You might also like
- Azure Databricks Course Slide DeckDocument169 pagesAzure Databricks Course Slide DeckRaghunath Sai100% (2)
- Spark Training - JavaDocument8 pagesSpark Training - JavaPavan KumarNo ratings yet
- Azure Databricks Course Slide Deck V4Document308 pagesAzure Databricks Course Slide Deck V4ravikumar lanka100% (2)
- The Definitive Guide to Azure Data Engineering: Modern ELT, DevOps, and Analytics on the Azure Cloud PlatformFrom EverandThe Definitive Guide to Azure Data Engineering: Modern ELT, DevOps, and Analytics on the Azure Cloud PlatformNo ratings yet
- Machine Learning in SparkDocument26 pagesMachine Learning in SparkbrocktheboneNo ratings yet
- Azure DatabricksDocument69 pagesAzure Databrickssr_saurab851175% (4)
- 8 Steps For A Developer To Learn Apache Spark and Delta Lake PDFDocument35 pages8 Steps For A Developer To Learn Apache Spark and Delta Lake PDFjnnvacNo ratings yet
- Spark SQLDocument34 pagesSpark SQLRoxana Godoy AstudilloNo ratings yet
- Evaluative Summary On Databricks' Value PropositionsDocument2 pagesEvaluative Summary On Databricks' Value PropositionsSaad SadiqNo ratings yet
- Apache Spark Theory by ArshDocument4 pagesApache Spark Theory by ArshFaraz AkhtarNo ratings yet
- Apache Spark Primer 170303Document8 pagesApache Spark Primer 170303selivesNo ratings yet
- Spark DevopsDocument301 pagesSpark Devopstopimaster0% (1)
- Apache Spark Ecosystem - Complete Spark Components Guide: 1. ObjectiveDocument11 pagesApache Spark Ecosystem - Complete Spark Components Guide: 1. Objectivedivya kolluriNo ratings yet
- ReseDocument3 pagesReseAsif KhanNo ratings yet
- Data Engineer with Extensive AWS and Azure ExperienceDocument3 pagesData Engineer with Extensive AWS and Azure ExperienceKaushalNo ratings yet
- 09 Programming Hadoop - Spark, R and PigDocument80 pages09 Programming Hadoop - Spark, R and PigNeeraj GargNo ratings yet
- Jayasree Yedlapally Data Architecture Engineering ProfileDocument5 pagesJayasree Yedlapally Data Architecture Engineering ProfileShantha GopaalNo ratings yet
- Cassandra Expert Anujah Runwal ResumeDocument4 pagesCassandra Expert Anujah Runwal ResumeHimanshu RunwalNo ratings yet
- Databricks On AWS 01 Getting Started Apache Spark SlidesDocument29 pagesDatabricks On AWS 01 Getting Started Apache Spark SlidesMohil Joshi100% (1)
- Databricks: Building and Operating A Big Data Service Based On Apache SparkDocument32 pagesDatabricks: Building and Operating A Big Data Service Based On Apache SparkSaravanan1234567No ratings yet
- Spark Vs Hadoop Features SparkDocument9 pagesSpark Vs Hadoop Features SparkconsaniaNo ratings yet
- Real Time Analytics With Spark and KafkaDocument53 pagesReal Time Analytics With Spark and KafkasulogoNo ratings yet
- Spart Part 2Document44 pagesSpart Part 2Aleena Nasir100% (1)
- Optimizing Modern Data LakesDocument2 pagesOptimizing Modern Data Lakesanoopiit2012No ratings yet
- Apache Spark Interview Questions and Answers PDFDocument31 pagesApache Spark Interview Questions and Answers PDFZyad AhmedNo ratings yet
- Cisco CML Corporate Edition DSDocument5 pagesCisco CML Corporate Edition DSjayNo ratings yet
- Lecture #12.1 - Apache Spark - Production ScenariosDocument29 pagesLecture #12.1 - Apache Spark - Production ScenariosSumit KhaitanNo ratings yet
- Srilakshmi M ResumeDocument2 pagesSrilakshmi M ResumeSrilakshmi MNo ratings yet
- Apache Spark ComponentsDocument4 pagesApache Spark ComponentsnitinluckyNo ratings yet
