You might also like
- Measures of Central TendencyDocument19 pagesMeasures of Central TendencyVhem Lacre Camposano0% (1)
- Making Sense of Data II: A Practical Guide to Data Visualization, Advanced Data Mining Methods, and ApplicationsFrom EverandMaking Sense of Data II: A Practical Guide to Data Visualization, Advanced Data Mining Methods, and ApplicationsNo ratings yet
- Actividad3 2Document8 pagesActividad3 2Darleen Ariana Serruto AlarconNo ratings yet
- LS3 Modules With Worksheets (Mean, Median, Mode and Range)Document18 pagesLS3 Modules With Worksheets (Mean, Median, Mode and Range)Ronalyn Maldan100% (2)
- LEC 9 - Measures of VariabilityDocument16 pagesLEC 9 - Measures of VariabilityRyan MartinezNo ratings yet
- EOT - Calculation of Rainfall DelayDocument17 pagesEOT - Calculation of Rainfall DelayshideshuomNo ratings yet
- BasementDocument5 pagesBasementHisham BerrasaliNo ratings yet
- Product DatasDocument5 pagesProduct Datasapi-3757629No ratings yet
- Data Hujan HarianDocument34 pagesData Hujan HarianAgung RubianNo ratings yet
- Square and Round Bar Weights and PropertiesDocument2 pagesSquare and Round Bar Weights and PropertiesLan MendietaNo ratings yet
- Practica 3 LB Fis 3Document7 pagesPractica 3 LB Fis 3Adriana RosasNo ratings yet
- Data Sondir S-2Document3 pagesData Sondir S-2TaufikBudhiNo ratings yet
- Regresion LinealDocument5 pagesRegresion LinealBRYAN ANTHONY CALDERON CESPEDESNo ratings yet
- Bab IiiDocument18 pagesBab IiiNiaNo ratings yet
- 2 Metodo IntegralDocument3 pages2 Metodo IntegralPedroNo ratings yet
- 2 Metodo IntegralDocument3 pages2 Metodo IntegralPedroNo ratings yet
- CLASEPOVEDADocument5 pagesCLASEPOVEDARenata Elena Lechado VanegasNo ratings yet
- Frequencies: Frequencies Variables Idade /statistics Variance Mean /order AnalysisDocument24 pagesFrequencies: Frequencies Variables Idade /statistics Variance Mean /order AnalysisNique Miguel JoséNo ratings yet
- DN Pipe PDFDocument6 pagesDN Pipe PDFnassimNo ratings yet
- GraficasDocument7 pagesGraficaswalterNo ratings yet
- Form LaporanDocument36 pagesForm LaporantriNo ratings yet
- H.W of The Statistics: Republic of Yemen Sana'a University Faculty of Engineering Department of Mechanical EngineeringDocument7 pagesH.W of The Statistics: Republic of Yemen Sana'a University Faculty of Engineering Department of Mechanical Engineeringعبدالملك جمالNo ratings yet
- Katalis 6%Document16 pagesKatalis 6%Ainan AziziNo ratings yet
- PE Pipes and WeightsDocument2 pagesPE Pipes and WeightsSandesh PoudelNo ratings yet
- 14 PoissonExponentialDocument14 pages14 PoissonExponentialrasha assafNo ratings yet
- No. Tegangan (Volt) Arus (Ma)Document3 pagesNo. Tegangan (Volt) Arus (Ma)Rolando ManurungNo ratings yet
- 3 LabuanDocument30 pages3 LabuanAiman Ariffin NordinNo ratings yet
- Chemistry Experiment 2Document12 pagesChemistry Experiment 2Malak MahmoudNo ratings yet
- GraficaDocument2 pagesGraficaAlexander ChitayNo ratings yet
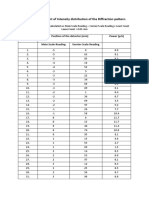
- (A) Measurement of Intensity Distribution of The Diffraction PatternDocument2 pages(A) Measurement of Intensity Distribution of The Diffraction PatternBhupesh YadavNo ratings yet
- Obtención de La Respuesta DinámicaDocument34 pagesObtención de La Respuesta Dinámicafrancisco rodriguezNo ratings yet
- Calculo Escollera Maynord Vs Department of Transportation - CaliforniaDocument3 pagesCalculo Escollera Maynord Vs Department of Transportation - CaliforniaaduladorNo ratings yet
- Tata SHSDocument7 pagesTata SHSakshay pawarNo ratings yet
