You might also like
- Superscalar Execution in a Multiple-Issue PipelineDocument13 pagesSuperscalar Execution in a Multiple-Issue Pipelineg7812No ratings yet
- Relational Database Index Design and the Optimizers: DB2, Oracle, SQL Server, et al.From EverandRelational Database Index Design and the Optimizers: DB2, Oracle, SQL Server, et al.Rating: 5 out of 5 stars5/5 (1)
- Remainder of CIS501: Parallelism: System Software App App AppDocument14 pagesRemainder of CIS501: Parallelism: System Software App App AppEng BahanzaNo ratings yet
- SuperscalarDocument38 pagesSuperscalarNusrat Mary ChowdhuryNo ratings yet
- William Stallings Computer Organization and Architecture 8 EditionDocument38 pagesWilliam Stallings Computer Organization and Architecture 8 EditionNEOROVENo ratings yet
- UntitledDocument46 pagesUntitledGaurab GhoseNo ratings yet
- Instruction Level Parallelism and Superscalar ProcessorsDocument34 pagesInstruction Level Parallelism and Superscalar ProcessorsJohn Michael MarasiganNo ratings yet
- Parallel Processing: 6.004x Computation Structures Part 3 - Computer OrganizationDocument41 pagesParallel Processing: 6.004x Computation Structures Part 3 - Computer OrganizationLee RickHunterNo ratings yet
- Superscalar ILP techniquesDocument36 pagesSuperscalar ILP techniquesRadwa TawfeekNo ratings yet
- Ch2 Lec7 Instruction PipliningDocument34 pagesCh2 Lec7 Instruction PipliningAlazar DInberuNo ratings yet
- CH - 14 - Instruction Level Parallelism and Superscalar ProcessorsDocument42 pagesCH - 14 - Instruction Level Parallelism and Superscalar ProcessorsGita RamdhaniNo ratings yet
- EE (CE) 6304 Computer Architecture Lecture #2 (8/28/13)Document35 pagesEE (CE) 6304 Computer Architecture Lecture #2 (8/28/13)Vishal MehtaNo ratings yet
- Superscalar and VLIW Processors ExplainedDocument49 pagesSuperscalar and VLIW Processors ExplainedBijay MishraNo ratings yet
- Presentationvamvatsikos 170704232726Document29 pagesPresentationvamvatsikos 170704232726Borjan PetreskiNo ratings yet
- Superscalar ILPDocument89 pagesSuperscalar ILPNaga BinduNo ratings yet
- Instruction Pipelining Stages and HazardsDocument29 pagesInstruction Pipelining Stages and HazardsMd. Firoz HasanNo ratings yet
- Multiple Issue Processors ExplainedDocument40 pagesMultiple Issue Processors ExplainedrazorviperNo ratings yet
- EE6304 Lecture13 ProcessorsDocument69 pagesEE6304 Lecture13 ProcessorsAshish SoniNo ratings yet
- Week 4 - PipeliningDocument44 pagesWeek 4 - Pipeliningdress dressNo ratings yet
- William Stallings Computer Organization and Architecture 8th Edition Chapter 14 Instruction Level Parallelism and Superscalar ProcessorsDocument50 pagesWilliam Stallings Computer Organization and Architecture 8th Edition Chapter 14 Instruction Level Parallelism and Superscalar ProcessorsMinkpoo Lexy UtomoNo ratings yet
- Superscaling in Computer ArchitectureDocument9 pagesSuperscaling in Computer ArchitectureC183007 Md. Nayem HossainNo ratings yet
- Traditional Asic DesignflowDocument103 pagesTraditional Asic DesignflowYamini SaraswathiNo ratings yet
- Advanced Computer Architecture Prof Thriveni T KDocument59 pagesAdvanced Computer Architecture Prof Thriveni T KPalaganiRamakrishnaNo ratings yet
- 5 6Document26 pages5 6cn3588No ratings yet
- Lec 01Document34 pagesLec 01Lekha PylaNo ratings yet
- Pipelining - Lecture 2Document19 pagesPipelining - Lecture 2eldho k josephNo ratings yet
- PQC Overview Aug 2020 (NIST)Document57 pagesPQC Overview Aug 2020 (NIST)Daniel AponNo ratings yet
- System-on-Chip Design: 2ECDE54Document24 pagesSystem-on-Chip Design: 2ECDE54Pragya jhalaNo ratings yet
