You might also like
- Econometrics Assignment 3Document4 pagesEconometrics Assignment 3Pedro FernandezNo ratings yet
- Lesson 4.2 Intermediate and Extreme Value TheoremDocument24 pagesLesson 4.2 Intermediate and Extreme Value Theoremあ き100% (1)
- Simple Linear RegressionDocument4 pagesSimple Linear RegressionkasuwedaNo ratings yet
- Homework 5Document6 pagesHomework 5euler96No ratings yet
- Chart TitleDocument4 pagesChart TitleDannyNo ratings yet
- Validation of Fps Wizard Horizontal Lifeline CalculatorDocument1 pageValidation of Fps Wizard Horizontal Lifeline CalculatorperundingtsteohgmailcomNo ratings yet
- Principles of Chemistry A Molecular Approach 2nd Edition Tro Solutions Manual 1Document36 pagesPrinciples of Chemistry A Molecular Approach 2nd Edition Tro Solutions Manual 1tammycontrerasgdaxwypisr100% (27)
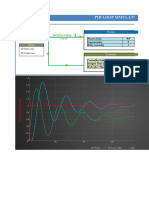
- PID Loop SimulatorDocument9 pagesPID Loop SimulatorJavierSanchezNo ratings yet
- QT of ProteinDocument22 pagesQT of Proteinbram.soenen1No ratings yet
- A6 Regression Challenge ANSWERSDocument6 pagesA6 Regression Challenge ANSWERSeoip.swdept.mgmtNo ratings yet
- PID Loop Simulator AutomationforumDocument8 pagesPID Loop Simulator Automationforumboyievmuhriddin5No ratings yet
- Graph Eng PDFDocument1 pageGraph Eng PDFalejandroruiz020697No ratings yet
- PID Loop SimulatorDocument9 pagesPID Loop Simulatormohammad imronNo ratings yet
- Complex Analysis PracticalsDocument15 pagesComplex Analysis PracticalsChitparaNo ratings yet
- Root Locus and Matlab ProgrammingDocument6 pagesRoot Locus and Matlab Programmingshaista00550% (2)
- Lecture 5 - 8 - Introduction To Feedback Control LoopsDocument28 pagesLecture 5 - 8 - Introduction To Feedback Control LoopsSurendra Louis Dupuis NaikerNo ratings yet
- Pid Loop Simulator: ProcessDocument9 pagesPid Loop Simulator: ProcessDWNLD USRMLNo ratings yet
- PID Loop SimulatorDocument9 pagesPID Loop SimulatorErnesto MoralesNo ratings yet
- Analog To Digital Converters: Presentation OutlineDocument23 pagesAnalog To Digital Converters: Presentation Outlinepriyanka_lakshmi093907No ratings yet
- 2SC5706 e PDFDocument10 pages2SC5706 e PDFGudiño OrteganojfNo ratings yet
- Pid Loop Simulator: ProcessDocument10 pagesPid Loop Simulator: ProcessBenjamin FonsecaNo ratings yet
- Alps Electric (Malaysia) SDN BHD: N VN XDocument1 pageAlps Electric (Malaysia) SDN BHD: N VN XAzrul AzimNo ratings yet
- Smitch ChartDocument3 pagesSmitch ChartBharat ChNo ratings yet
- Md. Jahirul IslamDocument2 pagesMd. Jahirul IslamMr. JahirNo ratings yet
- Data Sheet: Low VF Switching DiodeDocument7 pagesData Sheet: Low VF Switching DiodeCess FaridilNo ratings yet
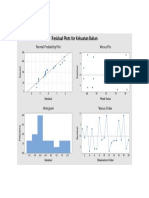
- Residual Plots For Kekuatan BahanDocument1 pageResidual Plots For Kekuatan BahanFebrian IsharyadiNo ratings yet
- Spe 2322 Geophysics Lectures 4&5Document96 pagesSpe 2322 Geophysics Lectures 4&5Martinez MutaiNo ratings yet
- Ultrahigh-Speed Switching Applications: Package Dimensions FeaturesDocument4 pagesUltrahigh-Speed Switching Applications: Package Dimensions FeaturesJosephSyNo ratings yet
- Arbol de DecisiónDocument6 pagesArbol de Decisiónthegamerangel26No ratings yet
- Residual Plots For Yield: Normal Probability Plot Versus FitsDocument3 pagesResidual Plots For Yield: Normal Probability Plot Versus FitsBablu KumarNo ratings yet
- VaR For Philippine Fixed Income MarketDocument16 pagesVaR For Philippine Fixed Income MarketJoshy_29No ratings yet
- Catkul d3 081117Document6 pagesCatkul d3 081117Try Zivilians ZetiaNo ratings yet
- Catkul d3 081117Document6 pagesCatkul d3 081117Try Zivilians ZetiaNo ratings yet
