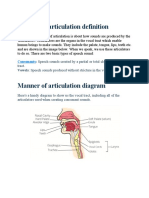
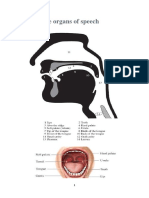
You might also like
- The Mystery of the Seven Vowels: In Theory and PracticeFrom EverandThe Mystery of the Seven Vowels: In Theory and PracticeRating: 4 out of 5 stars4/5 (9)
- Fonetica Resumen Primer ParcialDocument11 pagesFonetica Resumen Primer Parcialemilse RodríguezNo ratings yet
- Summary GimsonDocument6 pagesSummary GimsonsgambelluribeiroNo ratings yet
- Linguistics - Unit 3Document5 pagesLinguistics - Unit 3Appas SahaNo ratings yet
- English ConsonantsDocument28 pagesEnglish ConsonantsIzzati AzmanNo ratings yet
- Linguistics 2Document45 pagesLinguistics 2Bani AbdullaNo ratings yet
- Organ of Speech Airstream Mechanism (Kel 1)Document7 pagesOrgan of Speech Airstream Mechanism (Kel 1)Vera AsifaNo ratings yet
- Phonetics NotesDocument5 pagesPhonetics NotesYaya CasablancaNo ratings yet
- Phonetic and PhonologyDocument22 pagesPhonetic and PhonologyloganzxNo ratings yet
- Phonology SeptemberDocument10 pagesPhonology SeptemberaladeobashinaNo ratings yet
- Nama: Yudha Septa Dias P NIM: 12203193120 Mata Kuliah: English Phonology Kelas: Tbi 1BDocument9 pagesNama: Yudha Septa Dias P NIM: 12203193120 Mata Kuliah: English Phonology Kelas: Tbi 1BInayah RizkyNo ratings yet
- ngữ âm vị họcDocument5 pagesngữ âm vị họcThảo Min'ssNo ratings yet
- Phonetics Phonology Full NotesDocument24 pagesPhonetics Phonology Full NotesMuralitharan Nagalingam100% (4)
- Topic 8: Phonological System of The English Language Ii: Consonants. Phonetic SymbolsDocument8 pagesTopic 8: Phonological System of The English Language Ii: Consonants. Phonetic SymbolsLaura Irina Lara SánchezNo ratings yet
- Name: Eka Uchi M.Sirait NPM:2101030052 Subject: Phonology LecturerDocument3 pagesName: Eka Uchi M.Sirait NPM:2101030052 Subject: Phonology LecturerMaretta SiadariNo ratings yet
- Manner of Articulation DefinitionDocument9 pagesManner of Articulation DefinitionAdmin LinguizNo ratings yet
- Institute of New Khmer: Subject: Applied Linguistics Teach By: Lecturer Prepared By: Group 6 Student NameDocument27 pagesInstitute of New Khmer: Subject: Applied Linguistics Teach By: Lecturer Prepared By: Group 6 Student NameHafiz ShoaibNo ratings yet
- Phonetics Vocal Tract Phonation: Egressive IngressiveDocument5 pagesPhonetics Vocal Tract Phonation: Egressive IngressiveNamani SanjayNo ratings yet
- Manner of ArticulationDocument12 pagesManner of ArticulationMhonz Limbing100% (1)
- English Phonetics and PhonologyDocument31 pagesEnglish Phonetics and PhonologyIzzati AzmanNo ratings yet
- Chapter 4 & 5 - Special TopicsDocument15 pagesChapter 4 & 5 - Special TopicsBearish PaleroNo ratings yet
- Eng 323 Lect 3Document6 pagesEng 323 Lect 3maryjames ikebunaNo ratings yet
- Ibn Tofail University LevelDocument23 pagesIbn Tofail University LevelImad Es SaouabiNo ratings yet
- Chapter 2 PhonologyDocument13 pagesChapter 2 PhonologyEsther Ponmalar CharlesNo ratings yet
- The Organs of SpeechDocument6 pagesThe Organs of SpeechAnonymous ToHeyBoEbX100% (1)
- TOPIC 8. The Phonological System of The English LanguageDocument9 pagesTOPIC 8. The Phonological System of The English LanguageCristinaNo ratings yet
- Teori PhoneticsDocument11 pagesTeori PhoneticsSri Wahyu NingsihNo ratings yet
- Handout Chapter 2 Phonetics Spring Semester 2023Document11 pagesHandout Chapter 2 Phonetics Spring Semester 2023mhmddhwyb8No ratings yet
- Language "Clothes"Document39 pagesLanguage "Clothes"Milagros BenitezNo ratings yet
- The Human Speech ApparatusDocument10 pagesThe Human Speech ApparatusRunato Basanes100% (1)
- Phonetics and Phonology PDFDocument62 pagesPhonetics and Phonology PDFCarlos Rojas CamachoNo ratings yet
- A Course in Phonetics by Peter Ladefoged PDFDocument15 pagesA Course in Phonetics by Peter Ladefoged PDFPralay SutradharNo ratings yet
- Makalah Phonology Kelompok 2Document11 pagesMakalah Phonology Kelompok 2meldianto manugalaNo ratings yet
