You might also like
- MATH1231-1241-Calculus-Notes-2020T1 (2020 - 10 - 19 10 - 35 - 29 UTC)Document213 pagesMATH1231-1241-Calculus-Notes-2020T1 (2020 - 10 - 19 10 - 35 - 29 UTC)shirleyNo ratings yet
- Applied Computational Fluid Dynamics Techniques: An Introduction Based on Finite Element MethodsFrom EverandApplied Computational Fluid Dynamics Techniques: An Introduction Based on Finite Element MethodsNo ratings yet
- Delphi Legacy Projects - Strategies and Survival GuideDocument484 pagesDelphi Legacy Projects - Strategies and Survival GuideAndry100% (3)
- Provided Before Each Number.: Catubig, Northern SamarDocument3 pagesProvided Before Each Number.: Catubig, Northern SamarJoanne Pauline Tenedero - RuelaNo ratings yet
- MSC Thesis JRMoraal Wind Turbine Foundation ModelDocument97 pagesMSC Thesis JRMoraal Wind Turbine Foundation ModelOlesea NesterencoNo ratings yet
- Text Mining Project ReportDocument27 pagesText Mining Project ReportcidsantNo ratings yet
- Project Report On ATM System PDFDocument22 pagesProject Report On ATM System PDFenockkays90% (21)
- Ge Carescape r860 Ventilator Service Manual PDFDocument5 pagesGe Carescape r860 Ventilator Service Manual PDFMichael Alexandre0% (2)
- The LaTeX Mathematics CompanionDocument78 pagesThe LaTeX Mathematics CompanionNéstor Valles-VillarrealNo ratings yet
- Presentations with LaTeX: Which package, which command, which syntax?From EverandPresentations with LaTeX: Which package, which command, which syntax?No ratings yet
- Email Clustering AlgorithmDocument57 pagesEmail Clustering Algorithmgrepfruit1No ratings yet
- Background Reading - R Tree With ExamplesDocument24 pagesBackground Reading - R Tree With ExamplesNithinNo ratings yet
- V, Saouma Fem I PDFDocument304 pagesV, Saouma Fem I PDFAlfonso Moya MondéjarNo ratings yet
- Star2: Statics of Beam Structures 2 Order TheoryDocument55 pagesStar2: Statics of Beam Structures 2 Order TheoryChris LumyNo ratings yet
- Comparing Unsupervised Word Embedding Models To Build A Large Scale Text Recommendation SystemDocument39 pagesComparing Unsupervised Word Embedding Models To Build A Large Scale Text Recommendation SystemJesus Jair Alarcón ArcaNo ratings yet
- Report Group-8Document16 pagesReport Group-8ravi2587ranjanNo ratings yet
- Spreadtab enDocument27 pagesSpreadtab enRiccardo Della SalaNo ratings yet
- Improving Performance For CSMA CA Based PDFDocument145 pagesImproving Performance For CSMA CA Based PDFsarathchandra motatiNo ratings yet
- RC 25186Document83 pagesRC 25186thumarushikNo ratings yet
- Plot 3 DDocument317 pagesPlot 3 DBrunoNo ratings yet
- Algebraic Topology For Data Scientists Michael S. Postol. PH.DDocument322 pagesAlgebraic Topology For Data Scientists Michael S. Postol. PH.DJacek WalczakNo ratings yet
- Pairing NethealandDocument72 pagesPairing NethealandJack HongNo ratings yet
- Relational Theory Database Technology (DBTECO601) : Thomas Devine Thomas - Devine@lyit - Ie November 15, 2007Document49 pagesRelational Theory Database Technology (DBTECO601) : Thomas Devine Thomas - Devine@lyit - Ie November 15, 2007Moni MoniNo ratings yet
- Muen ReportDocument99 pagesMuen Report宛俊No ratings yet
- Precourse TUM Management & Technology 2019: Dr. Michael Kaplan Winter Term 2019/20Document8 pagesPrecourse TUM Management & Technology 2019: Dr. Michael Kaplan Winter Term 2019/20Patty ChacónNo ratings yet
- Milvus OverviewDocument53 pagesMilvus OverviewBENSALEM Mohamed AbderrahmaneNo ratings yet
- ?UTF-8?Q?CSE 20-98 Lindberg So CC 88derberg - PDF?Document100 pages?UTF-8?Q?CSE 20-98 Lindberg So CC 88derberg - PDF?Fran MoralesNo ratings yet
