Department of
Computer Science and Engineering
Title: Implementation of Decision Tree
Classification
Green University of Bangladesh
1 Objective(s)
• To create a training model that can use to predict the class or value of the target variable by learning
simple decision rules inferred from prior data (training data).
• To apply Decision Tree Classification to a real-world predictive modeling problem.
2 Problem analysis
Decision Tree is a Supervised learning technique that can be used for both classification and Regression
problems, but mostly it is preferred for solving Classification problems. It is a tree-structured classifier, where
internal nodes represent the features of a dataset, branches represent the decision rules and each leaf node
represents the outcome.
• In a Decision tree, there are two nodes, which are the Decision Node and Leaf Node. Decision nodes
are used to make any decision and have multiple branches, whereas Leaf nodes are the output of those
decisions and do not contain any further branches.
• The decisions or the test are performed on the basis of features of the given dataset.
• It is a graphical representation for getting all the possible solutions to a problem/decision based on given
conditions.
• It is called a decision tree because, similar to a tree, it starts with the root node, which expands on further
branches and constructs a tree-like structure.
• In order to build a tree, we use the CART algorithm, which stands for Classification and Regression Tree
algorithm.
• A decision tree simply asks a question, and based on the answer (Yes/No), it further split the tree into
subtrees.
Below diagram explains the general structure of a decision tree:
Figure 1: Structure of Decision Tree
© Dept. of Computer Science and Engineering, GUB
Example: Suppose there is a candidate who has a job offer and wants to decide whether he should accept
the offer or Not. So, to solve this problem, the decision tree starts with the root node (Salary attribute by ASM).
The root node splits further into the next decision node (distance from the office) and one leaf node based on
the corresponding labels. The next decision node further gets split into one decision node (Cab facility) and one
leaf node. Finally, the decision node splits into two leaf nodes (Accepted offers and Declined offer). Consider
the below diagram:
Figure 2: Decision Tree
© Dept. of Computer Science and Engineering, GUB
3 Flowchart
Figure 3: Flowchart of Decision Tree
© Dept. of Computer Science and Engineering, GUB
4 Algorithm
Algorithm 1: Decision Tree Algorithm
Input: S, where S = set of classified instances
Output: Decision Tree
/* Algorithm for Decision Tree */
1 Procedure BUILD TREE
2 repeat
3 maxGain = 0
4 splitA = null
5 e = Entropy(Attributes)
6 For all Attributes a in S do
7 gain = InformationGain(a,e)
8 if gain > maxGain then then
9 maxGain = gain
10 splitA = a
11 end
12 end for
13 Partition (S, splitA)
14 until all partitions processed
15 end procedure
5 The Decision Tree Classifier implementation for any sample data
in Python
1 # Importing the libraries
2 import numpy as np
3 import matplotlib.pyplot as plt
4 import pandas as pd
5
6 # Importing the dataset
7 dataset = pd.read_csv(’Social_Network_Ads.csv’)
8 X = dataset.iloc[:, [2,3]].values
9 y = dataset.iloc[:, 4].values
10
11 # Splitting the dataset into the Training set and Test set
12 from sklearn.model_selection import train_test_split
13 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25)
14
15 from sklearn.tree import DecisionTreeClassifier
16 classifier = DecisionTreeClassifier(criterion=’entropy’, random_state = 0,)
17 # criterion = entropy (goal is to reduce entropy, higher info gain and more
homogenious groups after splits)
18 classifier.fit(X_train, y_train)
19
20 #Predicting the Test Set Results
21 y_pred = classifier.predict(X_test)
22 # y_pred is the vector of predictions.
