You might also like
- Sample Questions Pattern RecognitionDocument8 pagesSample Questions Pattern RecognitionDebadutta NayakNo ratings yet
- EDA Final Exam Question PaperDocument2 pagesEDA Final Exam Question Papernipun malikNo ratings yet
- Linear Regression Analysis: Module - IDocument13 pagesLinear Regression Analysis: Module - Iwec33DFSNo ratings yet
- Linear Regression Analysis: Module - IDocument13 pagesLinear Regression Analysis: Module - InihajnoorNo ratings yet
- Applied Statistical Methodology For Research BusinessDocument12 pagesApplied Statistical Methodology For Research BusinessgeofreyNo ratings yet
- Stat 473-573 NotesDocument139 pagesStat 473-573 NotesArkadiusz Michael BarNo ratings yet
- Chapter 1. Elements in Predictive AnalyticsDocument66 pagesChapter 1. Elements in Predictive AnalyticsChristopherNo ratings yet
- Lesson 2: Multiple Linear Regression Model (I) : E L F V A L U A T I O N X E R C I S E SDocument14 pagesLesson 2: Multiple Linear Regression Model (I) : E L F V A L U A T I O N X E R C I S E SMauricio Ortiz OsorioNo ratings yet
- Econ 335 Wooldridge CH 8 HeteroskedasticityDocument23 pagesEcon 335 Wooldridge CH 8 Heteroskedasticityminhly12104No ratings yet
- Ordinary Least SquaresDocument21 pagesOrdinary Least SquaresRahulsinghooooNo ratings yet
- Maruo Etal 2017Document15 pagesMaruo Etal 2017Andre Luiz GrionNo ratings yet
- Regression and CorrelationDocument13 pagesRegression and CorrelationzNo ratings yet
- MicroEconometrics Lecture10Document27 pagesMicroEconometrics Lecture10Carolina Correa CaroNo ratings yet
- Name: Muhammad Siddique Class: B.Ed. Semester: Fifth Subject: Inferential Statistics Submitted To: Sir Sajid AliDocument6 pagesName: Muhammad Siddique Class: B.Ed. Semester: Fifth Subject: Inferential Statistics Submitted To: Sir Sajid Aliusama aliNo ratings yet
- A Mathematical Model Analysis PDFDocument13 pagesA Mathematical Model Analysis PDFaadit jainNo ratings yet
- Chapter 3Document36 pagesChapter 3feyisaabera19No ratings yet
- Applied Statistical Methodology For Research BusinessDocument12 pagesApplied Statistical Methodology For Research BusinessgeofreyNo ratings yet
- Applied Linear Regression Models 4th Ed NoteDocument46 pagesApplied Linear Regression Models 4th Ed Noteken_ng333No ratings yet
- Bayesian Modelling For Data Analysis and Learning From DataDocument19 pagesBayesian Modelling For Data Analysis and Learning From DataJoan AlbiolNo ratings yet
- Chat Openai Com Share 42b24a73 839b 4128 Ade9 7d8eed9e9533Document21 pagesChat Openai Com Share 42b24a73 839b 4128 Ade9 7d8eed9e9533NadhiyaNo ratings yet
- Regression With A Binary Dependent Variable: Michael AshDocument18 pagesRegression With A Binary Dependent Variable: Michael AshFatemeh IglinskyNo ratings yet
- 03 ES Regression CorrelationDocument14 pages03 ES Regression CorrelationMuhammad AbdullahNo ratings yet
- LeastAngle 2002Document44 pagesLeastAngle 2002liuNo ratings yet
- Logistic Regression-1Document37 pagesLogistic Regression-1Ali HassanNo ratings yet
- Amosweek 4Document7 pagesAmosweek 4AsherNo ratings yet
- Multiple Linear Regression in Data MiningDocument14 pagesMultiple Linear Regression in Data Miningakirank1100% (1)
- 7CCMMS61 Statistics For Data Analysis: Francisco Javier Rubio Department of MathematicsDocument13 pages7CCMMS61 Statistics For Data Analysis: Francisco Javier Rubio Department of MathematicsViorel AdirvaNo ratings yet
- BiostatisticsDocument45 pagesBiostatisticsHOD ODNo ratings yet
