You might also like
- The Magical Diaries of Ethel ArcherDocument7 pagesThe Magical Diaries of Ethel Archerleeghancock100% (1)
- Minor Project: Image Forgery DetectionDocument21 pagesMinor Project: Image Forgery DetectionPradyuman Sharma100% (1)
- DeepFake Detection A Survey of Countering Malicious Deep-FakesDocument6 pagesDeepFake Detection A Survey of Countering Malicious Deep-FakesIJRASETPublicationsNo ratings yet
- COVID-19 Digital X-Rays Forgery Classification Model Using Deep LearningDocument7 pagesCOVID-19 Digital X-Rays Forgery Classification Model Using Deep LearningIAES IJAINo ratings yet
- Guarnera DeepFake Detection by Analyzing Convolutional Traces CVPRW 2020 PaperDocument10 pagesGuarnera DeepFake Detection by Analyzing Convolutional Traces CVPRW 2020 PaperNguyễn TháiNo ratings yet
- A Novel Deep Learning Framework For Copy-Move Forgery Detection in ImagesDocument27 pagesA Novel Deep Learning Framework For Copy-Move Forgery Detection in ImagesWISSALNo ratings yet
- Deepfake PresentationDocument18 pagesDeepfake Presentationbalaji xeroxNo ratings yet
- A SIFT-Based Forensic Method For Copy-Move Attack Detection and Transformation RecoveryDocument12 pagesA SIFT-Based Forensic Method For Copy-Move Attack Detection and Transformation RecoveryMohammad WaleedNo ratings yet
- Fake Face Detection Using CNNDocument6 pagesFake Face Detection Using CNNIJRASETPublicationsNo ratings yet
- Deepfake Detection Techniques: A Review: Neeraj Guhagarkar, Sanjana Desai Swanand Vaishyampayan, Ashwini SaveDocument10 pagesDeepfake Detection Techniques: A Review: Neeraj Guhagarkar, Sanjana Desai Swanand Vaishyampayan, Ashwini SaveVIVA-TECH IJRINo ratings yet
- 03 Deep Learning Approach For Cosmetic Product Detection and ClassificationDocument13 pages03 Deep Learning Approach For Cosmetic Product Detection and Classificationfrank-e18No ratings yet
- Deepfake Image Detection A Comparative Study of Three Different Convolutional Neural NetworksDocument7 pagesDeepfake Image Detection A Comparative Study of Three Different Convolutional Neural NetworksPhạm Vũ HùngNo ratings yet
- A Multi-Purpose Image Counter-Anti-ForensicDocument13 pagesA Multi-Purpose Image Counter-Anti-ForensicMohammad WaleedNo ratings yet
- DeepVision Deepfakes Detection Using Human Eye Blinking PatternDocument11 pagesDeepVision Deepfakes Detection Using Human Eye Blinking Patternsas28No ratings yet
- K024 K006 DWM ResearchPaperDocument16 pagesK024 K006 DWM ResearchPaperdharmintank09No ratings yet
- Social Distancing Technique For Covid-19 Using Yolo V5 & CNN For Fast Object Detection and Better AccuracyDocument7 pagesSocial Distancing Technique For Covid-19 Using Yolo V5 & CNN For Fast Object Detection and Better AccuracyInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Face Mask Detection ProjectDocument17 pagesFace Mask Detection Projectvaruag2022No ratings yet
- Research Article: Copy-Move Forgery Detection Technique For Forensic Analysis in Digital ImagesDocument14 pagesResearch Article: Copy-Move Forgery Detection Technique For Forensic Analysis in Digital ImagesAli RazaNo ratings yet
- General Purpose Image Tampering Detection Using Convolutional Neural Network and Local Optimal Oriented Pattern (Loop)Document20 pagesGeneral Purpose Image Tampering Detection Using Convolutional Neural Network and Local Optimal Oriented Pattern (Loop)sipijNo ratings yet
- Alarming System For Face Mask Detection and Distance To Prevent The Spread of Covid Using Image Processing TechniqueDocument5 pagesAlarming System For Face Mask Detection and Distance To Prevent The Spread of Covid Using Image Processing TechniqueInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- SeminarDocument18 pagesSeminarPranjal HejibNo ratings yet
- D6 ImageProcessingandForensicVerificationofFakeVideos Images-1Document28 pagesD6 ImageProcessingandForensicVerificationofFakeVideos Images-1Kalyan VedantamNo ratings yet
- Sensors 22 00896 v3Document17 pagesSensors 22 00896 v3Blaire LimNo ratings yet
- Paper (Related Project-3)Document9 pagesPaper (Related Project-3)Razan GaihreNo ratings yet
- A Digital Forensic Technique For Inter-Frame Video Forgery Detection Based On 3D CNN PDFDocument14 pagesA Digital Forensic Technique For Inter-Frame Video Forgery Detection Based On 3D CNN PDFNasrullah IqbalNo ratings yet