23 # gives prediction for each of the test set observation
24 # using predict method of the DecisionTreeClassifier class (classifier is an
object of the DecisionTreeClassifier class)
25
26 #Making the Confusion Matrix
27 from sklearn.metrics import confusion_matrix
28 # confustion_matrix is a function of the metrics library
© Dept. of Computer Science and Engineering, GUB
29 # difference between class and function (Class is Capitalized, function is
lower−case)
30 cm = confusion_matrix(y_test, y_pred)
31 # Definition : confusion_matrix(y_true, y_pred, labels=None, sample_weight=
None)
32 # using function to compute cofustion matrix
33 #cm=
34 # [62, 6],
35 # [ 3, 29]
36
37 from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
38 disp = ConfusionMatrixDisplay(confusion_matrix=cm,display_labels=classifier.
classes_)
39 disp.plot()
40
41 #Visulaizing the results
42
43 print(X_test)
44
45 print(classifier.predict([[24 , 57000]]))
46
47 print(classifier.predict([[26 , 52000]]))
48
49 print(classifier.predict([[45 , 26000]]))
50
51 from sklearn import tree
52 plt.figure(figsize=(16,16))
53 tree.plot_tree(classifier)
54 plt.show()
55
56 import graphviz
57 dot_data = tree.export_graphviz(classifier, out_file=None,
58 filled=True, rounded=True,
59 feature_names=["Age","Salary"],
60 class_names=["No","Yes"],
61 special_characters=True)
62 graph = graphviz.Source(dot_data)
63 graph
64
65 from sklearn.tree import DecisionTreeClassifier
66 from sklearn.tree import export_text
67 r = export_text(classifier, feature_names=["Age","Salary"])
68 print(r)
69
70 import graphviz
71 dot_data = tree.export_graphviz(classifier, out_file=None)
72 graph = graphviz.Source(dot_data)
73 graph.render("Social_Network_Ads")
© Dept. of Computer Science and Engineering, GUB
6 Input/Output
Output of the program is given below.
Output of Line no. 41: [0].
Output of Line no. 43: [0].
Output of Line no. 45: [1].
7 Discussion & Conclusion
From this experiment we learn about how to visualize the Decision Tree classifier for any sample data.
8 Lab Task (Please implement yourself and show the output to the
instructor)
1. You need to visualize the Decision Tree classifier for this sample data.
Dataset = [[3.393,2.331,0], [3.110,1.786,0], [1.348,3.309,0], [3.540,4.679,0], [2.284,2.892,0], [7.429,4.622,1],
[5.741,3.538,1], [9.176,2.510,1], [7.794,3.429,1], [7.939,0.791,1]]
Then you test your implemented Decision Tree classifier algorithm with the first data i.e.,dataset[0], and
observe the label.
9 Lab Exercise (Submit as a report)
• You need to visualize the Decision Tree classifier for this "Social Network Ads.csv" dataset after using
dummy dataset function.
In this dataset, there have 400 records.
9.1 Problem Analysis
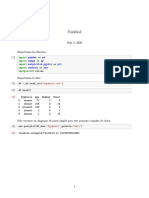
1 # Importing the dataset
2 dataset = pd.read_csv(’Social_Network_Ads.csv’)
3 dataset.head()
The Output is:
Figure 4: Output of the program
© Dept. of Computer Science and Engineering, GUB
1 # Creating Dummies of the dataset
2 dataset = pd.get_dummies(dataset)
3 dataset.head()
The Output is:
Figure 5: Output of the program
10 Policy
Copying from internet, classmate, seniors, or from any other source is strongly prohibited. 100% marks will be
deducted if any such copying is detected.