- Chapter 4 Processors and Memory Hierarchy: Module-2Document6 pagesChapter 4 Processors and Memory Hierarchy: Module-2shamsiya saNo ratings yet
- Embedded Systems Design: Pipelining and Instruction SchedulingDocument48 pagesEmbedded Systems Design: Pipelining and Instruction SchedulingMisbah Sajid ChaudhryNo ratings yet
- For Atmega8Document47 pagesFor Atmega8Rajesh Kumar100% (1)
- Synchronization Public2Document89 pagesSynchronization Public2firefoxextslurperNo ratings yet
- A Wire-Delay Scalable Microprocessor Architecture For High Performance SystemsDocument20 pagesA Wire-Delay Scalable Microprocessor Architecture For High Performance SystemskevintungjungchenNo ratings yet
- Chapter 5Document38 pagesChapter 5noussaiba.belhouariNo ratings yet
- ILPDocument47 pagesILPvengat.mailbox5566No ratings yet
- CH7-Parallel and Pipelined ProcessingDocument23 pagesCH7-Parallel and Pipelined Processingaashifr469No ratings yet
- ACA Mod2Document45 pagesACA Mod2avi003No ratings yet
- Superscalar Part 2 - 2017Document16 pagesSuperscalar Part 2 - 2017Muhammad RifkiNo ratings yet
- Comp422 534 2020 Lecture1 IntroductionDocument49 pagesComp422 534 2020 Lecture1 IntroductionSadia MughalNo ratings yet
- Pipelining and ParallelismDocument41 pagesPipelining and ParallelismPratham GuptaNo ratings yet
- Itwiki PHPDocument47 pagesItwiki PHPwildan sudibyoNo ratings yet
- Computer Architecture Chapter 4: The Processor Part 3: Dr. Phạm Quốc CườngDocument23 pagesComputer Architecture Chapter 4: The Processor Part 3: Dr. Phạm Quốc CườngMy HeoNo ratings yet
- Ca08 2014 PDFDocument54 pagesCa08 2014 PDFPance CvetkovskiNo ratings yet
- Comp422 2011 Lecture1 IntroductionDocument50 pagesComp422 2011 Lecture1 IntroductionaskbilladdmicrosoftNo ratings yet
- Unit 3 PartDocument15 pagesUnit 3 PartArnav AgarwalNo ratings yet
- Aca NotesDocument23 pagesAca NotesSriram JanakiramanNo ratings yet
- ParallelismDocument22 pagesParallelismdeivasigamaniNo ratings yet
- CS 6290 Instruction Level ParallelismDocument45 pagesCS 6290 Instruction Level ParallelismTathagata Roy ChowdhuryNo ratings yet
- Chap1 IntroDocument30 pagesChap1 IntroSetina AliNo ratings yet
- Parallel Computing PlatformsDocument38 pagesParallel Computing PlatformswmanjonjoNo ratings yet
- Module 1: PARALLEL AND DISTRIBUTED COMPUTINGDocument65 pagesModule 1: PARALLEL AND DISTRIBUTED COMPUTINGVandana M 19BCE1763No ratings yet
- TRIPS - An EDGE Instruction Set Architecture: Chirag Shah April 24, 2008Document35 pagesTRIPS - An EDGE Instruction Set Architecture: Chirag Shah April 24, 2008Engr Ayaz KhanNo ratings yet
- A Study On Hyper-Threading: Vimal Reddy Ambarish Sule Aravindh AnantaramanDocument29 pagesA Study On Hyper-Threading: Vimal Reddy Ambarish Sule Aravindh AnantaramanVetrivel SubramaniNo ratings yet
- Superscalar Architectures: COMP375 Computer Architecture and OrganizationDocument35 pagesSuperscalar Architectures: COMP375 Computer Architecture and OrganizationIndumathi ElayarajaNo ratings yet
- CSE 820 Graduate Computer Architecture Course OverviewDocument25 pagesCSE 820 Graduate Computer Architecture Course OverviewkbkkrNo ratings yet
- FPGA Design TechniquesDocument32 pagesFPGA Design TechniquesRavindra SainiNo ratings yet
- System On Chip Architecture Design Lecture15Document15 pagesSystem On Chip Architecture Design Lecture15Thi NguyenNo ratings yet
- (T13-14) - Arquitecturas 1 y 2Document88 pages(T13-14) - Arquitecturas 1 y 2CorreoBasuraNo ratings yet
- Variables in Language Teaching - The Role of The TeacherDocument34 pagesVariables in Language Teaching - The Role of The TeacherFatin AqilahNo ratings yet
