You might also like
- UGC NET STATS: MEASURES OF CENTRAL TENDENCY AND BASIC CONCEPTSDocument48 pagesUGC NET STATS: MEASURES OF CENTRAL TENDENCY AND BASIC CONCEPTSSyedAsifMehdiNo ratings yet
- G2 4-G2 4M-2014Document58 pagesG2 4-G2 4M-2014Peter Lopez67% (3)
- Firelights PDFDocument2 pagesFirelights PDFEFG EFGNo ratings yet
- Service Manual KTM Adventure 1190Document226 pagesService Manual KTM Adventure 1190Tim BlockxNo ratings yet
- Simple Regression Analysis: Key Concepts ExplainedDocument51 pagesSimple Regression Analysis: Key Concepts ExplainedGrace GecomoNo ratings yet
- AnovaDocument55 pagesAnovaFiona Fernandes67% (3)
- SMMDDocument10 pagesSMMDAnuj AgarwalNo ratings yet
- xg01 Koso Kent Introl PDFDocument22 pagesxg01 Koso Kent Introl PDFhaidinuNo ratings yet
- Likelihood Ratio TestDocument6 pagesLikelihood Ratio TestBernard OkpeNo ratings yet
- 1 s2.0 S136403211930423X MainDocument13 pages1 s2.0 S136403211930423X MainWei WangNo ratings yet
- Cai, Sun - Unknown - Part I Large-Scale Multiple Testing Chapter 1 A Compound Decision-Theoretic Approach To Large-Scale Multiple TesDocument43 pagesCai, Sun - Unknown - Part I Large-Scale Multiple Testing Chapter 1 A Compound Decision-Theoretic Approach To Large-Scale Multiple TesYoungHee GoNo ratings yet
- Models For Count Data With Overdispersion: 1 Extra-Poisson VariationDocument7 pagesModels For Count Data With Overdispersion: 1 Extra-Poisson VariationMilkha SinghNo ratings yet
- Econometrics 1 Cumulative Final Study GuideDocument35 pagesEconometrics 1 Cumulative Final Study GuideIsabelleDwightNo ratings yet
- A Step by Step Guide To Bi-Gaussian Disjunctive KrigingDocument15 pagesA Step by Step Guide To Bi-Gaussian Disjunctive KrigingThyago OliveiraNo ratings yet
- 1 s2.0 S0378375806002205 MainDocument10 pages1 s2.0 S0378375806002205 Mainjps.mathematicsNo ratings yet
- 214 CHPT 11Document18 pages214 CHPT 11Daniel RandolphNo ratings yet
- P-Values are Random VariablesDocument5 pagesP-Values are Random Variablesaskazy007No ratings yet
- Multivariate Statistical Analysis: The Multivariate Normal DistributionDocument13 pagesMultivariate Statistical Analysis: The Multivariate Normal DistributionGenesis Carrillo GranizoNo ratings yet
- App Econ - Week6 PDFDocument6 pagesApp Econ - Week6 PDFFil DeVinNo ratings yet
- WEEK-2-modularDocument19 pagesWEEK-2-modularjhonrexmartirez9No ratings yet
- PS5 SolutionDocument5 pagesPS5 SolutionGuido GilliNo ratings yet
- Exact Sample Size Determination For Binomial ExperimentsDocument11 pagesExact Sample Size Determination For Binomial ExperimentsjelilNo ratings yet
- Britten Jones Non Linear (Quadratic) VaRDocument28 pagesBritten Jones Non Linear (Quadratic) VaRNisarg KamdarNo ratings yet
- Understanding Multicollinearity in Regression ModelsDocument10 pagesUnderstanding Multicollinearity in Regression ModelsZeinm KhenNo ratings yet
- Cointegracion MacKinnon, - Et - Al - 1996 PDFDocument26 pagesCointegracion MacKinnon, - Et - Al - 1996 PDFAndy HernandezNo ratings yet
- Analyze Statistical Tests and ConceptsDocument8 pagesAnalyze Statistical Tests and ConceptsDr.Srinivasan KannappanNo ratings yet
- ES 209 Lecture Notes Week 14Document22 pagesES 209 Lecture Notes Week 14Janna Ann JurialNo ratings yet
- Jahanshahloo2006 (Topsis)Document10 pagesJahanshahloo2006 (Topsis)André MicoskyNo ratings yet
- Validate Linear Models with New Statistical TestDocument23 pagesValidate Linear Models with New Statistical TestYam CrackerNo ratings yet