© Dept. of Computer Science and Engineering, GUB
You might also like
- Types of Pruning TechniquesDocument10 pagesTypes of Pruning TechniquesSmriti PiyushNo ratings yet
- Machine Learning BasicsDocument18 pagesMachine Learning BasicsDaniel CadenaNo ratings yet
- 08 Decision - TreeDocument9 pages08 Decision - TreeGabriel GheorgheNo ratings yet
- Title: Implement Support Vector Machine Classifier: Department of Computer Science and EngineeringDocument5 pagesTitle: Implement Support Vector Machine Classifier: Department of Computer Science and EngineeringreilyshawnNo ratings yet
- Decision Trees in Sklearn Decision Trees in SklearnDocument7 pagesDecision Trees in Sklearn Decision Trees in Sklearnadityaacharya44No ratings yet
- Decision Trees and Random ForestsDocument25 pagesDecision Trees and Random ForestsAlexandra VeresNo ratings yet
- What Is Decision Tree?: ISM Implementation of Decision Tree Submitted By: Sagiruddin Akthar 19mcmc28Document4 pagesWhat Is Decision Tree?: ISM Implementation of Decision Tree Submitted By: Sagiruddin Akthar 19mcmc28Aftab hussainNo ratings yet
- DTEXP5Document8 pagesDTEXP5Sanya SinghNo ratings yet
- Jatin Cu RitambraDocument6 pagesJatin Cu RitambraAmalNo ratings yet
- Machine Learning Random Forest Algorithm - JavatpointDocument14 pagesMachine Learning Random Forest Algorithm - JavatpointRAMZI AzeddineNo ratings yet
- Dmbi Mini Project ReportDocument7 pagesDmbi Mini Project Reportsandesh bhagatNo ratings yet
- 20dit073 Jay Prajapati MLDocument68 pages20dit073 Jay Prajapati MLJay PrajapatiNo ratings yet
- K.Venkat Ratnam 191911412 Class Work 1) Describe The Attribute Selection Measures Used by The ID3 Algorithm To Construct A Decision Tree. A)Document8 pagesK.Venkat Ratnam 191911412 Class Work 1) Describe The Attribute Selection Measures Used by The ID3 Algorithm To Construct A Decision Tree. A)Gnana SekharNo ratings yet
- Image ClassificationDocument18 pagesImage ClassificationDarshna GuptaNo ratings yet
- 17 Ensemble Techniques Problem StatementDocument28 pages17 Ensemble Techniques Problem StatementJadhav A.SNo ratings yet
- Image Annotations Using Machine Learning and FeaturesDocument5 pagesImage Annotations Using Machine Learning and FeaturesIceNFirE GamingNo ratings yet
- St. John College of Engineering and Management, Palghar - MaharashtraDocument11 pagesSt. John College of Engineering and Management, Palghar - MaharashtrapranayNo ratings yet
- Assignment 3_LP1Document13 pagesAssignment 3_LP1bbad070105No ratings yet
- Exercise 7 Submission Group 12Document22 pagesExercise 7 Submission Group 12Mehmet YalçınNo ratings yet
- Project 1Document4 pagesProject 1aqsa yousafNo ratings yet
- Week 7 Laboratory ActivityDocument12 pagesWeek 7 Laboratory ActivityGar NoobNo ratings yet
- MLA Lab 6:-Implementation of Decision TreeDocument16 pagesMLA Lab 6:-Implementation of Decision Treetushar3patil03No ratings yet
- Extreme Gradient BoostingDocument8 pagesExtreme Gradient BoostingSvastitsNo ratings yet
- Assignment 3 Q1Document5 pagesAssignment 3 Q1PratyushNo ratings yet
- Group9 ABA Ensemble ModelDocument5 pagesGroup9 ABA Ensemble ModelReshma MajumderNo ratings yet
- Trees and Forests: Machine Learning With Python CookbookDocument5 pagesTrees and Forests: Machine Learning With Python CookbookJayod RajapakshaNo ratings yet
