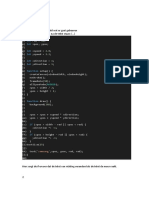
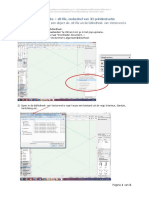
You might also like
- Excel draaitabellen en -grafieken Visuele handleiding in stappenFrom EverandExcel draaitabellen en -grafieken Visuele handleiding in stappenNo ratings yet
- Problem Set 14Document3 pagesProblem Set 14akdjfNo ratings yet
- Excel draaitabellen en -grafieken Visuele handleiding in stappen: Inclusief oefenprojecten en oplossingen voor beginnersFrom EverandExcel draaitabellen en -grafieken Visuele handleiding in stappen: Inclusief oefenprojecten en oplossingen voor beginnersNo ratings yet
- OloloDocument6 pagesOloloikbenmorganfreeman2No ratings yet
- wk02 PlottingDocument7 pageswk02 Plottingtanmay sharmaNo ratings yet
- Uitvoeren Two Way ANOVADocument4 pagesUitvoeren Two Way ANOVAMarie OnsiaNo ratings yet
- Inleiding MatlabDocument11 pagesInleiding MatlabJorick LeferinkNo ratings yet
- Te Kennen en Kunnen Python Programmeren en Informatie - Q2 - 2021-2022Document2 pagesTe Kennen en Kunnen Python Programmeren en Informatie - Q2 - 2021-202210HoursOfEnjoymentNo ratings yet
- Opdracht Linux 2022 Maws VT Blok5 Antwoord FormulierDocument3 pagesOpdracht Linux 2022 Maws VT Blok5 Antwoord FormulierTimNo ratings yet
- Acad Tips Voor Beginners!!Document10 pagesAcad Tips Voor Beginners!!Jos vd heijdenNo ratings yet
- Overzicht Van Onderwerpen en Opgavenselectie Dynamica 4V Voor de ToetsDocument2 pagesOverzicht Van Onderwerpen en Opgavenselectie Dynamica 4V Voor de ToetsJamel KamalNo ratings yet
- Car Week 5 440905Document10 pagesCar Week 5 440905Davy VNo ratings yet
- Digitale Signaalbewerking Verslag Thomas Randwijk, Marleen BeekmanDocument13 pagesDigitale Signaalbewerking Verslag Thomas Randwijk, Marleen BeekmanThomas RandwijkNo ratings yet
- TheorieDocument5 pagesTheorieTom CrulNo ratings yet
- Les01 BasiselementenDocument24 pagesLes01 Basiselementenkgurleen1808No ratings yet
- MATLAB SamenvattingDocument4 pagesMATLAB SamenvattingYassin KaissiNo ratings yet
- Les 1Document17 pagesLes 1Bastiaan GelaudeNo ratings yet
- FunctiesDocument11 pagesFunctiesJeroenNo ratings yet
- Examen 2013Document4 pagesExamen 2013User070213No ratings yet
- 03 RDBMS OefeningenDocument10 pages03 RDBMS OefeningenTom CrulNo ratings yet
- Gegevens Exporteren Uit TOPdesk (Deel2)Document3 pagesGegevens Exporteren Uit TOPdesk (Deel2)TOPdeskNo ratings yet
- Spss Stappensyllabusv18Document53 pagesSpss Stappensyllabusv18soopleNo ratings yet
- InwoDocument21 pagesInwoNelson SilveiraNo ratings yet
- Rapport 1 Numerieke AnalyseDocument8 pagesRapport 1 Numerieke AnalyseMichaël CassiqueNo ratings yet
- Voorbeeldoplossingen 2016 2017Document64 pagesVoorbeeldoplossingen 2016 2017kaatje_peirsNo ratings yet
- Formularium Matlab 1FI2Document7 pagesFormularium Matlab 1FI2Stijn BoutsenNo ratings yet
- VoorbeeldoplossingenDocument64 pagesVoorbeeldoplossingenkaatje_peirsNo ratings yet
- VoorbeeldoplossingenDocument29 pagesVoorbeeldoplossingenkaatje_peirsNo ratings yet
- JavascriptDocument23 pagesJavascriptharsha.kanaparthi20062No ratings yet
- Os Lab Exercise 10Document10 pagesOs Lab Exercise 10jakeingram129No ratings yet
- Informatica Po2Document10 pagesInformatica Po2dean akeroydNo ratings yet
- Java 1Document10 pagesJava 1sigoderiNo ratings yet
- Reële Functies 5Document31 pagesReële Functies 5tobemerv100% (5)
- VWO 4 H1 Oefenproefwerk PDFDocument5 pagesVWO 4 H1 Oefenproefwerk PDFMTL GamesNo ratings yet
- Vademecum Wiskunde 2de JaarDocument28 pagesVademecum Wiskunde 2de Jaarpimwie007No ratings yet
- Uitvoeren One Way ANOVA RStudioDocument3 pagesUitvoeren One Way ANOVA RStudioMarie OnsiaNo ratings yet
- ABC ProgramariiDocument1 pageABC ProgramariiCristianaTrifuNo ratings yet
- Project 42Document16 pagesProject 42Grégory LangedockNo ratings yet
- Breuksplitsen 2Document4 pagesBreuksplitsen 2Giovanni KarsopawiroNo ratings yet
- Texas Instruments Ti Nspire CX II T CollectieDocument115 pagesTexas Instruments Ti Nspire CX II T CollectiesupergamerdaafNo ratings yet