- Kuss Poster Global Goodness-Of-fit Tests in Logistic Regression With Sparse DataDocument1 pageKuss Poster Global Goodness-Of-fit Tests in Logistic Regression With Sparse Dataerfk890No ratings yet
- Econometrics Assig 1Document13 pagesEconometrics Assig 1ahmed0% (1)
- CH 4 Multiple Regression ModelsDocument28 pagesCH 4 Multiple Regression Modelspkj009No ratings yet
- Chapter Three 3.0 Methodology 3.1 Source of DataDocument10 pagesChapter Three 3.0 Methodology 3.1 Source of DataOlaolu JosephNo ratings yet
- Geographically Weighted Regression: Martin Charlton A Stewart FotheringhamDocument17 pagesGeographically Weighted Regression: Martin Charlton A Stewart FotheringhamAgus Salim ArsyadNo ratings yet
- A Beginner's Notes On Bayesian Econometrics (Art)Document21 pagesA Beginner's Notes On Bayesian Econometrics (Art)amerdNo ratings yet
- Learn Statistics Fast: A Simplified Detailed Version for StudentsFrom EverandLearn Statistics Fast: A Simplified Detailed Version for StudentsNo ratings yet
- บทความภาษาอังกฤษDocument9 pagesบทความภาษาอังกฤษTANAWAT SUKKHAONo ratings yet
- AML-CH3-linear RegressionDocument83 pagesAML-CH3-linear Regressionthe endNo ratings yet
- Simple Regression Model: Erbil Technology InstituteDocument9 pagesSimple Regression Model: Erbil Technology Institutemhamadhawlery16No ratings yet
- INFERENCEDocument32 pagesINFERENCEAyush GuptaNo ratings yet
- Latent Class Models For Financial Data Analysis: Some Statistical DevelopmentsDocument21 pagesLatent Class Models For Financial Data Analysis: Some Statistical DevelopmentsAnonymous 4gOYyVfdfNo ratings yet
- Latent Class Models For Financial Data Analysis: Some Statistical DevelopmentsDocument21 pagesLatent Class Models For Financial Data Analysis: Some Statistical DevelopmentsAnonymous 4gOYyVfdfNo ratings yet
- Extra Problems: Statistics Review: 1 Understanding Univariate DataDocument8 pagesExtra Problems: Statistics Review: 1 Understanding Univariate DataLê Nguyễn Thị HảiNo ratings yet
- Regression Analysis 01Document56 pagesRegression Analysis 01IRPS100% (5)
- UC Berkeley Econ 140 Section 10Document8 pagesUC Berkeley Econ 140 Section 10AkhilNo ratings yet
- Multiple RegressionDocument49 pagesMultiple RegressionOisín Ó CionaoithNo ratings yet
- Class 7Document42 pagesClass 7rishabhNo ratings yet
- 8.31.17 Final Data Science Lecture 1Document13 pages8.31.17 Final Data Science Lecture 1BhuveshAroraNo ratings yet
- LogregDocument26 pagesLogregroy royNo ratings yet
- 04 Violation of Assumptions AllDocument24 pages04 Violation of Assumptions AllFasiko AsmaroNo ratings yet
- Unit 5 Probabilistic ModelsDocument39 pagesUnit 5 Probabilistic ModelsRam100% (1)
- Statistics 3 NotesDocument90 pagesStatistics 3 Notesnajam u saqibNo ratings yet
- Assignment On Probit ModelDocument17 pagesAssignment On Probit ModelNidhi KaushikNo ratings yet
- Applied Business Forecasting and Planning: Multiple Regression AnalysisDocument100 pagesApplied Business Forecasting and Planning: Multiple Regression AnalysisRobby PangestuNo ratings yet
- Simple Linear Regression and Multiple Linear Regression: MAST 6474 Introduction To Data Analysis IDocument15 pagesSimple Linear Regression and Multiple Linear Regression: MAST 6474 Introduction To Data Analysis IJohn SmithNo ratings yet
- Statistics 1Document97 pagesStatistics 1BJ TiewNo ratings yet
- Home Lesson 15: Logistic, Poisson & Nonlinear RegressionDocument32 pagesHome Lesson 15: Logistic, Poisson & Nonlinear RegressionShubham TewariNo ratings yet
- Financial Econometrics: Instructor Sergio Focardi PHD Tel: + 33 (0) 4 9318 7820 Email: Sergio - Focardi@Edhec - EduDocument55 pagesFinancial Econometrics: Instructor Sergio Focardi PHD Tel: + 33 (0) 4 9318 7820 Email: Sergio - Focardi@Edhec - EduAnilkumar SinghNo ratings yet