- Efficient Python tricks for data scientistsDocument20 pagesEfficient Python tricks for data scientistsJavier Velandia100% (1)
- Efficient Python Tricks and Tools For Data Scientists - by Khuyen TranDocument20 pagesEfficient Python Tricks and Tools For Data Scientists - by Khuyen TranKhagenNo ratings yet
- Introduction To Decision Tree: Gini IndexDocument15 pagesIntroduction To Decision Tree: Gini IndexMUhammad WaqasNo ratings yet
- Scikit - Notes MLDocument12 pagesScikit - Notes MLVulli Leela Venkata Phanindra100% (1)
- Introduction to Decision TreesDocument15 pagesIntroduction to Decision TreesMUhammad WaqasNo ratings yet
- "I C U N N ": Mage Lassification Sing Eural EtworksDocument15 pages"I C U N N ": Mage Lassification Sing Eural Etworksbabloo veluvoluNo ratings yet
- R Unit 4th and 5thDocument17 pagesR Unit 4th and 5thArshad BegNo ratings yet
- Charmi Shah 20bcp299 Lab2Document7 pagesCharmi Shah 20bcp299 Lab2Princy100% (1)
- Assignment 1Document2 pagesAssignment 1Arnav YadavNo ratings yet
- ML 1Document20 pagesML 1Adwait RaichNo ratings yet
- Machine Learning Decision Tree ProjectDocument12 pagesMachine Learning Decision Tree ProjectAshishJhaNo ratings yet
- A Detailed Analysis of The Supervised Machine Learning AlgorithmsDocument5 pagesA Detailed Analysis of The Supervised Machine Learning AlgorithmsNIET Journal of Engineering & Technology(NIETJET)No ratings yet
- TD2345Document3 pagesTD2345ashitaka667No ratings yet
- ML Model Paper 3 SolutionDocument22 pagesML Model Paper 3 SolutionRoger kujurNo ratings yet
- Assign 3Document5 pagesAssign 3RanaNo ratings yet
- K-means Clustering & Decision Tree ClassificationDocument16 pagesK-means Clustering & Decision Tree ClassificationMofi GoharNo ratings yet
- DWDM Unit-3: What Is Classification? What Is Prediction?Document12 pagesDWDM Unit-3: What Is Classification? What Is Prediction?Sai Venkat GudlaNo ratings yet
- Student Name: Gaurav Raut University ID: 2038584: 6CS012 Workshop 4Document48 pagesStudent Name: Gaurav Raut University ID: 2038584: 6CS012 Workshop 4Gaurav RautNo ratings yet
- TreesDocument203 pagesTreesKato StratocasterNo ratings yet
- Decision Tree (Autosaved)Document14 pagesDecision Tree (Autosaved)Bhardwaj DiwakarNo ratings yet
- Homework 2: CS 178: Machine Learning: Spring 2020Document3 pagesHomework 2: CS 178: Machine Learning: Spring 2020Jonathan NguyenNo ratings yet
- Models For Machine Learning: M. Tim JonesDocument10 pagesModels For Machine Learning: M. Tim JonesShanti GuruNo ratings yet
- Advanced Recommender Systems with PythonDocument13 pagesAdvanced Recommender Systems with PythonFabian HafnerNo ratings yet
- PRACTICAL5Document23 pagesPRACTICAL5thundergamerz403No ratings yet
- DA Exam PaperDocument6 pagesDA Exam PapercubililyNo ratings yet
- Introduction To Python and Computer Programming 1704298503Document44 pagesIntroduction To Python and Computer Programming 1704298503el.tico.138623No ratings yet
- ArbolesRF UNIDocument3 pagesArbolesRF UNIALISON ELIZABETH HUAPAYA CAYCHONo ratings yet
- Classification Algorithms IDocument14 pagesClassification Algorithms IJayod RajapakshaNo ratings yet
- Matrix Chain MultiplicationDocument20 pagesMatrix Chain MultiplicationHarsh Tibrewal100% (1)