- DNA Affirmative - MSDI 2015Document146 pagesDNA Affirmative - MSDI 2015Michael TangNo ratings yet
- Angelomorphic Christology and The Book of Revelation - Matthias Reinhard HoffmannDocument374 pagesAngelomorphic Christology and The Book of Revelation - Matthias Reinhard HoffmannEusebius325100% (2)
- Rotational Equilibrium SimulationDocument3 pagesRotational Equilibrium SimulationCamille ManlongatNo ratings yet
- Characteristics and Guidelines of PublicspaceDocument3 pagesCharacteristics and Guidelines of PublicspaceJanani SurenderNo ratings yet
- Barcelona Smart City TourDocument44 pagesBarcelona Smart City TourPepe JeansNo ratings yet
- Prof. Ed - Assessment and Evaluation of Learning Part 1-4Document8 pagesProf. Ed - Assessment and Evaluation of Learning Part 1-4Marisol Altobar PalatinoNo ratings yet
- Oracle Apps Quality ModuleDocument17 pagesOracle Apps Quality ModuleSantOsh100% (2)
- Serendipity - A Sociological NoteDocument2 pagesSerendipity - A Sociological NoteAmlan BaruahNo ratings yet
- Handbook of Zen, Mindfulness and Spiritual Health PDFDocument324 pagesHandbook of Zen, Mindfulness and Spiritual Health PDFMatthew Grayson100% (3)
- Project Report Software and Web Development Company: WWW - Dparksolutions.inDocument12 pagesProject Report Software and Web Development Company: WWW - Dparksolutions.inRavi Kiran Rajbhure100% (1)
- Answer Questions Only: Chemical Engineering DeptDocument2 pagesAnswer Questions Only: Chemical Engineering DepthusseinNo ratings yet
- POPULARITY OF CREDIT CARDS ISSUED BY DIFFERENT BANKSDocument25 pagesPOPULARITY OF CREDIT CARDS ISSUED BY DIFFERENT BANKSNaveed Karim Baksh75% (8)
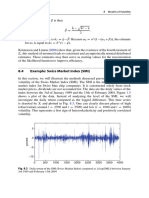
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- FM 5130Document66 pagesFM 5130Aswini Kr KarmakarNo ratings yet
- X RayDocument16 pagesX RayMedical Physics2124No ratings yet
- Getting the Most from Cattle Manure: Proper Application Rates and PracticesDocument4 pagesGetting the Most from Cattle Manure: Proper Application Rates and PracticesRamNocturnalNo ratings yet
- Apps Tables Excel FRMTDocument4 pagesApps Tables Excel FRMTSunil ReddyNo ratings yet
- 1491559890CL 0417 PDFDocument48 pages1491559890CL 0417 PDFCoolerAdsNo ratings yet
- HHG4M - Lifespan Development Textbook Lesson 2Document95 pagesHHG4M - Lifespan Development Textbook Lesson 2Lubomira SucheckiNo ratings yet
- Daily Assessment RecordDocument4 pagesDaily Assessment Recordapi-342236522100% (2)
- Presentation 1Document20 pagesPresentation 1nikitakhanduja1304No ratings yet
- Vincent Ira B. Perez: Barangay Gulod, Calatagan, BatangasDocument3 pagesVincent Ira B. Perez: Barangay Gulod, Calatagan, BatangasJohn Ramsel Boter IINo ratings yet
- Lesson 4Document13 pagesLesson 4Annie Mury SantiagoNo ratings yet
- LNG Vaporizers Using Various Refrigerants As Intermediate FluidDocument15 pagesLNG Vaporizers Using Various Refrigerants As Intermediate FluidFrandhoni UtomoNo ratings yet
- 19 Unpriced BOM, Project & Manpower Plan, CompliancesDocument324 pages19 Unpriced BOM, Project & Manpower Plan, CompliancesAbhay MishraNo ratings yet
- SHORT STORY Manhood by John Wain - Lindsay RossouwDocument17 pagesSHORT STORY Manhood by John Wain - Lindsay RossouwPrincess67% (3)
- 2 Druid StreetDocument4 pages2 Druid StreetthamestunnelNo ratings yet
- Final Annotated BibiliographyDocument4 pagesFinal Annotated Bibiliographyapi-491166748No ratings yet
- True False Survey FinalDocument2 pagesTrue False Survey Finalwayan_agustianaNo ratings yet