- Tema 7:sistema Fonologico de La Lengua Inglesa I: Las VocalesDocument25 pagesTema 7:sistema Fonologico de La Lengua Inglesa I: Las VocalesFrancisco Navarro MartinezNo ratings yet
- Unit 9Document7 pagesUnit 9Gemma Cañadas JimenezNo ratings yet
- PDFDocument30 pagesPDFLogi CheminotNo ratings yet
- 1 Branches of Phonetics and Organs of Speech 2021Document31 pages1 Branches of Phonetics and Organs of Speech 2021Dalia A Al AfifNo ratings yet
- Consonant SoundsDocument8 pagesConsonant SoundsKhairul Nizam HamzahNo ratings yet
- Speech Production A. Standard CompetencyDocument7 pagesSpeech Production A. Standard CompetencyShofa Lanima HalimNo ratings yet
- Materi 88-94 AkhirDocument8 pagesMateri 88-94 AkhirInayah RizkyNo ratings yet
- Book EnglishphoneticsDocument94 pagesBook EnglishphoneticsmanishNo ratings yet
- Manner of Articulation: ExercisesDocument1 pageManner of Articulation: ExercisesHomero Apeña CarranzaNo ratings yet
- Consonants and Allophonic VariationDocument33 pagesConsonants and Allophonic VariationAgustina AcostaNo ratings yet
- Manner of ArticulationDocument15 pagesManner of ArticulationAMEEER HAMZANo ratings yet
- The Human Speech ApparatusDocument2 pagesThe Human Speech ApparatusClou Clou Peña100% (2)
- Human Speech OrgansDocument5 pagesHuman Speech OrgansLouise anasthasya altheaNo ratings yet
- النظام الصوتي المرحلة الاولى الملف الكاملDocument48 pagesالنظام الصوتي المرحلة الاولى الملف الكاملjyx9sbghgvNo ratings yet
- Sounds ClassificationDocument4 pagesSounds ClassificationSantiago Etcheverry FeelyNo ratings yet
- Articulatory PhoneticsDocument5 pagesArticulatory Phoneticsابو محمدNo ratings yet
- Topic 8 PDFDocument15 pagesTopic 8 PDFDave MoonNo ratings yet
- Linguistic Homework Sumany Chapter 6 and 7Document10 pagesLinguistic Homework Sumany Chapter 6 and 7Sindy Blandon RiosNo ratings yet
- Phonetics and PhonologyDocument21 pagesPhonetics and PhonologyNasir Hasan AshikNo ratings yet
- الثاني صوتDocument13 pagesالثاني صوتg7j85hvb52No ratings yet
- A. Articulatory Phinetic: 1. Air Stream MechanismDocument3 pagesA. Articulatory Phinetic: 1. Air Stream MechanismIis Nur'AzijahNo ratings yet
- Puntos Parcial Fonetica-1Document4 pagesPuntos Parcial Fonetica-1Ax AbregúNo ratings yet
- Lesson 4 Consonants1Document8 pagesLesson 4 Consonants1Lounis MustaphaNo ratings yet
- U9 Cavity FeaturesDocument3 pagesU9 Cavity Featureslornanyaga4No ratings yet
- Lecture 3 English ConsonantsDocument21 pagesLecture 3 English Consonantsshah khalidNo ratings yet
- Phonetic ADocument28 pagesPhonetic ANina BandalacNo ratings yet
- We Use Frequency Adverbs To Describe How Often Something Happens. We Use Them With The Present Simple TenseDocument6 pagesWe Use Frequency Adverbs To Describe How Often Something Happens. We Use Them With The Present Simple TenseBrunoNo ratings yet
- AdverbsDocument16 pagesAdverbswhite_spirit42No ratings yet
- Humility LessonsDocument20 pagesHumility Lessonsheidi cernaNo ratings yet
- Evaluare Verbe Modale Clasa A ViiiaDocument2 pagesEvaluare Verbe Modale Clasa A ViiiamaunasimonaNo ratings yet
- 9 C Fce 13 UnitsDocument2 pages9 C Fce 13 UnitsCosmescu Mario FlorinNo ratings yet
- 3rd English Question BankDocument7 pages3rd English Question BankRaam sivaNo ratings yet
- Gesture and Private Speech in Second Language AcquisitionDocument23 pagesGesture and Private Speech in Second Language AcquisitionDaniela AlvesNo ratings yet
- Unit 05 - Inside The BrainDocument20 pagesUnit 05 - Inside The BrainPhạm BảoNo ratings yet
- Root Words and PrefixesDocument29 pagesRoot Words and PrefixesSamia Mohamed HelmyNo ratings yet
- Taller Ingles #2Document3 pagesTaller Ingles #2Juan Andres Quintero ClaroNo ratings yet
- Nguyễn Quang Thắng - NGỮ ÂM TEST 1Document2 pagesNguyễn Quang Thắng - NGỮ ÂM TEST 1Quang Thắng NguyễnNo ratings yet