- CSL0777 L26Document33 pagesCSL0777 L26Konkobo Ulrich ArthurNo ratings yet
- 41 j48 Naive Bayes WekaDocument5 pages41 j48 Naive Bayes WekapraveennallavellyNo ratings yet
- Lab Guide-AI-powered Smart Site Selection V1Document15 pagesLab Guide-AI-powered Smart Site Selection V1Patricia ContrerasNo ratings yet
- Decision Tree Model for Diabetes Classification Using Scikit-LearnDocument9 pagesDecision Tree Model for Diabetes Classification Using Scikit-LearnsudeepvmenonNo ratings yet
- Active and Emerging Methodologies For Ubiquitous Education Potentials of Flipped Learning and GamificationDocument11 pagesActive and Emerging Methodologies For Ubiquitous Education Potentials of Flipped Learning and GamificationreilyshawnNo ratings yet
- 8 DevDocument2 pages8 DevreilyshawnNo ratings yet
- 9 DevDocument1 page9 DevreilyshawnNo ratings yet
- As - Bride Copy Final a (2)Document4 pagesAs - Bride Copy Final a (2)reilyshawnNo ratings yet
- 9 DevDocument1 page9 DevreilyshawnNo ratings yet
- 8 DevDocument2 pages8 DevreilyshawnNo ratings yet
- 11th Biology BookDocument150 pages11th Biology BookreilyshawnNo ratings yet
- 11th Biology BookDocument150 pages11th Biology BookreilyshawnNo ratings yet
- 8 DevDocument2 pages8 DevreilyshawnNo ratings yet
- A Framework To Evaluate The Interoperability of Information SystemsDocument13 pagesA Framework To Evaluate The Interoperability of Information SystemsreilyshawnNo ratings yet
- Chapter 1Document24 pagesChapter 1reilyshawnNo ratings yet
- Kepuasan PenggunaDocument11 pagesKepuasan PenggunaAsropiAsropiNo ratings yet
- Annex ADocument2 pagesAnnex AreilyshawnNo ratings yet
- Chapter 1Document24 pagesChapter 1reilyshawnNo ratings yet
- Chapter 1Document24 pagesChapter 1reilyshawnNo ratings yet
- Ex04 ExDocument3 pagesEx04 ExreilyshawnNo ratings yet
- Chloropene Rubber-CRDocument9 pagesChloropene Rubber-CRreilyshawnNo ratings yet
- Class 11 Biology NotesDocument150 pagesClass 11 Biology NotesreilyshawnNo ratings yet
- Synthetic Rubber Lec-1 - 2Document51 pagesSynthetic Rubber Lec-1 - 2reilyshawnNo ratings yet
- EPDMDocument13 pagesEPDMreilyshawnNo ratings yet
- Brillouin Zone and Tight-Binding Model of 2D CrystalsDocument2 pagesBrillouin Zone and Tight-Binding Model of 2D CrystalsAlfred MishiNo ratings yet
- Matrix COSEC Face Recognition V1R1 PresentationDocument44 pagesMatrix COSEC Face Recognition V1R1 PresentationreilyshawnNo ratings yet
- Nitrile rubber-NBRDocument16 pagesNitrile rubber-NBRreilyshawnNo ratings yet
- Calendar 2024 TimelineDocument26 pagesCalendar 2024 TimelineMario VizcainoNo ratings yet
- Chem218 Essay 6Document4 pagesChem218 Essay 6reilyshawnNo ratings yet
- Butyl Rubber-IIRDocument26 pagesButyl Rubber-IIRreilyshawnNo ratings yet
- Butadiene Rubber-BRDocument20 pagesButadiene Rubber-BRreilyshawnNo ratings yet
- Matrix COSEC TAM PresentationDocument90 pagesMatrix COSEC TAM PresentationreilyshawnNo ratings yet
- Chem218 HW 6Document5 pagesChem218 HW 6reilyshawnNo ratings yet
- CHEM218 Questions 7Document4 pagesCHEM218 Questions 7reilyshawnNo ratings yet
- FortiOS-7.2.0-New Features Guide PDFDocument523 pagesFortiOS-7.2.0-New Features Guide PDFOzgur SENERNo ratings yet
- Windows Returns Wrong IP Address As Source IPDocument3 pagesWindows Returns Wrong IP Address As Source IP廖道恩No ratings yet
