You might also like
- Databricks Spark Reference ApplicationsDocument37 pagesDatabricks Spark Reference ApplicationsjoseNo ratings yet
- SAP interface programming with RFC and VBA: Edit SAP data with MS AccessFrom EverandSAP interface programming with RFC and VBA: Edit SAP data with MS AccessNo ratings yet
- Interview QuestionsDocument4 pagesInterview QuestionsDastagiri SahebNo ratings yet
- Spark Streaming Through Dynamic Batch SizingDocument4 pagesSpark Streaming Through Dynamic Batch SizingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Spark Summit 2013 Spark Streaming Real Time Big Data ProcessingDocument31 pagesSpark Summit 2013 Spark Streaming Real Time Big Data ProcessingjessicapaumierNo ratings yet
- XML Processing Performance: The Promise of XMLDocument6 pagesXML Processing Performance: The Promise of XMLSumeetha PonnamNo ratings yet
- Apache Storm ThesisDocument7 pagesApache Storm Thesisjuliemaypeoria100% (2)
- SamzaDocument10 pagesSamzasanketNo ratings yet
- ETCW03Document3 pagesETCW03Editor IJAERDNo ratings yet
- Bda Unit-4 PDFDocument63 pagesBda Unit-4 PDFHarryNo ratings yet
- Spark Project Report: StreamingDocument22 pagesSpark Project Report: Streamingtestyy testtNo ratings yet
- ComponentsDocument11 pagesComponentsSravya ReddyNo ratings yet
- Filg 8Document631 pagesFilg 8Katraj NawazNo ratings yet
- DataStage Theory PartDocument18 pagesDataStage Theory PartJesse KotaNo ratings yet
- Streaming: Big Data Huawei CourseDocument19 pagesStreaming: Big Data Huawei CourseThiago SiqueiraNo ratings yet
- Abap NotesDocument4 pagesAbap NoteszafadraNo ratings yet
- Unit IiiDocument19 pagesUnit IiikarimunisaNo ratings yet
- ADF+Course+deckDocument88 pagesADF+Course+deckclouditlab9No ratings yet
- Datastage InterviewDocument161 pagesDatastage Interviewmukesh100% (1)
- Different Stages in Data PipelineDocument7 pagesDifferent Stages in Data PipelineSantoshNo ratings yet
- BDA UNIT-2 (Final)Document27 pagesBDA UNIT-2 (Final)Sai HareenNo ratings yet
- Reportnet3 Database Feasibility Study PostgreSQLDocument5 pagesReportnet3 Database Feasibility Study PostgreSQLDimas WelliNo ratings yet
- Calculating Required Network Bandwidth for Redo TransferDocument2 pagesCalculating Required Network Bandwidth for Redo Transferbaraka08No ratings yet
- Apache Spark Ecosystem - Complete Spark Components Guide: 1. ObjectiveDocument11 pagesApache Spark Ecosystem - Complete Spark Components Guide: 1. Objectivedivya kolluriNo ratings yet
- 13 Stream Processing Patterns For Building Streaming and Realtime Applications - My Views of The World and SystemsDocument9 pages13 Stream Processing Patterns For Building Streaming and Realtime Applications - My Views of The World and SystemsudNo ratings yet
- 02 Principles of Parallel Execution and PartitioningDocument23 pages02 Principles of Parallel Execution and PartitioningChristopher WilliamsNo ratings yet
- Learning Real-Time Processing With Spark Streaming - Sample ChapterDocument30 pagesLearning Real-Time Processing With Spark Streaming - Sample ChapterPackt PublishingNo ratings yet
- Postgresql Tuning Guide: Postgresql Architecture: Key TakeawaysDocument8 pagesPostgresql Tuning Guide: Postgresql Architecture: Key TakeawaysTonny KusdarwantoNo ratings yet