- Crack Growth Curve: Number of CyclesDocument5 pagesCrack Growth Curve: Number of CyclesGundagani Sai Kumar ce18m081No ratings yet
- CH4-Root Locus Design PDFDocument11 pagesCH4-Root Locus Design PDFLove StrikeNo ratings yet
- Lab 6Document6 pagesLab 6Ximena UribeNo ratings yet
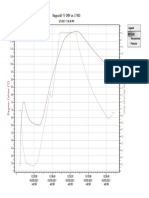
- Raypa GraphDocument1 pageRaypa GrapheeeeNo ratings yet
- Homework7 PDFDocument6 pagesHomework7 PDFdemetriusNo ratings yet
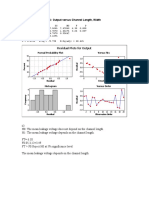
- Two-Way ANOVA: Output Versus Channel Length, Width: Normal Probability Plot Versus FitsDocument1 pageTwo-Way ANOVA: Output Versus Channel Length, Width: Normal Probability Plot Versus FitsFfmohamad NAdNo ratings yet
- Di Tanya KanDocument6 pagesDi Tanya KanIla PermataNo ratings yet
- UofT BetaDistributionDocument1 pageUofT BetaDistributionlainNo ratings yet
- Curve Ncy Clop 09Document30 pagesCurve Ncy Clop 09smithap_ullalNo ratings yet
- HDM24216H-2: Dimensional DrawingDocument2 pagesHDM24216H-2: Dimensional DrawingGustavo NielNo ratings yet
- CDMA RF Optimization: October 2000Document32 pagesCDMA RF Optimization: October 2000loganathan8No ratings yet
- Proof Evaluation Progress Report Accomplishment Report Proposal/MatrixDocument3 pagesProof Evaluation Progress Report Accomplishment Report Proposal/MatrixSharmaine EfondoNo ratings yet
- Six Sigma With RDocument296 pagesSix Sigma With RAnderson Rosa de SouzaNo ratings yet
- Weighted Preferences in Evolutionary Multi-Objective OptimizationDocument10 pagesWeighted Preferences in Evolutionary Multi-Objective Optimizationmehmetkartal19No ratings yet
- Ying Hum VA3YH Circular SR-1Document1 pageYing Hum VA3YH Circular SR-1Carlos ToguchiNo ratings yet
- Oceanography and Marine Biology RepairedDocument542 pagesOceanography and Marine Biology Repairedajik indiantoNo ratings yet
- Project Name: Earned Value Analysis ReportDocument3 pagesProject Name: Earned Value Analysis ReportEyutt HghghNo ratings yet
- Project Name: Earned Value Analysis ReportDocument3 pagesProject Name: Earned Value Analysis ReportSattu RjNo ratings yet
- Refining & Petrochemicals IntegrationDocument19 pagesRefining & Petrochemicals IntegrationSangeeta GargNo ratings yet
- Power Transistor ( 60V, 3A) : 2SB1184 / 2SB1243Document3 pagesPower Transistor ( 60V, 3A) : 2SB1184 / 2SB1243vali2daduicaNo ratings yet
- N X N X N y N y N Y: Digital Filter Design Using MATLABDocument12 pagesN X N X N y N y N Y: Digital Filter Design Using MATLABAdhiraj MahajanNo ratings yet
- Tugas Sesi 15 Probabilitas Dan Statistika - UAS Jois Sumardin GuloDocument3 pagesTugas Sesi 15 Probabilitas Dan Statistika - UAS Jois Sumardin GuloJois sumardin GuloNo ratings yet
- Power-Quality - Schneider PresentationDocument114 pagesPower-Quality - Schneider PresentationdavialacerdaNo ratings yet
- All ResultsDocument29 pagesAll ResultsAndrew EwersNo ratings yet
- ระยะห่างแถวDocument1 pageระยะห่างแถวWarajak N.No ratings yet
- End Term Simulation Project1Document13 pagesEnd Term Simulation Project1chinmay garanayakNo ratings yet
- Trazador Lineal Datos X F (X) 3 2.5 4.5 1 7 2.5 9 0.5 Pendiente M 0.6 F 5 1.3Document10 pagesTrazador Lineal Datos X F (X) 3 2.5 4.5 1 7 2.5 9 0.5 Pendiente M 0.6 F 5 1.3mauricio lopezNo ratings yet
- RCBDDocument6 pagesRCBDkasuwedaNo ratings yet
- Time SeriesDocument6 pagesTime SerieskasuwedaNo ratings yet
- CRDDocument6 pagesCRDkasuwedaNo ratings yet
- Multiple Linear RegressionDocument5 pagesMultiple Linear RegressionkasuwedaNo ratings yet
- RCBDDocument6 pagesRCBDkasuwedaNo ratings yet
- LSDDocument7 pagesLSDkasuwedaNo ratings yet