- Final Report - Time Serie Prediction For Bank Account BalancesDocument78 pagesFinal Report - Time Serie Prediction For Bank Account BalancesAvanti HargudeNo ratings yet
- Beautybook enDocument22 pagesBeautybook enmir.cazasu27No ratings yet
- Pandoc Crossref NewDocument11 pagesPandoc Crossref NewSreenath M. G.No ratings yet
- Petri JavaDocument29 pagesPetri Javabrqj6nNo ratings yet
- Querying RDBMS Using Natural LanguageDocument105 pagesQuerying RDBMS Using Natural LanguageAnant ChhajwaniNo ratings yet
- WST 212: Introduction To Data ScienceDocument67 pagesWST 212: Introduction To Data Science9bnthmhgwdNo ratings yet
- Oxford SC2 Transcribed NotesDocument42 pagesOxford SC2 Transcribed NotesisometricatNo ratings yet
- Iso 26262 Scadavenian BestDocument82 pagesIso 26262 Scadavenian BestENERGYSTORAGE CALIFORNIANo ratings yet
- Analyzing Common Structures inDocument85 pagesAnalyzing Common Structures inshayanaliyannezhadNo ratings yet
- Gupta Thesis 2017Document91 pagesGupta Thesis 2017Lap Ngo DoanNo ratings yet
- ProofsDocument29 pagesProofsDaniel M. OliveraNo ratings yet
- Computer Science TwoDocument209 pagesComputer Science Two徐海东No ratings yet
- Notes On Data Structures and Algorithms: Dr. Anindita KunduDocument64 pagesNotes On Data Structures and Algorithms: Dr. Anindita KunduPrashansa AgarwalNo ratings yet
- Eth 48401 01Document102 pagesEth 48401 01Arthur NingNo ratings yet
- Discrete Mathematics: Haluk Bingol February 21, 2012Document157 pagesDiscrete Mathematics: Haluk Bingol February 21, 2012Raj vamsi SrigakulamNo ratings yet
- Sofimsha 1Document133 pagesSofimsha 1Chris LumyNo ratings yet
- Deep Learning For Stock Selection Based On High Frequency Price-Volume DataDocument25 pagesDeep Learning For Stock Selection Based On High Frequency Price-Volume DataognjanovicNo ratings yet
- D-Flow FM Technical Reference Manual PDFDocument172 pagesD-Flow FM Technical Reference Manual PDFsyahrul muharamNo ratings yet
- MDP TutorialDocument104 pagesMDP TutorialcasesilvaNo ratings yet
- Groen - MA - EEMCS Thesis 2018Document63 pagesGroen - MA - EEMCS Thesis 2018balla sandyNo ratings yet
- Victor Saouma - Matrix Structural Analysis PDFDocument316 pagesVictor Saouma - Matrix Structural Analysis PDFРостислав ВасилевNo ratings yet
- Tesis RodrigoDocument96 pagesTesis RodrigoGAyalaMNo ratings yet
- The DDS Tutorial: ReleaseDocument35 pagesThe DDS Tutorial: ReleaseRamziNo ratings yet
- Data Management and Query Processing in Semantic Web Databases - CompressDocument273 pagesData Management and Query Processing in Semantic Web Databases - CompressMohammad HarisNo ratings yet
- Cake CuttingDocument47 pagesCake CuttingBing XiaNo ratings yet
- Riesco Verdejo Par Skel TRDocument89 pagesRiesco Verdejo Par Skel TRnaabarcaNo ratings yet
- Twisted PDFDocument487 pagesTwisted PDFOlubodun AgbalayaNo ratings yet
- Mirza ThesisDocument163 pagesMirza ThesisKunal AroraNo ratings yet
- Bachelor ThesisDocument25 pagesBachelor ThesisAnkit GhoshNo ratings yet
- Market NotesDocument904 pagesMarket NotesinspagintNo ratings yet
- FulltextDocument62 pagesFulltextNguyen Van ToanNo ratings yet
- 09-1171A-C Developer Guide Problem Solving HandbookDocument112 pages09-1171A-C Developer Guide Problem Solving HandbookThe Observation Inc.No ratings yet
- Graphs and Viz With RDocument119 pagesGraphs and Viz With RsalnasuNo ratings yet
- A FEM Alghorithm in OctaveDocument39 pagesA FEM Alghorithm in OctaveLuis GibbsNo ratings yet
- Chapter 2: Building Abstractions With ObjectsDocument55 pagesChapter 2: Building Abstractions With ObjectsTech StuffNo ratings yet
- The Colin de Verdiere Number of A Graph PDFDocument49 pagesThe Colin de Verdiere Number of A Graph PDFYASSIN ZELMATNo ratings yet