- Vector/Matrix Library in JavascriptDocument12 pagesVector/Matrix Library in JavascriptkajdijkstraNo ratings yet
- Opgaven Line Balancing Met AntwoordenDocument15 pagesOpgaven Line Balancing Met AntwoordenMark LeeuwerikNo ratings yet
- Voorbereidend MateriaalDocument63 pagesVoorbereidend Materiaalmees.neo.ontNo ratings yet
- Gegevens Exporteren Uit TOPdeskDocument3 pagesGegevens Exporteren Uit TOPdeskTOPdeskNo ratings yet
- Excel Basis ADocument6 pagesExcel Basis Ahourani naeemNo ratings yet
- Hand Lei Ding JetCAD Pro 2Document60 pagesHand Lei Ding JetCAD Pro 2Jempy1No ratings yet
- IVR - Korte Cursus DOS - v1.2Document21 pagesIVR - Korte Cursus DOS - v1.2cezz blommendaalNo ratings yet
- Bundel Herhalingsoefeningen 4TIWTWDocument17 pagesBundel Herhalingsoefeningen 4TIWTWBronze MelkNo ratings yet
- Handreiking VectorworksDocument3 pagesHandreiking Vectorworksapi-361136817No ratings yet
- Lesbrief Struktograaf 2012Document14 pagesLesbrief Struktograaf 2012MNo ratings yet
- Operativni Sistemi: DR Dušan Malić, Prof. Struk. StudDocument13 pagesOperativni Sistemi: DR Dušan Malić, Prof. Struk. StudAnica Dragan DjurkicNo ratings yet
- D - PythonDocument5 pagesD - PythonJochem ter BruggeNo ratings yet
- Hoofdstuk 1 - Verschillende Datastructuren: InleidingDocument2 pagesHoofdstuk 1 - Verschillende Datastructuren: InleidingJochem ter BruggeNo ratings yet
- TP5 Et 6Document3 pagesTP5 Et 6Anthonio RabarijaonaNo ratings yet
- PSD ProgrammerenDocument16 pagesPSD ProgrammerenGuido75% (4)
- TINPRO04-1 2023-2024 Proeftentamen (Antwoorden (14p) )Document7 pagesTINPRO04-1 2023-2024 Proeftentamen (Antwoorden (14p) )Mohammed Amin ElmNo ratings yet
- Toets 1.3Document2 pagesToets 1.3Jenthe SegersNo ratings yet
- Agenda Uitnodigingen Meesturen Vanuit TOPdeskDocument3 pagesAgenda Uitnodigingen Meesturen Vanuit TOPdeskTOPdeskNo ratings yet
- Comparch22 23OSDocument32 pagesComparch22 23OSEric PailletNo ratings yet
- Over j8051: Een 8051 Assembler Met Syntax Highlighti NG Specifi Ek Voor de XC888Document7 pagesOver j8051: Een 8051 Assembler Met Syntax Highlighti NG Specifi Ek Voor de XC888Music NonstopNo ratings yet
- Brand management in 4 stappen: Strategieën voor het beheer van de marketing van uw merk om het potentieel en de doeltreffendheid ervan te verhogenFrom EverandBrand management in 4 stappen: Strategieën voor het beheer van de marketing van uw merk om het potentieel en de doeltreffendheid ervan te verhogenNo ratings yet
- Waardevolle Agile Retrospectives: Een gereedschapskist met retrospective oefeningenFrom EverandWaardevolle Agile Retrospectives: Een gereedschapskist met retrospective oefeningenNo ratings yet
- PowerShell: Een Complete Gids: De IT collectieFrom EverandPowerShell: Een Complete Gids: De IT collectieRating: 5 out of 5 stars5/5 (1)
- Artificiële Intelligentie in rekrutering: Menselijke hulpbronnenFrom EverandArtificiële Intelligentie in rekrutering: Menselijke hulpbronnenRating: 5 out of 5 stars5/5 (1)
- Trading met japanse kaarsen eenvoudig: De inleidende gids voor de trading in candlestick en de meest effectieve technische analysestrategieënFrom EverandTrading met japanse kaarsen eenvoudig: De inleidende gids voor de trading in candlestick en de meest effectieve technische analysestrategieënNo ratings yet
- AI in Business: Praktische Gids voor het Toepassen van Kunstmatige Intelligentie in Diverse BedrijfstakkenFrom EverandAI in Business: Praktische Gids voor het Toepassen van Kunstmatige Intelligentie in Diverse BedrijfstakkenNo ratings yet
- Webteksten die werken: 121 bullshit-vrije en meteen toepasbare tipsFrom EverandWebteksten die werken: 121 bullshit-vrije en meteen toepasbare tipsNo ratings yet
- Een eenvoudige benadering van SEO: Hoe de grondbeginselen van zoekmachine optimalisatie te begrijpen op een eenvoudige en praktische manier door middel van een niet-gespecialiseerd pad van ontdekking gericht op iedereenFrom EverandEen eenvoudige benadering van SEO: Hoe de grondbeginselen van zoekmachine optimalisatie te begrijpen op een eenvoudige en praktische manier door middel van een niet-gespecialiseerd pad van ontdekking gericht op iedereenNo ratings yet