- Logistic Regression in Data Analysis: An OverviewDocument21 pagesLogistic Regression in Data Analysis: An OverviewSAHIL PAHUJANo ratings yet
- Predicting Outcome of Soccer Matches Using Machine LearningDocument12 pagesPredicting Outcome of Soccer Matches Using Machine LearningDavos SavosNo ratings yet
- Full Text INC 2020 AgustaDocument9 pagesFull Text INC 2020 Agustaarina chusnatayainiNo ratings yet
- High Low MethodDocument4 pagesHigh Low MethodSamreen LodhiNo ratings yet
- Hextran Keyword v9Document407 pagesHextran Keyword v9Carlos Corrales Linares100% (1)
- bài tậpDocument4 pagesbài tậpthlinh2801No ratings yet
- Effect of Blue Ocean Strategy On The Performance of Telecommunication Firms in South East NigeriaDocument9 pagesEffect of Blue Ocean Strategy On The Performance of Telecommunication Firms in South East NigeriaNandar Swe TintNo ratings yet
- 86 English TarjomeFaDocument11 pages86 English TarjomeFaKelvin MusarurwaNo ratings yet
- 5116Document21 pages5116Malcolm ChristopherNo ratings yet
- Practical Lab 2Document1 pagePractical Lab 2crazyfrog1991No ratings yet
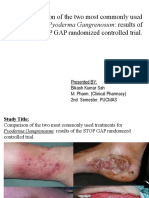
- Pyoderma GangrenosumDocument18 pagesPyoderma GangrenosumBikash SahNo ratings yet
- Rr311801 Probability and StatisticsDocument8 pagesRr311801 Probability and Statisticsgeddam06108825No ratings yet
- IDA-Group Assignment QuestionDocument6 pagesIDA-Group Assignment Questionvenice wxNo ratings yet
- ISLR Chap 1 & 2Document16 pagesISLR Chap 1 & 2Shaheryar ZahurNo ratings yet
- Thesis Mingliang LiDocument279 pagesThesis Mingliang Limanzoni1100% (1)
- Rnews 2007-3Document62 pagesRnews 2007-3juntujuntuNo ratings yet
- Copula RegressionDocument23 pagesCopula RegressionRoyal BengalNo ratings yet
- Jurnal Ilmu KehutananDocument15 pagesJurnal Ilmu KehutananAngelius M NababanNo ratings yet
- Analysis On Dividend Payout: Empirical Evidence of Property Companies in MalaysiaDocument11 pagesAnalysis On Dividend Payout: Empirical Evidence of Property Companies in MalaysiaLink LinkNo ratings yet
- Kinney 8e - IM - CH 03Document17 pagesKinney 8e - IM - CH 03Ted Bryan D. CabaguaNo ratings yet
- Traffic Engineering-Lecture 4Document20 pagesTraffic Engineering-Lecture 4Ahmad SalihNo ratings yet
- Criteria of Minimum Shear Stress vs. Minimum Velocity For Self-Cleaning Sewer Pipes DesignDocument7 pagesCriteria of Minimum Shear Stress vs. Minimum Velocity For Self-Cleaning Sewer Pipes DesignSushma PatelNo ratings yet
- Simple Linear Regression AnalysisDocument27 pagesSimple Linear Regression AnalysisakshNo ratings yet
- Earthquake-Risk Salience and Housing PricesDocument10 pagesEarthquake-Risk Salience and Housing PricesAnnA BNo ratings yet
- Food SpoilageDocument14 pagesFood SpoilageFariha SamadNo ratings yet
- Data Mining Concepts and TechniquesDocument136 pagesData Mining Concepts and TechniquesGirish Acharya0% (1)
- PH.D Thesis by Shamira Malekar PDFDocument295 pagesPH.D Thesis by Shamira Malekar PDFPankaj Kumar srivastavaNo ratings yet
- Employee Engagement and Contextual Performance of PDFDocument8 pagesEmployee Engagement and Contextual Performance of PDFHazrat BilalNo ratings yet
- Chapter Two: Simple Linear Regression Models: Assumptions and EstimationDocument34 pagesChapter Two: Simple Linear Regression Models: Assumptions and Estimationeferem100% (3)
- Stevens 2007 ANCOVA ChapterDocument35 pagesStevens 2007 ANCOVA ChapterNazia SyedNo ratings yet
- HHHHJHDocument3 pagesHHHHJHSunair SunuNo ratings yet