- End of Term 2 Higher TestDocument3 pagesEnd of Term 2 Higher TestAna BuricNo ratings yet
- Week V N°2 - Separata - Starter Level (Fiorella)Document2 pagesWeek V N°2 - Separata - Starter Level (Fiorella)Marco Antonio Porras PajueloNo ratings yet
- Lesson Plan CLS A 6-ADocument4 pagesLesson Plan CLS A 6-AGABRIELA SANDUNo ratings yet
- Impact of Repeated Reading Strategy in The Development of Reading Fluency of The Struggling Readers in Grade 7Document8 pagesImpact of Repeated Reading Strategy in The Development of Reading Fluency of The Struggling Readers in Grade 7International Journal of Innovative Science and Research TechnologyNo ratings yet
- FUTURE TENSESDocument27 pagesFUTURE TENSESdaliaNo ratings yet
- مكتبة نور Common Irregular Verbs 3Document5 pagesمكتبة نور Common Irregular Verbs 3Abdullah AlhassaniNo ratings yet
- Second Grading Period: Module # 3Document9 pagesSecond Grading Period: Module # 3Chill BoiNo ratings yet
- Awl 4-6Document9 pagesAwl 4-6AliNo ratings yet
- Language of PresentationsDocument10 pagesLanguage of PresentationsmarjoseoyanederNo ratings yet
- Kabuliwala by R.N. TagoreDocument9 pagesKabuliwala by R.N. TagoreRiya LaxmiNo ratings yet
- Further Explanation About Reported SpeechesDocument20 pagesFurther Explanation About Reported SpeechesGabriela GustiNo ratings yet
- Pupe 09-10 Worksheet 7 (A) KeyDocument6 pagesPupe 09-10 Worksheet 7 (A) KeywalidNo ratings yet
- صعوبات تعليمية الإنتاج الكتابي ، وطرائق تجاوزها .Document14 pagesصعوبات تعليمية الإنتاج الكتابي ، وطرائق تجاوزها .خديجة خديجةNo ratings yet
- Curriculum Map: English 7 Philippine Literature During The JapaneseDocument2 pagesCurriculum Map: English 7 Philippine Literature During The JapaneseJeff LacasandileNo ratings yet
- New Keystone C: Unit 4, Reading 1 P198-203Document16 pagesNew Keystone C: Unit 4, Reading 1 P198-203Nhật Linh Đào TrầnNo ratings yet
- Reactivate Test Book Answers: Quiz 1Document2 pagesReactivate Test Book Answers: Quiz 1Cota 100067% (3)
- Email Etiquettes Case AnalysisDocument4 pagesEmail Etiquettes Case AnalysisRiya Sharma100% (1)
- Tenses Review Bus 13 Unit 1Document3 pagesTenses Review Bus 13 Unit 1Daniel MartinezNo ratings yet
- Veni, Vidi, Vici !Document21 pagesVeni, Vidi, Vici !Cinzia PateraNo ratings yet
- Learn German with Paul Noble for Beginners – Complete Course: German Made Easy with Your 1 million-best-selling Personal Language CoachFrom EverandLearn German with Paul Noble for Beginners – Complete Course: German Made Easy with Your 1 million-best-selling Personal Language CoachRating: 5 out of 5 stars5/5 (151)
- German Short Stories for Beginners – 5 in 1: Over 500 Dialogues & Short Stories to Learn German in your Car. Have Fun and Grow your Vocabulary with Crazy Effective Language Learning LessonsFrom EverandGerman Short Stories for Beginners – 5 in 1: Over 500 Dialogues & Short Stories to Learn German in your Car. Have Fun and Grow your Vocabulary with Crazy Effective Language Learning LessonsRating: 5 out of 5 stars5/5 (14)
- Learn German: A Comprehensive Guide to Learning German for Beginners, Including Grammar and 2500 Popular PhrasesFrom EverandLearn German: A Comprehensive Guide to Learning German for Beginners, Including Grammar and 2500 Popular PhrasesRating: 5 out of 5 stars5/5 (2)
- Next Steps in German with Paul Noble for Intermediate Learners – Complete Course: German Made Easy with Your 1 million-best-selling Personal Language CoachFrom EverandNext Steps in German with Paul Noble for Intermediate Learners – Complete Course: German Made Easy with Your 1 million-best-selling Personal Language CoachRating: 5 out of 5 stars5/5 (67)
- Learn German - Level 9: Advanced German, Volume 2: Lessons 1-25From EverandLearn German - Level 9: Advanced German, Volume 2: Lessons 1-25Rating: 5 out of 5 stars5/5 (4)
- Enjoyable German Short Stories for Advanced Beginners Learn German With 10 Short Stories for LearnersFrom EverandEnjoyable German Short Stories for Advanced Beginners Learn German With 10 Short Stories for LearnersNo ratings yet
