You might also like
- Testing Two Independent Samples - With Minitab Procedures)Document67 pagesTesting Two Independent Samples - With Minitab Procedures)Hey its meNo ratings yet
- Z Test and T TestDocument7 pagesZ Test and T TestTharhanee MuniandyNo ratings yet
- Hypothesis HandoutsDocument17 pagesHypothesis HandoutsReyson PlasabasNo ratings yet
- 123 T F Z Chi Test 2Document5 pages123 T F Z Chi Test 2izzyguyNo ratings yet
- Chapter 9 Hypothesis Testing Two PopulationDocument29 pagesChapter 9 Hypothesis Testing Two PopulationsrhNo ratings yet
- Hypothesis Testing With T Tests Edited 1Document31 pagesHypothesis Testing With T Tests Edited 1Katharine MalaitNo ratings yet
- Chapter 9 Introduction To The T StatisticDocument32 pagesChapter 9 Introduction To The T StatisticdeNo ratings yet
- The t Distribution for Small Sample StatisticsDocument25 pagesThe t Distribution for Small Sample StatisticsJamhur StNo ratings yet
- Notes On Hypothesis TestingDocument3 pagesNotes On Hypothesis TestingMeghraj SapkotaNo ratings yet
- False - Choosing Random Individuals Who Pass by Yields A Random Sample False - Probability Predicts What Kind of PopulationDocument5 pagesFalse - Choosing Random Individuals Who Pass by Yields A Random Sample False - Probability Predicts What Kind of Populationpiepie2No ratings yet
- Probability and Statistics: Hypothesis TestingDocument26 pagesProbability and Statistics: Hypothesis TestingNguyễn Linh ChiNo ratings yet
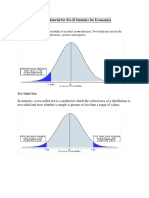
- Study Material For BA-II Statistics For Economics: One Tailed TestDocument9 pagesStudy Material For BA-II Statistics For Economics: One Tailed TestC.s TanyaNo ratings yet
- Advanced Statistics Hypothesis TestingDocument42 pagesAdvanced Statistics Hypothesis TestingShermaine CachoNo ratings yet
- Inferential Statistic IIDocument61 pagesInferential Statistic IIThiviyashiniNo ratings yet
- Central Limit TheoremDocument9 pagesCentral Limit TheoremEian InganNo ratings yet
- Hypothesis Testing for MeansDocument20 pagesHypothesis Testing for MeansSAIRITHISH SNo ratings yet
- "T" Test: DR - Shovan Padhy DM1 Yr (Senior Resident) Dept. of CP & T NIMS, HyderabadDocument20 pages"T" Test: DR - Shovan Padhy DM1 Yr (Senior Resident) Dept. of CP & T NIMS, HyderabadPundaleek KalloliNo ratings yet
- CH 35 Statistical TreatmentDocument28 pagesCH 35 Statistical Treatmentmebajar05No ratings yet
- Small Sample Tests - HandoutDocument22 pagesSmall Sample Tests - HandoutAnant KhandelwalNo ratings yet
- Tests of Hypothesis: Statistical SignificanceDocument49 pagesTests of Hypothesis: Statistical SignificanceJeff Andrian Pariente100% (1)
- Statisticsprobability11 q4 Week2 v4Document10 pagesStatisticsprobability11 q4 Week2 v4Sheryn CredoNo ratings yet
- Testing Hypotheses: Two-Sample Tests: Statistics For Management Levin and RubinDocument29 pagesTesting Hypotheses: Two-Sample Tests: Statistics For Management Levin and RubinBalamurali BalasingamNo ratings yet
- Sampling Distributions and TestsDocument31 pagesSampling Distributions and TestsdaarshiniNo ratings yet
- Introduction To Hypothesis Testing Purpose: Goodson/ 3360hyp 1Document5 pagesIntroduction To Hypothesis Testing Purpose: Goodson/ 3360hyp 1norvin_tolineroNo ratings yet
- 12.probstat - Ch12-Tes Hipotesis 2Document45 pages12.probstat - Ch12-Tes Hipotesis 2misterNo ratings yet
- Understanding the t-Test in 38 CharactersDocument5 pagesUnderstanding the t-Test in 38 CharactersMeenalochini kannanNo ratings yet
- Testing HypothesisDocument9 pagesTesting HypothesisUsama IqbalNo ratings yet
- Forms of Test StatisticsDocument16 pagesForms of Test StatisticsRayezeus Jaiden Del RosarioNo ratings yet
- Sample and Sampling Procedure: PopulationDocument21 pagesSample and Sampling Procedure: Populationsumeet bhardwajNo ratings yet
- Testing of HypothesisDocument19 pagesTesting of HypothesisAbhinav SinghNo ratings yet