- Debug and Development StagesDocument5 pagesDebug and Development StagesAnkur VirmaniNo ratings yet
- SnowflakeDocument43 pagesSnowflakeRick VNo ratings yet
- Splunk and MapReduceDocument8 pagesSplunk and MapReduceMotokNo ratings yet
- Practical Assignment - :: Distributed Data Processing With Apache SparkDocument3 pagesPractical Assignment - :: Distributed Data Processing With Apache SparkTeshome MulugetaNo ratings yet
- AWR INTERPRETATIONDocument17 pagesAWR INTERPRETATIONPraveen KumarNo ratings yet
- Thesis Apache SparkDocument4 pagesThesis Apache Sparkiapesmiig100% (2)
- Databricks - Spark StreamingDocument55 pagesDatabricks - Spark StreamingSlavimirVesićNo ratings yet
- Structured Streaming Programming Guide - Spark 3.4.0 DocumentationDocument1 pageStructured Streaming Programming Guide - Spark 3.4.0 Documentationhamza amjadNo ratings yet
- Data Stage PDFDocument37 pagesData Stage PDFpappujaiswalNo ratings yet
- Ques.: Describe The Features of Client and Server. Explain Its Pros and Cons?Document5 pagesQues.: Describe The Features of Client and Server. Explain Its Pros and Cons?Brenda CoxNo ratings yet
- How To Read Awr ReportDocument22 pagesHow To Read Awr Reportsoma3nathNo ratings yet
- Data Stage ArchitectureDocument9 pagesData Stage Architecturejbk111No ratings yet
- Informatica QuestionsDocument31 pagesInformatica QuestionsGoutham TalluriNo ratings yet
- CCF Usage ManualDocument8 pagesCCF Usage ManualAshutosh KumarNo ratings yet
- Ebin - Pub Hands On Guide To Apache Spark 3 Build Scalable Computing Engines For Batch and Stream Data Processing 1nbsped 1484293797 9781484293799Document307 pagesEbin - Pub Hands On Guide To Apache Spark 3 Build Scalable Computing Engines For Batch and Stream Data Processing 1nbsped 1484293797 9781484293799mr.satya.chauhanNo ratings yet
- SQL Chache POPLDocument21 pagesSQL Chache POPLDavidNo ratings yet
- SAP NetWeaver Executables GuideDocument9 pagesSAP NetWeaver Executables GuideJesus Garcia CastroNo ratings yet
- Spark SQLDocument24 pagesSpark SQLJaswanth ChowdarysNo ratings yet
- TakingInterviwDocument15 pagesTakingInterviwA MISHRANo ratings yet
- SpdocDocument36 pagesSpdocgaros3No ratings yet
- Lambda - A Modern Big Data Architecture 5 - 12 PDFDocument128 pagesLambda - A Modern Big Data Architecture 5 - 12 PDFHarnoor SachdevaNo ratings yet
- AWS Data LakeDocument13 pagesAWS Data LakeSuvankar ChakrabortyNo ratings yet
- Kafka As A Storage SystemDocument6 pagesKafka As A Storage SystemDiullei GomesNo ratings yet
- Performance TuningDocument3 pagesPerformance TuningHari Prasad ReddyNo ratings yet
- BDCDocument58 pagesBDCStrider_17100% (1)
- Informatica PerformanceDocument4 pagesInformatica PerformanceVikas SinhaNo ratings yet
- Datastage Stage DescDocument8 pagesDatastage Stage DescsravankenshiNo ratings yet
- Apache Spark Streaming PresentationDocument28 pagesApache Spark Streaming PresentationSlavimirVesić100% (1)
- Answers 4Document91 pagesAnswers 4Miguel Angel HernandezNo ratings yet
- Ops$Sapservice) With Very Few PrivilegesDocument5 pagesOps$Sapservice) With Very Few PrivilegesMarri MahipalNo ratings yet
- JETIR2202408Document7 pagesJETIR2202408Raghu BNo ratings yet