- Time SeriesDocument6 pagesTime SerieskasuwedaNo ratings yet
- Final Lab ManualDocument34 pagesFinal Lab ManualSNEHAL RALEBHATNo ratings yet
- LIAM Mortality Investigation Summary Report 2011 2015Document23 pagesLIAM Mortality Investigation Summary Report 2011 2015Hafiz IqbalNo ratings yet
- Quantitative Chapter 3Document40 pagesQuantitative Chapter 3Robel HabtamuNo ratings yet
- Ai Lab File For PtuDocument29 pagesAi Lab File For PtuAshish Ranjan SinghNo ratings yet
- Distribusi TemperaturDocument10 pagesDistribusi TemperaturAdri SuryanaNo ratings yet
- First Sem 2021 2022-GE 4 - SECOND EXAM - QUESTIONNAIRE (PART 2) Updated As of 2nd Term First Sem 2021 2022Document2 pagesFirst Sem 2021 2022-GE 4 - SECOND EXAM - QUESTIONNAIRE (PART 2) Updated As of 2nd Term First Sem 2021 2022菲希傑Tamayo100% (1)
- Frequency Response Analysis Using Bode PlotDocument44 pagesFrequency Response Analysis Using Bode Plotjayant kumarNo ratings yet
- CH-7, MATH-5 - LECTURE - NOTE - Summer - 20-21Document10 pagesCH-7, MATH-5 - LECTURE - NOTE - Summer - 20-21আসিফ রেজাNo ratings yet
- How Kriging WorksDocument8 pagesHow Kriging WorksSUMIT SUMANNo ratings yet
- Matlab Fundamental 12Document11 pagesMatlab Fundamental 12duc anhNo ratings yet
- 0222 - Equations Worksheet PDFDocument3 pages0222 - Equations Worksheet PDFJunel Icamen EnriquezNo ratings yet
- Step FOPDT LengkapDocument110 pagesStep FOPDT LengkapRio Ananda PutraNo ratings yet
- Discrete Structures Notes - TutorialsDuniyaDocument136 pagesDiscrete Structures Notes - TutorialsDuniyaforsomepurpose01No ratings yet
- Villanova University Department of Mechanical Engineering: EGR 8304: Nonlinear ControlDocument2 pagesVillanova University Department of Mechanical Engineering: EGR 8304: Nonlinear Controljuan carlosNo ratings yet
- 1 s2.0 S0950061822028185 MainDocument18 pages1 s2.0 S0950061822028185 Mainmohammad faresNo ratings yet
- Theory: - Unification - Unification in Prolog - Proof SearchDocument63 pagesTheory: - Unification - Unification in Prolog - Proof SearchAulia RahmiNo ratings yet
- Excel FFTDocument5 pagesExcel FFTKunal MasaniaNo ratings yet
- Average DeviationDocument2 pagesAverage DeviationRandom Bll ShTNo ratings yet
- CSL759: Cryptography and Computer Security: Ragesh Jaiswal CSE, IIT DelhiDocument38 pagesCSL759: Cryptography and Computer Security: Ragesh Jaiswal CSE, IIT DelhiPawan NaniNo ratings yet
- LPP Solution Using Simplex MethodDocument56 pagesLPP Solution Using Simplex Methodrohit4567867% (3)
- Algorithm & FlowchartDocument7 pagesAlgorithm & FlowchartAnas ShaikhNo ratings yet
- The Simplex Algorithm: Putting Linear Programs Into Standard Form Introduction To Simplex AlgorithmDocument25 pagesThe Simplex Algorithm: Putting Linear Programs Into Standard Form Introduction To Simplex AlgorithmmritroyNo ratings yet
- Jacob Eisenstein - Natural Language Processing-MIT PressDocument591 pagesJacob Eisenstein - Natural Language Processing-MIT Presskpratik41No ratings yet
- Fuzzy If ThenDocument7 pagesFuzzy If Thenhasan_azeem08No ratings yet
- Numerical Analysis-Solving Linear SystemsDocument23 pagesNumerical Analysis-Solving Linear SystemsMohammad OzairNo ratings yet
- CP Algorithms Com Algebra Binary Exp HTMLDocument5 pagesCP Algorithms Com Algebra Binary Exp HTMLArnab SenNo ratings yet
- Linear System TheoryDocument2 pagesLinear System Theoryrana usman amjadNo ratings yet
- TOO4TO Module 7 / Artificial Intelligence and Sustainability: Part 1Document17 pagesTOO4TO Module 7 / Artificial Intelligence and Sustainability: Part 1TOO4TONo ratings yet
- Day 1Document32 pagesDay 1ganareddysNo ratings yet