding Basics 2selsabilhaddab2004No ratings yet
- CS101-FinalTerm MCQs With Reference Solved by Arslan PDFDocument77 pagesCS101-FinalTerm MCQs With Reference Solved by Arslan PDFShahzaib Mugal100% (4)
- Move Aside Script Kiddies: Malware Execution in The Age of Advanced DefensesDocument38 pagesMove Aside Script Kiddies: Malware Execution in The Age of Advanced DefensesWane StayblurNo ratings yet
- Cs Project Grade Xi - Akhil CHDocument50 pagesCs Project Grade Xi - Akhil CHakhilnz06No ratings yet
- Lecture 4 - Source Code AnalysisDocument52 pagesLecture 4 - Source Code Analysisberlin.asd123No ratings yet
- CD - CH6 - Introduction To Code OptimizationDocument19 pagesCD - CH6 - Introduction To Code OptimizationmengistuNo ratings yet
- GPBB 2Document9 pagesGPBB 2Hassaan RanaNo ratings yet
- How To PWN Binaries and Hijack Systems: by Shawn Stone Cybersecurity Club at FSUDocument33 pagesHow To PWN Binaries and Hijack Systems: by Shawn Stone Cybersecurity Club at FSUMohamed RmiliNo ratings yet
- Unit-4-5Document36 pagesUnit-4-5Jefferson AaronNo ratings yet
- 24 02 18 Rejender PratapDocument95 pages24 02 18 Rejender PratapSiam HasanNo ratings yet
- GRP 117 Review 1 ChatbotDocument28 pagesGRP 117 Review 1 ChatbotSahilNo ratings yet
- 01 Introduction Annotated - PPTX 1Document63 pages01 Introduction Annotated - PPTX 1rikewon446No ratings yet
- E6998-3: Advanced Topics in Programming Languages and CompilersDocument61 pagesE6998-3: Advanced Topics in Programming Languages and CompilersVishnu GoudarNo ratings yet
- Compiler in 7 HoursDocument318 pagesCompiler in 7 HoursgitanjaliNo ratings yet
- Create A ChatGPT-Based App To Control Inventor With Natural LanguageDocument10 pagesCreate A ChatGPT-Based App To Control Inventor With Natural Languagew5mmdx5zr6No ratings yet
- Code Reviews - Best Practices: Gerhard Brandt (University of Heidelberg)Document25 pagesCode Reviews - Best Practices: Gerhard Brandt (University of Heidelberg)amit.srimalNo ratings yet
- CS101 Solved File For Final Term MCQS 1 To 45 LecturesDocument130 pagesCS101 Solved File For Final Term MCQS 1 To 45 LecturesHisan Mehmood64% (28)
- Algorithm and Pseudo CodesDocument44 pagesAlgorithm and Pseudo CodesLady GatlabayanNo ratings yet
- L1. Basic Programming ConceptsDocument66 pagesL1. Basic Programming Conceptsfiadhasan102No ratings yet
- By: Assoc. Prof. Dr. Mohd Shafiek YaacobDocument11 pagesBy: Assoc. Prof. Dr. Mohd Shafiek YaacobMohamed JamaNo ratings yet
- IE PythonDocument26 pagesIE PythonMaulana HasanNo ratings yet
- Compiler 3Document35 pagesCompiler 3Tayyab FiazNo ratings yet
- Compiler Design Lab ManualDocument112 pagesCompiler Design Lab Manualrandy andyNo ratings yet
- Data Engineering NotesDocument11 pagesData Engineering NotesVijay KumarNo ratings yet
- TensorFlow All-AroundDocument132 pagesTensorFlow All-AroundVenkatNo ratings yet
- DAA - BasicsDocument74 pagesDAA - BasicsVishnu Damuloori 22238587131No ratings yet
- Code Lagos Week 1Document57 pagesCode Lagos Week 1Chukwudi Eyeiwunmi ObiriNo ratings yet
- WSDM 1 31 15Document108 pagesWSDM 1 31 15rashed44No ratings yet