- Online trading gemakkelijk gemaakt: De informatie die u moet weten om een succesvolle online belegger te wordenFrom EverandOnline trading gemakkelijk gemaakt: De informatie die u moet weten om een succesvolle online belegger te wordenNo ratings yet
- Hoe kun je geld verdienen met het maken van YouTube-video's zonder je gezicht te laten zien: 4 geweldige geheimen om rijk te worden van YouTube-kanalen zonder je gezicht en stem te gebruikenFrom EverandHoe kun je geld verdienen met het maken van YouTube-video's zonder je gezicht te laten zien: 4 geweldige geheimen om rijk te worden van YouTube-kanalen zonder je gezicht en stem te gebruikenNo ratings yet
- In de hoofden van grote investeerders: De psychologie die door de grootste investeerders aller tijden wordt gebruikt door middel van aforismen, biografieën, citaten en opera'sFrom EverandIn de hoofden van grote investeerders: De psychologie die door de grootste investeerders aller tijden wordt gebruikt door middel van aforismen, biografieën, citaten en opera'sNo ratings yet
- Mastering Apple HomePod: The Ultimate HomePod Gebruikershandleiding IOS 12From EverandMastering Apple HomePod: The Ultimate HomePod Gebruikershandleiding IOS 12No ratings yet
- Fundamentele analyse eenvoudig gemaakt: De inleidende gids voor fundamentele analysetechnieken en -strategieën om te anticiperen op de gebeurtenissen die de markten in beweging brengenFrom EverandFundamentele analyse eenvoudig gemaakt: De inleidende gids voor fundamentele analysetechnieken en -strategieën om te anticiperen op de gebeurtenissen die de markten in beweging brengenNo ratings yet
- Excel draaitabellen en -grafieken Visuele handleiding in stappenFrom EverandExcel draaitabellen en -grafieken Visuele handleiding in stappenNo ratings yet
- Denk en investeer als Warren Buffett: Het handboek dat de mentaliteit en denkwijze van de grootste belegger aller tijden onthultFrom EverandDenk en investeer als Warren Buffett: Het handboek dat de mentaliteit en denkwijze van de grootste belegger aller tijden onthultNo ratings yet
- Het Handboek voor Marketing Evangelisten: Hoe kunt u uw producten, uw ideeën of uw bedrijf promoten met behulp van de principes van de marketing evangelistFrom EverandHet Handboek voor Marketing Evangelisten: Hoe kunt u uw producten, uw ideeën of uw bedrijf promoten met behulp van de principes van de marketing evangelistNo ratings yet
- Technische analyse eenvoudig gemaakt: Hoe kunt u technische analysegrafieken bouwen en interpreteren om uw online handelsactiviteit te verbeterenFrom EverandTechnische analyse eenvoudig gemaakt: Hoe kunt u technische analysegrafieken bouwen en interpreteren om uw online handelsactiviteit te verbeterenNo ratings yet
- Social Media marketing Geheimen 2021: Laat je Online Business groeien met Facebook; Uiterst Effectieve Tips & Strategieën om een Autoriteit in je Niche te wordenFrom EverandSocial Media marketing Geheimen 2021: Laat je Online Business groeien met Facebook; Uiterst Effectieve Tips & Strategieën om een Autoriteit in je Niche te wordenRating: 5 out of 5 stars5/5 (1)
- Idee van de innovatieve immobiliënmatching: Immobiliënbemiddeling eenvoudig gemaakt: Immobiliënmatching: De efficiënte, eenvoudige en professionele immobiliënbemiddeling door een innovatief immobiliënmatchingportaalFrom EverandIdee van de innovatieve immobiliënmatching: Immobiliënbemiddeling eenvoudig gemaakt: Immobiliënmatching: De efficiënte, eenvoudige en professionele immobiliënbemiddeling door een innovatief immobiliënmatchingportaalNo ratings yet
- Bitcoin en andere cryptovaluta: Hoe je dacht te laat in crypto te stappen maar succesvoller werd dan mensen die dit boek niet lazenFrom EverandBitcoin en andere cryptovaluta: Hoe je dacht te laat in crypto te stappen maar succesvoller werd dan mensen die dit boek niet lazenNo ratings yet