- Assignment3 SolveDocument10 pagesAssignment3 SolveKeriann LNo ratings yet
- RSI:Internet:Textile, Clothing&footwear:all Bus:VAL NSA:internet Av Week Sales M Not Seasonally Adjusted Current Prices MillionDocument2 pagesRSI:Internet:Textile, Clothing&footwear:all Bus:VAL NSA:internet Av Week Sales M Not Seasonally Adjusted Current Prices MillionPrasiddha PradhanNo ratings yet
- Power of Compounding in SIP-1Document3 pagesPower of Compounding in SIP-1Nortex MarketingNo ratings yet
- PM Assignment TwoDocument15 pagesPM Assignment TwoGonzalo MoyaNo ratings yet
- IB Chemistry SL Lab Report: Acid Base TitrationDocument6 pagesIB Chemistry SL Lab Report: Acid Base Titrationxavier bourret sicotte75% (4)
- Data Untuk Routing Waduk: Hasil PerhitunganDocument2 pagesData Untuk Routing Waduk: Hasil PerhitunganSiti RauhunNo ratings yet
- Ahsanullah University of Science and Technology: Electrical & Electronic Engineering DeptDocument4 pagesAhsanullah University of Science and Technology: Electrical & Electronic Engineering DeptbappyNo ratings yet
- Excel Caudales Hidra 2018Document2 pagesExcel Caudales Hidra 2018isaias charaja montañoNo ratings yet
- Hostel Paint 2nd Billing Kuya EvicDocument4 pagesHostel Paint 2nd Billing Kuya EvicJudy AbaoNo ratings yet
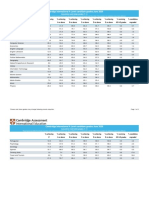
- Cambridge International A Level Candidate Grades June 2020Document2 pagesCambridge International A Level Candidate Grades June 2020Musa ChNo ratings yet
- Results - WORK - ELECTIONDocument1 pageResults - WORK - ELECTIONGerome JacintoNo ratings yet
- Lab Report E.coliDocument9 pagesLab Report E.colihasanulfiqryNo ratings yet
- Hidrograma UnitarioDocument5 pagesHidrograma UnitarioMOISES AARON RUIZ MARTINEZNo ratings yet
- Expt 8Document6 pagesExpt 8nooneNo ratings yet
- Precipitación de Los Años 1997-2010Document8 pagesPrecipitación de Los Años 1997-2010Vanessa Vera ReyesNo ratings yet
- Gamma GammaDocument3 pagesGamma GammaDebayan BiswasNo ratings yet
- Lloyds TableDocument4 pagesLloyds Tablerf.rifki3No ratings yet
- Laboratorium Mekanika Tanah: Fakultas TeknikDocument2 pagesLaboratorium Mekanika Tanah: Fakultas TeknikmuflihahsophiarNo ratings yet
- Station 1 2 3 4 5Document9 pagesStation 1 2 3 4 5Javier CastNo ratings yet
- 5.1 Type of Material: Aluminium: Table 1 Tensile Test Raw DataDocument1 page5.1 Type of Material: Aluminium: Table 1 Tensile Test Raw DataSlim ShaddysNo ratings yet
- Development EconomicsDocument18 pagesDevelopment EconomicsYash Vardhan GuptaNo ratings yet
- PropertiesDocument5 pagesPropertiesskumarsrNo ratings yet
- Examen Final LaboDocument3 pagesExamen Final LaboMoises ClNo ratings yet
- Sessional On Numerical Analysis and Computer Programming CE 2208Document3 pagesSessional On Numerical Analysis and Computer Programming CE 2208Asif RezaNo ratings yet
- Modul4Document3 pagesModul4ranaNo ratings yet
- Data Laprak Modul 4 Versi 2Document6 pagesData Laprak Modul 4 Versi 2MutiarasitohangNo ratings yet
- Media 12.3 4.2 Covarianza 7.85 Varianza X 49.3 Varianza Y 1.8Document4 pagesMedia 12.3 4.2 Covarianza 7.85 Varianza X 49.3 Varianza Y 1.8Joc AngelNo ratings yet
- SENAMHIDocument1 pageSENAMHIJhon Edgar AJNo ratings yet
- PrecipitacionDocument175 pagesPrecipitacionPaco UtreraNo ratings yet
- Government Publications: Key PapersFrom EverandGovernment Publications: Key PapersBernard M. FryNo ratings yet
- INTRODUCTIONDocument2 pagesINTRODUCTIONvinethirra nantha kumarNo ratings yet
- Measure of Central TendencyDocument35 pagesMeasure of Central TendencyPuttu Guru PrasadNo ratings yet