- Results and DiscussionsDocument5 pagesResults and DiscussionsUsman ShaikhNo ratings yet
- ICIP2023 Deepfake - PDF SafeDocument6 pagesICIP2023 Deepfake - PDF SafeIssa ZuhairNo ratings yet
- Exploring Spatial - Temporal Features Fusion Model For Deepfake Video DetectionDocument12 pagesExploring Spatial - Temporal Features Fusion Model For Deepfake Video DetectionIssa ZuhairNo ratings yet
- Image ManipulationDocument16 pagesImage ManipulationAditya SharmaNo ratings yet
- 1 s2.0 S0262885623001452 MainDocument21 pages1 s2.0 S0262885623001452 MainFabián VillenaNo ratings yet
- Gun Detection in Video Frames With Yolov3: December 2021Document7 pagesGun Detection in Video Frames With Yolov3: December 2021Nirnay PatilNo ratings yet
- Documentation 1Document9 pagesDocumentation 1Sarah McOnellyNo ratings yet
- Broadcasting Forensics Using Machine Learning ApproachesDocument12 pagesBroadcasting Forensics Using Machine Learning ApproachesEditor IJTSRDNo ratings yet
- Zhao Multi-Attentional Deepfake Detection CVPR 2021 PaperDocument10 pagesZhao Multi-Attentional Deepfake Detection CVPR 2021 PaperThái Nguyễn Đức ThôngNo ratings yet
- Paper (Related Project-2)Document5 pagesPaper (Related Project-2)Razan GaihreNo ratings yet
- Detection of Digital Photo Image ForgeryDocument6 pagesDetection of Digital Photo Image ForgeryKing UngNo ratings yet
- Impact of Image Resizing On Deep Learning Detectors For Training Time and Model PerformanceDocument8 pagesImpact of Image Resizing On Deep Learning Detectors For Training Time and Model Performancebryansantoso8585No ratings yet
- A Review On Deepfake Attack Detection of UserDocument7 pagesA Review On Deepfake Attack Detection of UserIJRASETPublicationsNo ratings yet
- Deep Learning For Automatic Violence Detection - Tests On The AIRTLab DatasetDocument16 pagesDeep Learning For Automatic Violence Detection - Tests On The AIRTLab DatasetCS1-50 JESSY J DNo ratings yet
- Electronics 13 00804Document22 pagesElectronics 13 00804savitaannu07No ratings yet
- Amerini Deepfake Video Detection Through Optical Flow Based CNN ICCVW 2019 PaperDocument3 pagesAmerini Deepfake Video Detection Through Optical Flow Based CNN ICCVW 2019 PaperNaturalHealth tipsNo ratings yet
- C E N V T V D D: Ombining Fficient Et and Ision Ransformers For Ideo Eepfake EtectionDocument8 pagesC E N V T V D D: Ombining Fficient Et and Ision Ransformers For Ideo Eepfake EtectionSuraj JadhavNo ratings yet
- Efficient Technique On Face Recognition Using CNNDocument7 pagesEfficient Technique On Face Recognition Using CNNIJRASETPublicationsNo ratings yet
- 2021 Democratising Deep Learning For Microscopy With ZeroCostDL4MicDocument18 pages2021 Democratising Deep Learning For Microscopy With ZeroCostDL4MictippitoppiNo ratings yet
- Failed To Extract Project Title.Document11 pagesFailed To Extract Project Title.dataprodcsNo ratings yet
- A Literature Study On Image ForgeryDocument9 pagesA Literature Study On Image ForgerySrilakshmi VNo ratings yet
- Deepfake Video Detection Using Convolutional VisioDocument9 pagesDeepfake Video Detection Using Convolutional VisioRazan GaihreNo ratings yet
- Jia Bin Huang Research StatementDocument6 pagesJia Bin Huang Research StatementdewufhweuihNo ratings yet
- ELA ForgeryDocument5 pagesELA Forgerysuresh mpNo ratings yet
- Amerini 2013Document11 pagesAmerini 2013DEBJANI CHAKRABORTYNo ratings yet
- Deepfake Video Detection Using Convolutional Vision TransformerDocument9 pagesDeepfake Video Detection Using Convolutional Vision TransformerBuhushika KumarageNo ratings yet
- Copy Move Forgery Detection Using Discrete Cosine Transform and Bacterial Foraging OptimizationDocument6 pagesCopy Move Forgery Detection Using Discrete Cosine Transform and Bacterial Foraging OptimizationInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Pan 2020Document10 pagesPan 2020ahmed.amr22No ratings yet
- Deepfake Image DetectionDocument7 pagesDeepfake Image DetectionVignesh VishalNo ratings yet
- Review of Pose Recognition SystemsDocument8 pagesReview of Pose Recognition SystemsVIVA-TECH IJRINo ratings yet