- Introduction to T-test IDocument33 pagesIntroduction to T-test Iamedeuce lyatuuNo ratings yet
- Forms of Test StatisticDocument31 pagesForms of Test StatisticJackielou TrongcosoNo ratings yet
- Assignment Updated 101Document24 pagesAssignment Updated 101Lovely Posion100% (1)
- Estimation and HypothesisDocument32 pagesEstimation and HypothesisAtul KashyapNo ratings yet
- Paired samples t-test: Salespersons' weekly sales before and after training courseDocument22 pagesPaired samples t-test: Salespersons' weekly sales before and after training courseSami Un BashirNo ratings yet
- Flipped Notes 9 Applications of Testing HypothesisDocument27 pagesFlipped Notes 9 Applications of Testing HypothesisJoemar SubongNo ratings yet
- TtestDocument16 pagesTtestKarthik BalajiNo ratings yet
- Psych Stats ReviewerDocument16 pagesPsych Stats ReviewerReycee AcepcionNo ratings yet
- One-Sample t Tests using Homework Set II DataDocument22 pagesOne-Sample t Tests using Homework Set II DataJyoti ShahiNo ratings yet
- T-Test of Two Sample MeansDocument23 pagesT-Test of Two Sample MeansZyrill MachaNo ratings yet
- Hypothesis Test for a Mean GuideDocument5 pagesHypothesis Test for a Mean GuideBobbyNicholsNo ratings yet
- Week 11: Sampling DistributionDocument9 pagesWeek 11: Sampling DistributionRoan MaldecirNo ratings yet
- Types of T-Tests: Test Purpose ExampleDocument5 pagesTypes of T-Tests: Test Purpose Exampleshahzaf50% (2)
- Two Sample T-Test StatologyDocument5 pagesTwo Sample T-Test StatologyMahek RawatNo ratings yet
- Testing of Hypothesis: 1 Steps For SolutionDocument8 pagesTesting of Hypothesis: 1 Steps For SolutionAaron MillsNo ratings yet
- Hypothesis Test For DiffDocument30 pagesHypothesis Test For Diffفاطمه حسينNo ratings yet
- Means Hypothesis TestingDocument5 pagesMeans Hypothesis TestingBautista MichaelNo ratings yet
- 8 Student's T TestDocument26 pages8 Student's T TestEdwin W MächtigNo ratings yet
- WEEK-2-modularDocument19 pagesWEEK-2-modularjhonrexmartirez9No ratings yet
- CLG Project ReportDocument13 pagesCLG Project Reportruchi sharmaNo ratings yet
- Sampling CLT CIDocument81 pagesSampling CLT CIM. Amin QureshiNo ratings yet
- Introduction To The T-Statistic: PSY295 Spring 2003 SummerfeltDocument19 pagesIntroduction To The T-Statistic: PSY295 Spring 2003 SummerfeltEddy MwachenjeNo ratings yet
- Stat and Prob Q4 Week 3 Module 11 Alexander Randy EstradaDocument21 pagesStat and Prob Q4 Week 3 Module 11 Alexander Randy Estradagabezarate071No ratings yet
- Chapter-1Document19 pagesChapter-1camerogabriel5No ratings yet
- MathDocument24 pagesMathNicole Mallari MarianoNo ratings yet
- Statistics and Probability: Quarter 4 - Module 3: Test Statistic On Population Mean Week 3 To Week 4Document20 pagesStatistics and Probability: Quarter 4 - Module 3: Test Statistic On Population Mean Week 3 To Week 4JoshNo ratings yet
- Inferential Statistics: Shaheena BashirDocument18 pagesInferential Statistics: Shaheena BashirQasim RafiNo ratings yet
- Sampling CLT CIDocument81 pagesSampling CLT CIariba shoukatNo ratings yet
- Science Research Iii: Second Quarter-Module 6 Hypothesis Testing For The Means - Two Sample (Independent Sample)Document9 pagesScience Research Iii: Second Quarter-Module 6 Hypothesis Testing For The Means - Two Sample (Independent Sample)marc marcNo ratings yet
- Chapter 3 - The Social SelfDocument50 pagesChapter 3 - The Social SelflamitaNo ratings yet
- Chapter 3 - The Social SelfDocument50 pagesChapter 3 - The Social SelflamitaNo ratings yet
- Lecture 11 Correlation EditedDocument32 pagesLecture 11 Correlation EditedlamitaNo ratings yet
- Dsur I Chapter 01 Why Do We Need StatisticsDocument32 pagesDsur I Chapter 01 Why Do We Need StatisticsDannyNo ratings yet
- Characteristics of ResearchDocument8 pagesCharacteristics of ResearchMARIE GO ROUND100% (1)