- Reading German for Theological Studies: A Grammar and ReaderFrom EverandReading German for Theological Studies: A Grammar and ReaderNo ratings yet
- Learn German with Paul Noble for Beginners – Part 1: German Made Easy with Your 1 million-best-selling Personal Language CoachFrom EverandLearn German with Paul Noble for Beginners – Part 1: German Made Easy with Your 1 million-best-selling Personal Language CoachRating: 5 out of 5 stars5/5 (64)
- 3-Minute German: Everyday German for BeginnersFrom Everand3-Minute German: Everyday German for BeginnersRating: 4.5 out of 5 stars4.5/5 (11)
- German Short Stories for Beginners: Improve and Expand Your German Vocabulary with 20 Exciting German NovelsFrom EverandGerman Short Stories for Beginners: Improve and Expand Your German Vocabulary with 20 Exciting German NovelsNo ratings yet
- Learn German: Ultimate Guide to Speaking Business German for Beginners (Deluxe Edition)From EverandLearn German: Ultimate Guide to Speaking Business German for Beginners (Deluxe Edition)Rating: 4.5 out of 5 stars4.5/5 (11)
- German Short Stories for Beginners Book 5From EverandGerman Short Stories for Beginners Book 5Rating: 5 out of 5 stars5/5 (7)
- Learn German - Level 1: Introduction to German, Volume 1: Volume 1: Lessons 1-25From EverandLearn German - Level 1: Introduction to German, Volume 1: Volume 1: Lessons 1-25Rating: 5 out of 5 stars5/5 (2)
- The Everything Essential German Book: All You Need to Learn German in No Time!From EverandThe Everything Essential German Book: All You Need to Learn German in No Time!Rating: 4.5 out of 5 stars4.5/5 (5)
- Bite-Sized German in Ten Minutes a Day: Begin Speaking German Immediately with Easy Bite-Sized Lessons During Your Down Time!From EverandBite-Sized German in Ten Minutes a Day: Begin Speaking German Immediately with Easy Bite-Sized Lessons During Your Down Time!Rating: 5 out of 5 stars5/5 (16)
- Learn German! Lerne Englisch! ALICE'S ADVENTURES IN WONDERLAND: In German and EnglishFrom EverandLearn German! Lerne Englisch! ALICE'S ADVENTURES IN WONDERLAND: In German and EnglishRating: 3.5 out of 5 stars3.5/5 (5620)
- German Parallel Audio - Learn German with 501 Random Phrases using Parallel Audio - Volume 2From EverandGerman Parallel Audio - Learn German with 501 Random Phrases using Parallel Audio - Volume 2Rating: 4 out of 5 stars4/5 (4)
- German Parallel Audio: Volume 1: Learn German with 501 Random Phrases using Parallel AudioFrom EverandGerman Parallel Audio: Volume 1: Learn German with 501 Random Phrases using Parallel AudioRating: 4.5 out of 5 stars4.5/5 (10)
- Learn German in Your Car: Learning German for Beginners & Kids Has Never Been Easier Before! Have Fun Whilst Learning Fantastic Exercises for Accurate Pronunciations, Daily Used Phrases and Vocabulary!From EverandLearn German in Your Car: Learning German for Beginners & Kids Has Never Been Easier Before! Have Fun Whilst Learning Fantastic Exercises for Accurate Pronunciations, Daily Used Phrases and Vocabulary!No ratings yet
- 2000 Most Common German Words in Context: Get Fluent & Increase Your German Vocabulary with 2000 German PhrasesFrom Everand2000 Most Common German Words in Context: Get Fluent & Increase Your German Vocabulary with 2000 German PhrasesRating: 4.5 out of 5 stars4.5/5 (8)
- Automatic Fluency® Immediate German Level 1: 5 Hours of Intense German Fluency InstructionFrom EverandAutomatic Fluency® Immediate German Level 1: 5 Hours of Intense German Fluency InstructionRating: 4.5 out of 5 stars4.5/5 (42)
- Intermediate German Short Stories: Learn German Vocabulary and Phrases with Stories (B1/ B2) (German Edition)From EverandIntermediate German Short Stories: Learn German Vocabulary and Phrases with Stories (B1/ B2) (German Edition)Rating: 2.5 out of 5 stars2.5/5 (3)