- AI Assignment: Asad Nasir - 37 Muhammad Usman Ali - 29 Momin - 49Document7 pagesAI Assignment: Asad Nasir - 37 Muhammad Usman Ali - 29 Momin - 49Crack TunesNo ratings yet
- Sanskrit and Computational LinguisticsDocument12 pagesSanskrit and Computational LinguisticsTantra Path100% (1)
- Semisupervised Data Driven Word Sense... (Pratibha Rani and Others)Document11 pagesSemisupervised Data Driven Word Sense... (Pratibha Rani and Others)arpitNo ratings yet
- CoSc581 NLP Topic 5-Text Summarization PDFDocument25 pagesCoSc581 NLP Topic 5-Text Summarization PDFAbdisa AbdellaNo ratings yet
- Cid 2 CodeDocument662 pagesCid 2 CodeTạ ĐạtNo ratings yet
- Amharic Abstractive Text SummarizationDocument5 pagesAmharic Abstractive Text SummarizationpolymorphNo ratings yet
- Parallel Korpuslarni Yaratish AsoslariDocument7 pagesParallel Korpuslarni Yaratish AsoslariМанзура AбжаловаNo ratings yet
- Multi-Class Text ClassificationDocument6 pagesMulti-Class Text ClassificationLarissa FelicianaNo ratings yet
- NLP Project Final Report1Document10 pagesNLP Project Final Report1hewepo4344No ratings yet
- Understanding Computational by Nitya ADocument84 pagesUnderstanding Computational by Nitya AP1972No ratings yet
- Important QuestionsDocument13 pagesImportant QuestionsIkram ChebilNo ratings yet
- Discourse Analysis of English General Extenders in Nigerian Newspapers EditorialsDocument32 pagesDiscourse Analysis of English General Extenders in Nigerian Newspapers EditorialsEwata ThompsonNo ratings yet
- ياسمين حكمتDocument130 pagesياسمين حكمتNaba Majed75% (8)
- Theory of Automata/Computation: Finite Automata, Regular Expressions and MachinesDocument42 pagesTheory of Automata/Computation: Finite Automata, Regular Expressions and MachinesAashish PaliwalNo ratings yet
- Unit 7-NLPDocument33 pagesUnit 7-NLPNandyala Venkanna BabuNo ratings yet
- State of The Art - Word Sense DisambiguationDocument41 pagesState of The Art - Word Sense DisambiguationStefanus SantosaNo ratings yet
- Towards Computational Processing of SanskritDocument10 pagesTowards Computational Processing of SanskritTapas BadalNo ratings yet
- Mahabharata ProjectDocument9 pagesMahabharata ProjectCanumalla Ramkumar0% (1)
- ComputationalDocument22 pagesComputationalAlexandraAliaNo ratings yet
- DFA MinimizationDocument25 pagesDFA MinimizationAnikNo ratings yet
- Transducers: Anab Batool KazmiDocument38 pagesTransducers: Anab Batool Kazmiسیدہ ماریہNo ratings yet
- 12 Hour 24 Hour Clock Grade 4 Maths Resources Printable Worksheets w10Document3 pages12 Hour 24 Hour Clock Grade 4 Maths Resources Printable Worksheets w10henrywin.heinkhantwin.29No ratings yet
- Sociology in The Era of Big Data: The Ascent of Forensic Social ScienceDocument24 pagesSociology in The Era of Big Data: The Ascent of Forensic Social ScienceRodrigo FernandezNo ratings yet
- متر مربعDocument2 pagesمتر مربعahmad aliNo ratings yet
- 文学在研究中的重要性Document6 pages文学在研究中的重要性betemykovan3No ratings yet
- Lecture1 FSNLPDocument49 pagesLecture1 FSNLPGautam KhannaNo ratings yet
- Large Language Models: A SurveyDocument43 pagesLarge Language Models: A SurveyLucas Vital Alves da SilvaNo ratings yet
- Chapter2 PDFDocument22 pagesChapter2 PDFNourheneMbarekNo ratings yet