- When To Use Mean Median ModeDocument2 pagesWhen To Use Mean Median ModeMadison HartfieldNo ratings yet
- Intermediate Social Statistics A Conceptual and Graphic Approach Full ChapterDocument41 pagesIntermediate Social Statistics A Conceptual and Graphic Approach Full Chapterjennifer.calhoun425100% (23)
- Unit-I Introduction To Statistics:: 1. Statistics Are Aggregate of FactsDocument121 pagesUnit-I Introduction To Statistics:: 1. Statistics Are Aggregate of Factssamreen hafsaNo ratings yet
- Assignment 8614Document19 pagesAssignment 8614Mano BiliNo ratings yet
- 4 Measures of Centrality: Mean, Median, Mode, Grouped DataDocument18 pages4 Measures of Centrality: Mean, Median, Mode, Grouped DataRejesh MeladNo ratings yet
- GRADE8Document10 pagesGRADE8Etheyl SolanoNo ratings yet
- Measures of Central Tendency (Mean, Median, Mode)Document6 pagesMeasures of Central Tendency (Mean, Median, Mode)RhoseNo ratings yet
- Nda Test Maths-1Document18 pagesNda Test Maths-1ROHIT YadavNo ratings yet
- SPSS Without PainDocument179 pagesSPSS Without PainDivine ExcellenceNo ratings yet
- Why We Need More Than One Measure of Central Tendency (Mean, Median and Mode) 8 Grade Lesson PlanDocument6 pagesWhy We Need More Than One Measure of Central Tendency (Mean, Median and Mode) 8 Grade Lesson PlanYetzNo ratings yet
- Anjali BRMbasic Data AnalysisDocument19 pagesAnjali BRMbasic Data Analysisbhavya86No ratings yet
- Homework 8 Angle ProofsDocument7 pagesHomework 8 Angle Proofsafnaebacfrdngp100% (1)
- Statistics-WPS OfficeDocument4 pagesStatistics-WPS OfficeManan paniNo ratings yet
- Module 4 Data Management (Part 1)Document27 pagesModule 4 Data Management (Part 1)Kayla Sophia PatioNo ratings yet
- Educ 203 Finals Jenny Rose B. RoblesDocument11 pagesEduc 203 Finals Jenny Rose B. RoblesSummer R. DominguezNo ratings yet
- Measures of Central Tendency SummativeDocument4 pagesMeasures of Central Tendency SummativeFrancis Ruel FloresNo ratings yet
- Accuracy and PrecisionDocument16 pagesAccuracy and PrecisionG BabuNo ratings yet
- Bulacan State University: Assessment of Student Learning 1 Utilization of Assessment DataDocument9 pagesBulacan State University: Assessment of Student Learning 1 Utilization of Assessment DataReymart De GuzmanNo ratings yet
- Chapter 1Document44 pagesChapter 1hazriq hakimNo ratings yet
- Weekly Learning Plan: Calculates The Measures of Central Tendency of Ungrouped and Grouped DataDocument5 pagesWeekly Learning Plan: Calculates The Measures of Central Tendency of Ungrouped and Grouped DataLawrence IluminNo ratings yet
- Statistics Homework Answers - Stats Homework AnswersDocument2 pagesStatistics Homework Answers - Stats Homework Answersmorris7oneal9No ratings yet
- VIDYA SAGAR ABC Analysis For CA Foundation BMRS For Dec 2021Document3 pagesVIDYA SAGAR ABC Analysis For CA Foundation BMRS For Dec 2021FREEFIRE IDNo ratings yet
- Assessing Learning in A Classroom EnvironmentDocument6 pagesAssessing Learning in A Classroom EnvironmentAngela Tinio LomagdongNo ratings yet
- 9+&+10+Hindi+Umang+-+CBSE+10+-+2020+ +statistics+-+1+ +Introduction+and+mean+of+Grouped+Data+ +16th+IOctDocument40 pages9+&+10+Hindi+Umang+-+CBSE+10+-+2020+ +statistics+-+1+ +Introduction+and+mean+of+Grouped+Data+ +16th+IOctMariyam AfreenNo ratings yet
- Statistics and Probability: A. - B. Data. C. Apply The Concept of in Real Life by Solving Word ProblemsDocument8 pagesStatistics and Probability: A. - B. Data. C. Apply The Concept of in Real Life by Solving Word ProblemsAnna Lizette Clapis DeGuzman100% (2)