- Splunk 5.0 InstallationDocument102 pagesSplunk 5.0 InstallationArunkumar KumaresanNo ratings yet
- KT-10 Quick User Guide v2Document4 pagesKT-10 Quick User Guide v2back2denaliNo ratings yet
- Scope of MBA-PGDM in Business AnalyticsDocument8 pagesScope of MBA-PGDM in Business AnalyticsRachna MishraNo ratings yet
- Amax Security System Corp. Price List: Picture ModelDocument57 pagesAmax Security System Corp. Price List: Picture ModelJing AbionNo ratings yet
- CATIA V5 LICENSING GUIDEDocument40 pagesCATIA V5 LICENSING GUIDEspawaskaNo ratings yet
- Application Form UPSRLM Dec 18 Block ManagerDocument2 pagesApplication Form UPSRLM Dec 18 Block ManagerAnurag SinghNo ratings yet
- L T P/ S SW/F W Total Credit UnitsDocument4 pagesL T P/ S SW/F W Total Credit UnitsRamuNo ratings yet
- Documentation - XML Form Generator Form DefinitionsDocument8 pagesDocumentation - XML Form Generator Form DefinitionsAnderson MiquelinoNo ratings yet
- ABAP On HANA Interview QuestionsDocument21 pagesABAP On HANA Interview Questionschetanp100% (1)
- JMA-9800 Instruction ManualDocument372 pagesJMA-9800 Instruction ManualMorseunited100% (1)
- OB Pack Ship Manual SLAM ACW Beginner Sortable SJI NetworkDocument17 pagesOB Pack Ship Manual SLAM ACW Beginner Sortable SJI NetworkJohn ManleyNo ratings yet
- XEROX CentreWare WebDocument4 pagesXEROX CentreWare WebMariaNo ratings yet
- Introduction to MicroprocessorsDocument15 pagesIntroduction to MicroprocessorsKrishna GuragaiNo ratings yet
- 1Z0-133 Oracle Weblogic Server 12C: Administration IDocument34 pages1Z0-133 Oracle Weblogic Server 12C: Administration IAddiNo ratings yet
- WWW Hinditechguru Com PDFDocument11 pagesWWW Hinditechguru Com PDFsdshn9No ratings yet
- Database Programming With SQL 3-2: Sorting Rows Practice ActivitiesDocument5 pagesDatabase Programming With SQL 3-2: Sorting Rows Practice ActivitiesandreivladNo ratings yet
- Resume Antonio+cucco+fiore+2016 PDFDocument2 pagesResume Antonio+cucco+fiore+2016 PDFFraNo ratings yet
- Mayank RajputDocument2 pagesMayank Rajputmayank rajputNo ratings yet
- AP-08000-0134 List of Users and Groups Created After Installing The DeltaV SoftwareDocument18 pagesAP-08000-0134 List of Users and Groups Created After Installing The DeltaV SoftwareSergio Suarez100% (1)
- IBM Security Verify Privilege Level 2 Quiz Attempt ReviewDocument9 pagesIBM Security Verify Privilege Level 2 Quiz Attempt ReviewBBMNo ratings yet
- Manual Programacion Zmax LevitonDocument40 pagesManual Programacion Zmax LevitonjuanNo ratings yet
- BRKACI-2642-Layer 3 OutsDocument100 pagesBRKACI-2642-Layer 3 OutsSandroNo ratings yet
- Legato Storage Manager: Administrator's GuideDocument146 pagesLegato Storage Manager: Administrator's GuideIstván StahlNo ratings yet
- DX DiagDocument30 pagesDX DiagLeni TumanggorNo ratings yet
- Dell Precision Tower 3000 Series 3620 Spec SheetDocument4 pagesDell Precision Tower 3000 Series 3620 Spec SheetBTENo ratings yet
- OS Worksheet From Past PapersDocument7 pagesOS Worksheet From Past PapersMUHAMMAD RAMZANNo ratings yet
- Introduction To Shell ScriptingDocument21 pagesIntroduction To Shell ScriptingteteststssttsstsNo ratings yet
- Class IX - IT - TE - IIDocument3 pagesClass IX - IT - TE - IIHarean RakkshadNo ratings yet