- Data Engineer with experience in Azure, Snowflake, AWS seeking new opportunitiesDocument2 pagesData Engineer with experience in Azure, Snowflake, AWS seeking new opportunitiesannur keerthanaNo ratings yet
- Apache SparkDocument6 pagesApache SparkTamNo ratings yet
- Sparks QL Sig Mod 2015Document12 pagesSparks QL Sig Mod 2015aloknsinghNo ratings yet
- BDA GTU Study Material Presentations Unit-6 03102021061221PMDocument23 pagesBDA GTU Study Material Presentations Unit-6 03102021061221PMRi PatelNo ratings yet
- Shaik MahajabinDocument4 pagesShaik Mahajabinsoumyaranjan panigrahyNo ratings yet
- DBR 7.x & Spark 3.x Features GuideDocument86 pagesDBR 7.x & Spark 3.x Features Guidefranc.peralta6200No ratings yet
- unit 4 spark cassendraDocument41 pagesunit 4 spark cassendradownloadjain123No ratings yet
- Spark SQL - Relational Data Processing in SparkDocument12 pagesSpark SQL - Relational Data Processing in SparkAna IlieNo ratings yet
- Spark-RddDocument15 pagesSpark-RddK Anantha KrishnanNo ratings yet
- Pyspark Modules&packages RDDDocument9 pagesPyspark Modules&packages RDDklogeswaran.itNo ratings yet
- Evan - Big Data ArchitectDocument5 pagesEvan - Big Data ArchitectMadhav GarikapatiNo ratings yet
- Dong Xiao's Resume - Full Stack .NET Developer with Strong Embedded and Cloud SkillsDocument5 pagesDong Xiao's Resume - Full Stack .NET Developer with Strong Embedded and Cloud SkillsJoven CamusNo ratings yet
- Introducing Sparklyr - WebinarDocument13 pagesIntroducing Sparklyr - WebinarhaimkichikNo ratings yet
- Modern Analytics Academy - Data ModelingDocument12 pagesModern Analytics Academy - Data ModelingHernan LabastieNo ratings yet
- Apache Spark Analytics Made SimpleDocument76 pagesApache Spark Analytics Made SimpleNaceur ElNo ratings yet
- Vinay Kumar Data EngineerDocument8 pagesVinay Kumar Data Engineerkevin711588No ratings yet
- Apache Spark Analytics Made Simple PDFDocument76 pagesApache Spark Analytics Made Simple PDFprerit_tNo ratings yet
- Unit-5 SparkDocument20 pagesUnit-5 SparkSivaNo ratings yet
- Chirag Verma Resume 3Document1 pageChirag Verma Resume 3Atul ParasharNo ratings yet
- Apr24 HallB 1605 GIDS2015 SparkBigData PrajodVettiyattilDocument48 pagesApr24 HallB 1605 GIDS2015 SparkBigData PrajodVettiyattilAmrAhmedAbdelFattahNo ratings yet
- Experience Summary: Neelotpaul Roy Data Engineering Manager - Accenture Strategy & Consulting (AI)Document6 pagesExperience Summary: Neelotpaul Roy Data Engineering Manager - Accenture Strategy & Consulting (AI)Sourav BanerjeeNo ratings yet
- Azure Analytics: SynapseDocument251 pagesAzure Analytics: SynapseJames Alberto Martinez100% (4)
- Spark SQLDocument12 pagesSpark SQLvikasNo ratings yet
- Oracle DBA - RAC and SSIS - Power BI - Updated ProfileDocument6 pagesOracle DBA - RAC and SSIS - Power BI - Updated ProfileraamanNo ratings yet
- Deep Learning Models at Scale With Apache Spark: May 31, 2019 Asa SdssDocument50 pagesDeep Learning Models at Scale With Apache Spark: May 31, 2019 Asa SdssjannatNo ratings yet
- Spark: Prepared by Dulari BhattDocument19 pagesSpark: Prepared by Dulari BhattDulari Bosamiya BhattNo ratings yet
- The Data Engineers Guide To Python For SnowflakeDocument15 pagesThe Data Engineers Guide To Python For Snowflakesuman999No ratings yet
- Databricks For The SQL Developer: Gerhard BruecklDocument40 pagesDatabricks For The SQL Developer: Gerhard BruecklTirumalesh ReddyNo ratings yet
- Check List Valve PDFDocument2 pagesCheck List Valve PDFikan100% (1)