- CrowdGAN - Identity-Free Interactive Crowd Video Generation and BeyondDocument16 pagesCrowdGAN - Identity-Free Interactive Crowd Video Generation and BeyondmmmmNo ratings yet
- Detectx: A Deepfake Detection SystemDocument17 pagesDetectx: A Deepfake Detection SystemJaeNo ratings yet
- Marissa 2 IMVIP2018 BookDocument4 pagesMarissa 2 IMVIP2018 BookNguyễn TháiNo ratings yet
- Face Mask Detection Using Yolov3 and Faster R-CNN Models: Covid-19 EnvironmentDocument16 pagesFace Mask Detection Using Yolov3 and Faster R-CNN Models: Covid-19 EnvironmentTrung Huynh KienNo ratings yet
- Transfer Learning Approach For Splicing and Copy-Move Image Tampering DetectionDocument6 pagesTransfer Learning Approach For Splicing and Copy-Move Image Tampering DetectionLABIDNo ratings yet
- EXERCISE 1-Passive FormDocument5 pagesEXERCISE 1-Passive FormMichele LangNo ratings yet
- The Post OfficeDocument4 pagesThe Post OfficeKatherine LuisNo ratings yet
- Soal Materi 1 KLS X IntroductionDocument2 pagesSoal Materi 1 KLS X IntroductionFira AnandaNo ratings yet
- Students List - All SectionsDocument8 pagesStudents List - All SectionsChristian RiveraNo ratings yet
- Hazardous Location Division Listed LED Light: Model 191XLDocument2 pagesHazardous Location Division Listed LED Light: Model 191XLBernardo Damas EspinozaNo ratings yet
- TaxationDocument26 pagesTaxationReynamae Garcia AbalesNo ratings yet
- Talking SwedishDocument32 pagesTalking Swedishdiana jimenezNo ratings yet
- SAP Logistics Process ScopeDocument3 pagesSAP Logistics Process ScopecasiloNo ratings yet
- Effectives of e Wallets NewDocument15 pagesEffectives of e Wallets NewRicardo SantosNo ratings yet
- Sample Paper For Professional Ethics in Accounting and FinanceDocument6 pagesSample Paper For Professional Ethics in Accounting and FinanceWinnieOngNo ratings yet
- The Camera Obscura Was Increasingly Used by ArtistsDocument4 pagesThe Camera Obscura Was Increasingly Used by Artistsapi-284704512No ratings yet
- Intro To Semiology Reading NotesDocument6 pagesIntro To Semiology Reading NotesRyan DrakeNo ratings yet
- Qualitative Analysis of Selected Medicinal Plants, Tamilnadu, IndiaDocument3 pagesQualitative Analysis of Selected Medicinal Plants, Tamilnadu, IndiaDiana RaieNo ratings yet
- West Bengal State University Department of EnglishDocument33 pagesWest Bengal State University Department of Englishnandan yadavNo ratings yet
- WearebecausewebelongDocument3 pagesWearebecausewebelongapi-269453634No ratings yet
- Fractal Blaster Trading Strategy ReportDocument22 pagesFractal Blaster Trading Strategy ReportIcky IckyNo ratings yet
- Business Mathematics 11 Q2 Week3 MELC20 MELC21 MOD Baloaloa, JeffersonDocument25 pagesBusiness Mathematics 11 Q2 Week3 MELC20 MELC21 MOD Baloaloa, JeffersonJefferson BaloaloaNo ratings yet
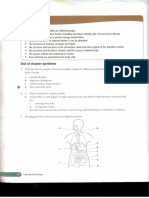
- End-Of-Chapter Questions: CambridgeDocument17 pagesEnd-Of-Chapter Questions: CambridgeMido MidoNo ratings yet
- Criminal InvestigationDocument11 pagesCriminal Investigationjohn martin urbinaNo ratings yet
- A Feasibility/Project Study OnDocument14 pagesA Feasibility/Project Study OnWilson Domingo LazarteNo ratings yet
- Arabic Unit 1 June 2011 Mark SchemeDocument9 pagesArabic Unit 1 June 2011 Mark SchemeGhaleb W. MihyarNo ratings yet
- Once Upon A Timein AmericaDocument335 pagesOnce Upon A Timein Americaqwerty-keysNo ratings yet
- Coca Cola FSDocument3 pagesCoca Cola FSManan MunshiNo ratings yet
- Nabard Working CapitalDocument12 pagesNabard Working CapitalJaspreet SinghNo ratings yet
- My Favorite MovieDocument2 pagesMy Favorite MovieAnabellyluNo ratings yet
- Ap Government Imperial PresidencyDocument2 pagesAp Government Imperial Presidencyapi-234443616No ratings yet
- Dossier 015 enDocument5 pagesDossier 015 enAshok KumarNo ratings yet
- SPE 166182 Radio Frequency Identification (RFID) Leads The Way in The Quest For Intervention Free Upper Completion InstallationDocument9 pagesSPE 166182 Radio Frequency Identification (RFID) Leads The Way in The Quest For Intervention Free Upper Completion InstallationjangolovaNo ratings yet
- Regional Trial Court National Capital Judicial Region: ComplainantDocument5 pagesRegional Trial Court National Capital Judicial Region: ComplainantNeil Patrick QuiniquiniNo ratings yet