- Z-Test of DifferenceDocument5 pagesZ-Test of DifferenceMarvin Yebes ArceNo ratings yet
- Statistics and Numerical Methods - RekhaDocument13 pagesStatistics and Numerical Methods - Rekhabhagyagr8No ratings yet
- 3.6: General Hypothesis TestsDocument6 pages3.6: General Hypothesis Testssound05No ratings yet
- Statistical Treatment of Data, Data Interpretation, and ReliabilityDocument6 pagesStatistical Treatment of Data, Data Interpretation, and Reliabilitydraindrop8606No ratings yet
- Propagación de Cifras SignificativasDocument5 pagesPropagación de Cifras SignificativasThiago OsorioNo ratings yet
- Topics To Know For Exams: CHAPTER 1 (1.1 - 1.4) - Summarizing Data Graphically and NumericallyDocument6 pagesTopics To Know For Exams: CHAPTER 1 (1.1 - 1.4) - Summarizing Data Graphically and NumericallyStevenNo ratings yet
- Readings For Lecture 5,: S S N N S NDocument16 pagesReadings For Lecture 5,: S S N N S NSara BayedNo ratings yet
- Tests For Two ProportionsDocument29 pagesTests For Two ProportionsdvenumohanNo ratings yet
- 10.1007@s10479 018 2857 4Document18 pages10.1007@s10479 018 2857 4Juan MercadoNo ratings yet
- Sample Questions: EXAM 2Document6 pagesSample Questions: EXAM 2Pulkit PrajapatiNo ratings yet
- Chapter 9 Multiple Regression Analysis: The Problem of InferenceDocument10 pagesChapter 9 Multiple Regression Analysis: The Problem of InferenceAmirul Hakim Nor AzmanNo ratings yet
- MIT14 382S17 Lec6Document26 pagesMIT14 382S17 Lec6jarod_kyleNo ratings yet
- Two-Way Heteroscedastic ANOVA When The Number of Levels Is LargeDocument26 pagesTwo-Way Heteroscedastic ANOVA When The Number of Levels Is LargeKipas PinkNo ratings yet
- qm2 NotesDocument9 pagesqm2 NotesdeltathebestNo ratings yet
- Problem Set 1Document3 pagesProblem Set 1dxd032No ratings yet
- Standard Error of RDocument20 pagesStandard Error of Raukie999No ratings yet
- Non-Parametric_testDocument12 pagesNon-Parametric_testhansdeep479No ratings yet
- Linear Regression Notes and PitfallsDocument5 pagesLinear Regression Notes and PitfallsPete Jacopo Belbo CayaNo ratings yet
- Large Sample TestDocument7 pagesLarge Sample Testrahul khunti100% (1)
- Two-Sample T-Tests Using Effect SizeDocument11 pagesTwo-Sample T-Tests Using Effect SizescjofyWFawlroa2r06YFVabfbajNo ratings yet
- Assignment 1Document6 pagesAssignment 1Marko MakobiriNo ratings yet
- Confidence Intervals For The Difference Between Two ProportionsDocument17 pagesConfidence Intervals For The Difference Between Two ProportionsscjofyWFawlroa2r06YFVabfbajNo ratings yet
- Chi-Square As A Test For Comparing VarianceDocument9 pagesChi-Square As A Test For Comparing VarianceSairaj MudhirajNo ratings yet
- Effective Measures of Multivariate Scatter and Linear DependenceDocument14 pagesEffective Measures of Multivariate Scatter and Linear DependenceMarcelaNo ratings yet
- SERP2003001Document20 pagesSERP2003001Saragih HansNo ratings yet
- Residual Analysis: There Will Be No Class Meeting On Tuesday, November 26Document5 pagesResidual Analysis: There Will Be No Class Meeting On Tuesday, November 26StarrySky16No ratings yet
- Trazo de Carreteras PDFDocument16 pagesTrazo de Carreteras PDFantonio15No ratings yet
- Unit-V 3Document36 pagesUnit-V 3Ash KNo ratings yet
- Chi-Square Test: Advance StatisticsDocument26 pagesChi-Square Test: Advance StatisticsRobert Carl GarciaNo ratings yet
- Sampling Theory and Hypothesis TestingDocument21 pagesSampling Theory and Hypothesis TestingMahendranath RamakrishnanNo ratings yet