- Nikon SMZ 10A DatasheetDocument3 pagesNikon SMZ 10A DatasheetNicholai HelNo ratings yet
- Presentation 5 1Document76 pagesPresentation 5 1Anshul SinghNo ratings yet
- UFO FILES Black Box Ufo SecretsDocument10 pagesUFO FILES Black Box Ufo SecretsNomad XNo ratings yet
- 12th Maths - English Medium PDF DownloadDocument38 pages12th Maths - English Medium PDF DownloadSupriya ReshmaNo ratings yet
- Microorganisms Friend or Foe Part-5Document28 pagesMicroorganisms Friend or Foe Part-5rajesh duaNo ratings yet
- Cegep Linear Algebra ProblemsDocument92 pagesCegep Linear Algebra Problemsham.karimNo ratings yet
- Otimizar Windows 8Document2 pagesOtimizar Windows 8ClaudioManfioNo ratings yet
- PHENOL Coloremetric Tests CHEMetsDocument2 pagesPHENOL Coloremetric Tests CHEMetsmma1976No ratings yet
- Facts About SaturnDocument7 pagesFacts About SaturnGwyn CervantesNo ratings yet
- SCI 7 Q1 WK5 Solutions A LEA TOMASDocument5 pagesSCI 7 Q1 WK5 Solutions A LEA TOMASJoyce CarilloNo ratings yet
- Optimizing Blended Learning with Synchronous and Asynchronous TechnologiesDocument24 pagesOptimizing Blended Learning with Synchronous and Asynchronous TechnologiesAnonymous GOUaH7FNo ratings yet
- Work Text INGE09: Understanding The SelfDocument24 pagesWork Text INGE09: Understanding The SelfFrancis Dave MabborangNo ratings yet
- Math Lesson on Completing PatternsDocument7 pagesMath Lesson on Completing PatternsJazmyne Obra100% (1)
- Strategic ManagementDocument7 pagesStrategic ManagementSarah ShehataNo ratings yet
- Os8 - XCVR 8.7r3 RevaDocument85 pagesOs8 - XCVR 8.7r3 RevaDouglas SantosNo ratings yet
- Autodesk Revit 2014 ContentDocument6 pagesAutodesk Revit 2014 ContentGatot HardiyantoNo ratings yet
- 10.6 Heat Conduction Through Composite WallsDocument35 pages10.6 Heat Conduction Through Composite WallsEngr Muhammad AqibNo ratings yet
- Schmitt Trigger FinalDocument4 pagesSchmitt Trigger Finalsidd14feb92No ratings yet
- 722.6 Transmission Conductor Plate Replacement DIYDocument3 pages722.6 Transmission Conductor Plate Replacement DIYcamaro67427100% (1)
- Lecture 8: Dynamics Characteristics of SCR: Dr. Aadesh Kumar AryaDocument9 pagesLecture 8: Dynamics Characteristics of SCR: Dr. Aadesh Kumar Aryaaadesh kumar aryaNo ratings yet
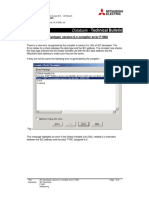
- IEC Developer version 6.n compiler error F1002Document6 pagesIEC Developer version 6.n compiler error F1002AnddyNo ratings yet
- .Design and Development of Motorized Multipurpose MachineDocument3 pages.Design and Development of Motorized Multipurpose MachineANKITA MORENo ratings yet
- Quick Guide in The Preparation of Purchase Request (PR), Purchase Order (PO) and Other Related DocumentsDocument26 pagesQuick Guide in The Preparation of Purchase Request (PR), Purchase Order (PO) and Other Related DocumentsMiguel VasquezNo ratings yet
- Kathryn Stanley ResumeDocument2 pagesKathryn Stanley Resumeapi-503476564No ratings yet
- SARTIKA LESTARI PCR COVID-19 POSITIVEDocument1 pageSARTIKA LESTARI PCR COVID-19 POSITIVEsartika lestariNo ratings yet
- Mil PRF 23699FDocument20 pagesMil PRF 23699FalejandroNo ratings yet
- International Journal of Information Technology, Control and Automation (IJITCA)Document2 pagesInternational Journal of Information Technology, Control and Automation (IJITCA)ijitcajournalNo ratings yet
- Questions Related To Open Channel Flow.Document3 pagesQuestions Related To Open Channel Flow.Mohd AmirNo ratings yet
- Econometrics IIDocument4 pagesEconometrics IINia Hania SolihatNo ratings yet