- IE423 PS1 Probability and Statistics Review QuestionsDocument5 pagesIE423 PS1 Probability and Statistics Review QuestionsYasemin YücebilgenNo ratings yet
- Jay Lord P. Reyes - Statistical Analysis of Sample DataDocument2 pagesJay Lord P. Reyes - Statistical Analysis of Sample DataJaylord ReyesNo ratings yet
- Statistics and Data Analytics Cheat SheetsDocument2 pagesStatistics and Data Analytics Cheat SheetsGiova RossiNo ratings yet
- Bahan CR 2Document19 pagesBahan CR 2Exty RikaNo ratings yet
- MBA Sample HR ProjectDocument89 pagesMBA Sample HR ProjectJoel MariyarajNo ratings yet
- Test 18: The Wilcoxon Matched-Pairs Signed-Ranks TestDocument12 pagesTest 18: The Wilcoxon Matched-Pairs Signed-Ranks TestaskarahNo ratings yet
- Evoloutionary Psychology:Humans Made Assortively in A Self Seek Like Algorithm Based On Facial Similarity.Document18 pagesEvoloutionary Psychology:Humans Made Assortively in A Self Seek Like Algorithm Based On Facial Similarity.Jericho CaineNo ratings yet
- CH 07 SolutionsDocument8 pagesCH 07 SolutionsS.L.L.CNo ratings yet
- International Journal of Operations & Production Management: Article InformationDocument23 pagesInternational Journal of Operations & Production Management: Article InformationAmin rmzNo ratings yet
- Big Data CAT-2 NotesDocument26 pagesBig Data CAT-2 NotesAditiya GuptaNo ratings yet
- The Impact of CSR On Customer LoyaltyDocument23 pagesThe Impact of CSR On Customer LoyaltyteresinaNo ratings yet
- Thesis Chapter 1 Hypothesis SampleDocument7 pagesThesis Chapter 1 Hypothesis Samplebsnj6chr100% (2)
- Lesson Plan (Analysis of Contingency Data)Document9 pagesLesson Plan (Analysis of Contingency Data)JELYNE SANTOSNo ratings yet
- Syllabus Economics 220Document3 pagesSyllabus Economics 220SeyranMammadovNo ratings yet
- Item Analysis-Esp 8Document22 pagesItem Analysis-Esp 8Helen SagaNo ratings yet
- How to Write a Science Lab ReportDocument17 pagesHow to Write a Science Lab ReportDeimante BlikertaiteNo ratings yet
- Sardilla's Report On Advance StatisticDocument32 pagesSardilla's Report On Advance Statisticsabel sardillaNo ratings yet
- CCRM Study Material - Module 1Document208 pagesCCRM Study Material - Module 1nupurNo ratings yet
- Panteion University, Greece: T.panagiotidis@lboro - Ac.ukDocument18 pagesPanteion University, Greece: T.panagiotidis@lboro - Ac.ukHerlan Setiawan SihombingNo ratings yet
- (P) (Atkinson, 2000) Learning From Example - Instructional Principles From The Worked Example Research PDFDocument34 pages(P) (Atkinson, 2000) Learning From Example - Instructional Principles From The Worked Example Research PDFDũng LêNo ratings yet
- Als Chapter 4 & 5Document35 pagesAls Chapter 4 & 5cj azucena100% (1)
- Statisticsprobability11 q4 Week1 v4Document10 pagesStatisticsprobability11 q4 Week1 v4Sheryn CredoNo ratings yet
- Hypothesis Testing: Procedure in Testing Hypothesis Hypothesis Testing Using P-Value One Sample Z Test One Sample T TestDocument37 pagesHypothesis Testing: Procedure in Testing Hypothesis Hypothesis Testing Using P-Value One Sample Z Test One Sample T TestLenard Del Mundo0% (1)
- M.Sc. Psychology at Madurai Kamaraj UniversityDocument9 pagesM.Sc. Psychology at Madurai Kamaraj UniversityJp PradeepNo ratings yet
- TJC JC 2 H2 Maths 2011 Mid Year Exam SolutionsDocument12 pagesTJC JC 2 H2 Maths 2011 Mid Year Exam SolutionsjimmytanlimlongNo ratings yet
- Epidemiology and Research Review: Dr. Galvez PLM NotesDocument171 pagesEpidemiology and Research Review: Dr. Galvez PLM NotesPatty Reyes100% (1)
- Six Sigma DOE PDFDocument618 pagesSix Sigma DOE PDFalex_837972068No ratings yet
- MCQ On Testing of Hypothesis 1111Document7 pagesMCQ On Testing of Hypothesis 1111nns2770100% (1)
- Statistics and Probability: Ms. Keylin H. Talavera, LPTDocument13 pagesStatistics and Probability: Ms. Keylin H. Talavera, LPTlone wvlfNo ratings yet