- First Submission Copia de Git Commands DocumentationDocument6 pagesFirst Submission Copia de Git Commands DocumentationlarzuwaNo ratings yet
- WP Cumulocity Iot Azure Iot SolutionDocument17 pagesWP Cumulocity Iot Azure Iot SolutionÄbdêlrãhmãñHâshêshNo ratings yet
- MyResume-fazli 2014Document5 pagesMyResume-fazli 2014fazli3036No ratings yet
- Design and implementation of pass 1 of a two-pass macroprocessorDocument3 pagesDesign and implementation of pass 1 of a two-pass macroprocessorutkarsha shiroleNo ratings yet
- DS-1200KI/DS-1006KI Keyboard: User ManualDocument38 pagesDS-1200KI/DS-1006KI Keyboard: User ManualAydee ArangurenNo ratings yet
- Microsoft Azure Certification Training CourseDocument8 pagesMicrosoft Azure Certification Training Coursevenkatesan palaniappanNo ratings yet
- SQL Notes by Apna CollegeDocument29 pagesSQL Notes by Apna CollegeSiddhant Kumar100% (2)
- Syllabus - DS600Document13 pagesSyllabus - DS600vigneshNo ratings yet
- White Paper c11 741490 16 35Document20 pagesWhite Paper c11 741490 16 35Mohamed Aly SowNo ratings yet
- Dit 503 Project - ProposalDocument11 pagesDit 503 Project - ProposalTimothy lilNo ratings yet
- Ros Lab 6Document17 pagesRos Lab 6Souad BouzianeNo ratings yet
- Nuschool Citrix VDI Pre-Check-v3.0Document4 pagesNuschool Citrix VDI Pre-Check-v3.0Jaico DictaanNo ratings yet
- Cisco Systems IOS XR 161522Document282 pagesCisco Systems IOS XR 161522Moisés MiguelNo ratings yet
- Prepared By: Ms. Priti RumaoDocument38 pagesPrepared By: Ms. Priti RumaoPriti RumaoNo ratings yet
- Basics of IDoc For SAP ConsultantsDocument6 pagesBasics of IDoc For SAP ConsultantsSumonta MallikNo ratings yet
- Module 02 Implement Azure Functions 1Document34 pagesModule 02 Implement Azure Functions 1Xulfee100% (1)
- Sap On Cloud PlatformDocument2 pagesSap On Cloud PlatformQueen ValleNo ratings yet
- MoodleDocument66 pagesMoodleNithya SridharNo ratings yet
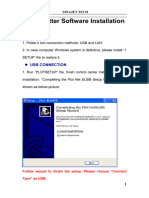
- Plotter Software InstallationDocument10 pagesPlotter Software InstallationmonsalvesolNo ratings yet
- Shreshth's ResumeDocument1 pageShreshth's ResumeRoshan PrasadNo ratings yet
- SoftwareDefinedNetworking - A Comprehensive Survey (01-31)Document31 pagesSoftwareDefinedNetworking - A Comprehensive Survey (01-31)Brissa CoralTorresNo ratings yet
- CIMCON Overview Jan 2020 DiscoveryDocument16 pagesCIMCON Overview Jan 2020 DiscoveryIpoty JuniorNo ratings yet
- Lenovo-Thinkpad-Sl400 Pegatron Rocky40 50 Uma Rev1-0-Pdf.41793Document94 pagesLenovo-Thinkpad-Sl400 Pegatron Rocky40 50 Uma Rev1-0-Pdf.41793mbah bejoNo ratings yet
- Introduction to Computers and C++ Programming ChapterDocument38 pagesIntroduction to Computers and C++ Programming Chapterken lacedaNo ratings yet
- Unit3-Routing Protocols - EditedDocument124 pagesUnit3-Routing Protocols - Editedsangeetha sheelaNo ratings yet
- #Include #Include Void Main (CLRSCRDocument36 pages#Include #Include Void Main (CLRSCRmeerashekarNo ratings yet
- DBMS 5th Sem - LabManualDocument63 pagesDBMS 5th Sem - LabManualsriharshapatilsbNo ratings yet
- Digital Signal Processing & Filter Design ConceptDocument49 pagesDigital Signal Processing & Filter Design ConceptMahmudul HasanNo ratings yet
- Docker Fundamentals 2022Document33 pagesDocker Fundamentals 2022Ananth Kumar MocharlaNo ratings yet