- Nocoug v2Document50 pagesNocoug v2emedinillaNo ratings yet
- Implementacion de Algoritmos Cuanticos para PrincipiantesDocument94 pagesImplementacion de Algoritmos Cuanticos para PrincipiantesBrandon Matthew Ruvalcaba CardenasNo ratings yet
- Group6 Human Resources PayRoll ProjectPlan-1.2Document41 pagesGroup6 Human Resources PayRoll ProjectPlan-1.2Sơn NguyenNo ratings yet
- Student Netiquette: BACC 107 September 3, 2020Document26 pagesStudent Netiquette: BACC 107 September 3, 2020Rhealyn Joyce CabatbatNo ratings yet
- AccomplishmentDocument2 pagesAccomplishmentRamonito TanNo ratings yet
- Tugas Diskusi Kelompok 6Document4 pagesTugas Diskusi Kelompok 6febiyolandaputripaneNo ratings yet
- Middle East Technical University Mechanical Engineering Department ME 485 CFD With Finite Volume Method Spring 2017 (Dr. Sert)Document34 pagesMiddle East Technical University Mechanical Engineering Department ME 485 CFD With Finite Volume Method Spring 2017 (Dr. Sert)Kwanchai Choicharoen100% (1)
- DIYDachshundDocument15 pagesDIYDachshundClaudia LopezNo ratings yet
- 2. ACTIA - AES.2英文版Document2 pages2. ACTIA - AES.2英文版osama tariqNo ratings yet
- Tutorial ADINADocument16 pagesTutorial ADINAMartin YarlequeNo ratings yet
- Keyloggers in Cybersecurity Education: 2. An Overview of KeyloggingDocument7 pagesKeyloggers in Cybersecurity Education: 2. An Overview of KeyloggingSuresh MENo ratings yet
- Alphabet Letter Builder BLOGDocument16 pagesAlphabet Letter Builder BLOGChan QiongNo ratings yet
- Hardware Software Co-Design: BITS PilaniDocument38 pagesHardware Software Co-Design: BITS Pilaniswapna revuriNo ratings yet
- Lecture 7 Sequential Logic 2020Document65 pagesLecture 7 Sequential Logic 2020Noam ShemlaNo ratings yet
- ZLAN1003/ZLAN104 3/ZLAN1043N User Manual: Single Chip Serial Port To TCP/IP SolutionDocument79 pagesZLAN1003/ZLAN104 3/ZLAN1043N User Manual: Single Chip Serial Port To TCP/IP SolutionnadimNo ratings yet
- KWIC Software ArchitectureDocument17 pagesKWIC Software ArchitectureKaze NikahNo ratings yet
- Heterogeneous System Copy For An Sap Netweaver BW and Sap ... System Copy For An Sap Netweaver Bw..Document3 pagesHeterogeneous System Copy For An Sap Netweaver BW and Sap ... System Copy For An Sap Netweaver Bw..Kanigiri NareshNo ratings yet
- Inbound 9059189774699210232Document322 pagesInbound 9059189774699210232laily gista septiyaNo ratings yet
- Assignment #5: Name: Yasir Mehmood Roll No: 18272720-048 MBA-IV Section BDocument5 pagesAssignment #5: Name: Yasir Mehmood Roll No: 18272720-048 MBA-IV Section BYasir MehmoodNo ratings yet
- Etsi Ttcn3 TutorialDocument32 pagesEtsi Ttcn3 TutorialSaumyadip GhoshNo ratings yet
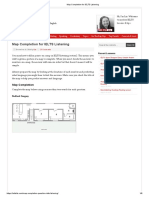
- Map Completion For IELTS Listening PDFDocument6 pagesMap Completion For IELTS Listening PDFSanjay SahooNo ratings yet
- Birla Institute of Technology-Mesra, Ranchi NEWCOURSE STRUCTURE - To Be Effective From Academic Session 2018 - 19Document3 pagesBirla Institute of Technology-Mesra, Ranchi NEWCOURSE STRUCTURE - To Be Effective From Academic Session 2018 - 19shatabdi mukherjeeNo ratings yet
- 04 - Interfaces Protocols (PDF Word)Document12 pages04 - Interfaces Protocols (PDF Word)Ashish NokiaNo ratings yet
- Number SystemDocument23 pagesNumber SystemDeepa PachhaiNo ratings yet
- HCM WS Organizations Data Common Diagnostic Test - CorrectDocument10 pagesHCM WS Organizations Data Common Diagnostic Test - CorrectMurali TNo ratings yet
- AD9951 AppnoteDocument6 pagesAD9951 Appnoteshabaz_yousaf2734No ratings yet
- Interface Python With MySQLDocument28 pagesInterface Python With MySQLDhiraj Kumar BiswalNo ratings yet