- A Crash Course in Statistics - HandoutsDocument46 pagesA Crash Course in Statistics - HandoutsNida Sohail ChaudharyNo ratings yet
- 2012 Mean ComparisonDocument35 pages2012 Mean Comparison3rlangNo ratings yet
- Flex MG ArchDocument44 pagesFlex MG ArchsdfasdfkksfjNo ratings yet
- SEIR Epidemic Model AnalysisDocument8 pagesSEIR Epidemic Model AnalysisDaniel AscuntarNo ratings yet
- A Defect-Correction Method For The Incompressible Navier-Stokes EquationsDocument19 pagesA Defect-Correction Method For The Incompressible Navier-Stokes EquationsTaher CheginiNo ratings yet
- 4 Ways to Improve Your Strategic ThinkingDocument3 pages4 Ways to Improve Your Strategic ThinkingJyothi MallyaNo ratings yet
- What Are Peripheral Devices??Document57 pagesWhat Are Peripheral Devices??Mainard LacsomNo ratings yet
- CBSE Class 8 Mathematics Ptactice WorksheetDocument1 pageCBSE Class 8 Mathematics Ptactice WorksheetArchi SamantaraNo ratings yet
- Python Module 7 AFV Core-Data-StructureDocument48 pagesPython Module 7 AFV Core-Data-StructureLeonardo FernandesNo ratings yet
- GW - Energy Storage Solutions - Brochure-ENDocument24 pagesGW - Energy Storage Solutions - Brochure-ENjhtdtNo ratings yet
- sr20 Switchingsystems080222Document20 pagessr20 Switchingsystems080222Daniel BholahNo ratings yet
- (332-345) IE - ElectiveDocument14 pages(332-345) IE - Electivegangadharan tharumarNo ratings yet
- Seaskills Maritime Academy: Purchase OrderDocument8 pagesSeaskills Maritime Academy: Purchase OrderSELVA GANESHNo ratings yet
- Macquarie Capital Cover LetterDocument1 pageMacquarie Capital Cover LetterDylan AdrianNo ratings yet
- Journal of Ethnopharmacology: Trilobata (L.) Pruski Flower in RatsDocument7 pagesJournal of Ethnopharmacology: Trilobata (L.) Pruski Flower in RatsHeriansyah S1 FarmasiNo ratings yet
- Unit 9 The Post Office: Grammar: Omission of Relative PronounsDocument5 pagesUnit 9 The Post Office: Grammar: Omission of Relative PronounsTrung Lê TríNo ratings yet
- Architecture Student QuestionsDocument3 pagesArchitecture Student QuestionsMelissa SerranoNo ratings yet
- Teltonika Networks CatalogueDocument40 pagesTeltonika Networks CatalogueazizNo ratings yet
- The Making of BuckshotDocument13 pagesThe Making of BuckshotDominicNo ratings yet
- Alternative Price List Usa DypartsDocument20 pagesAlternative Price List Usa DypartsMarcel BaqueNo ratings yet
- GCC Lab ManualDocument61 pagesGCC Lab ManualMadhu BalaNo ratings yet
- Designing An LLC ResonantDocument30 pagesDesigning An LLC Resonant劉品賢No ratings yet
- Manually Installing IBM Spectrum Scale For Object StorageDocument2 pagesManually Installing IBM Spectrum Scale For Object StoragesohaileoNo ratings yet
- Lesson 2.1Document16 pagesLesson 2.1Jeremie Manimbao OrdinarioNo ratings yet
- Upper Limb OrthosisDocument47 pagesUpper Limb OrthosisPraneethaNo ratings yet
- IMSP 21 Operational Control EMSDocument3 pagesIMSP 21 Operational Control EMSEvonne LeeNo ratings yet
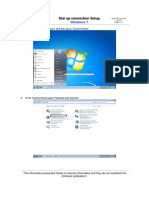
- Windows 7 Dial-Up Connection Setup GuideDocument7 pagesWindows 7 Dial-Up Connection Setup GuideMikeNo ratings yet
- How To Read An EKG Strip LectureDocument221 pagesHow To Read An EKG Strip LectureDemuel Dee L. BertoNo ratings yet
- Eike Batista BiographyDocument9 pagesEike Batista BiographyGEORGEGeekNo ratings yet
- Creating and Using Virtual DPUsDocument20 pagesCreating and Using Virtual DPUsDeepak Gupta100% (1)