You might also like
- Nthu BacshwDocument8 pagesNthu Bacshw黃淑菱No ratings yet
- ML0101EN Reg Mulitple Linear Regression Co2 Py v1Document5 pagesML0101EN Reg Mulitple Linear Regression Co2 Py v1Rajat SolankiNo ratings yet
- ML0101EN Reg Simple Linear Regression Co2 Py v1Document4 pagesML0101EN Reg Simple Linear Regression Co2 Py v1Muhammad RaflyNo ratings yet
- Module - 4 (R Training) - Basic Stats & ModelingDocument15 pagesModule - 4 (R Training) - Basic Stats & ModelingRohitGahlanNo ratings yet
- ML Lab 10 - Ensemble LearningDocument7 pagesML Lab 10 - Ensemble LearningPRIYANSH AGGARWALNo ratings yet
- Case Study: Business Analytics 2019-20Document8 pagesCase Study: Business Analytics 2019-20Jean-Loïc BinamNo ratings yet
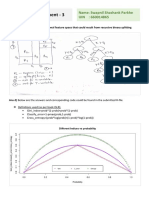
- IDS 575 Assignment - 3: Name: Swapnil Shashank Parkhe UIN: 660014865Document7 pagesIDS 575 Assignment - 3: Name: Swapnil Shashank Parkhe UIN: 660014865Swapnil ParkheNo ratings yet
- Machine Learning Project: Choice of Employee Mode of TransportDocument35 pagesMachine Learning Project: Choice of Employee Mode of TransportDatapoint MavericksNo ratings yet
- P05 The Regression Pipeline - Training and Testing AnsDocument13 pagesP05 The Regression Pipeline - Training and Testing AnsYONG LONG KHAWNo ratings yet
- Predict used Toyota Corolla prices from specsDocument5 pagesPredict used Toyota Corolla prices from specspavan adapalaNo ratings yet
- 8 Ejercicio - Optimización y Guardado de Modelos - Training - Microsoft Learn InglesDocument13 pages8 Ejercicio - Optimización y Guardado de Modelos - Training - Microsoft Learn Inglesacxel david castillo casasNo ratings yet
- Machine Learning Project On CarsDocument22 pagesMachine Learning Project On Carsbhumika singh92% (13)
- 04-Classification & Tunning - Copie PDFDocument54 pages04-Classification & Tunning - Copie PDFSalma TebaaNo ratings yet
- Term Paper On WEKADocument19 pagesTerm Paper On WEKAAmrit KumarNo ratings yet
- Machine Learning with Tree-Based Models in R: An Introduction to Regression Trees, Hyperparameters, and Grid SearchDocument21 pagesMachine Learning with Tree-Based Models in R: An Introduction to Regression Trees, Hyperparameters, and Grid SearchMikistli YowaltekutliNo ratings yet
- StatisticsDocument10 pagesStatisticsnoufatcourseraNo ratings yet
- Functions and PackagesDocument7 pagesFunctions and PackagesNur SyazlianaNo ratings yet
- K MeansDocument329 pagesK Meansyousef shaban100% (1)
- Lin Regr and ArimaDocument6 pagesLin Regr and Arimaapi-223061586No ratings yet
- Data Science - Decision Tree - Random ForestDocument15 pagesData Science - Decision Tree - Random ForestMahesh PokhrelNo ratings yet
- R AssignmentDocument8 pagesR AssignmentTunaNo ratings yet
- Answers For End-Sem Exam Part - 2 (Deep Learning)Document20 pagesAnswers For End-Sem Exam Part - 2 (Deep Learning)Ankur BorkarNo ratings yet
- How To Train A Model With MNIST DatasetDocument7 pagesHow To Train A Model With MNIST DatasetMagdalena FalkowskaNo ratings yet
- Employee Transport Mode PredictionDocument22 pagesEmployee Transport Mode Predictionbhumika singh100% (1)
- Rstudio Study Notes For PA 20181126Document6 pagesRstudio Study Notes For PA 20181126Trong Nghia VuNo ratings yet
- Ensemble Learning and Random ForestsDocument37 pagesEnsemble Learning and Random ForestsDhanunjayanath reddy konudulaNo ratings yet
- Introduction To Basics of R - Assignment: Log2 (2 5) Log (Exp (1) Exp (2) )Document10 pagesIntroduction To Basics of R - Assignment: Log2 (2 5) Log (Exp (1) Exp (2) )optimistic_harishNo ratings yet
- Image ClassificationDocument18 pagesImage ClassificationDarshna GuptaNo ratings yet
- Amta - Final Exams: Code: # Load The Toyotacorolla - CSVDocument13 pagesAmta - Final Exams: Code: # Load The Toyotacorolla - CSVShambhawi SinhaNo ratings yet
- Santander Customer Transaction Prediction Using R - PDFDocument171 pagesSantander Customer Transaction Prediction Using R - PDFShubham RajNo ratings yet
- 41 Perusse Alexander Aperusse PDFDocument7 pages41 Perusse Alexander Aperusse PDFAnurita MathurNo ratings yet
- Model Stacking Classification R AmsantacDocument14 pagesModel Stacking Classification R AmsantacAnonymous PZOnWGNo ratings yet
- M5 Prime LabDocument10 pagesM5 Prime LabpinkkittyjadeNo ratings yet
- Sakhil Assignment 02Document8 pagesSakhil Assignment 02JenishNo ratings yet
- R Workshop PART 2Document36 pagesR Workshop PART 2Izzue KashfiNo ratings yet
- CS5785 Homework 4: .PDF .Py .IpynbDocument5 pagesCS5785 Homework 4: .PDF .Py .IpynbAl TarinoNo ratings yet
- RSQLML Final Slide 15 June 2019 PDFDocument196 pagesRSQLML Final Slide 15 June 2019 PDFThanthirat ThanwornwongNo ratings yet
- 5 Ejercicio - Experimentación Con Los Modelos de Regresión Más Eficaces - Training - Microsoft Learn InglesDocument9 pages5 Ejercicio - Experimentación Con Los Modelos de Regresión Más Eficaces - Training - Microsoft Learn Inglesacxel david castillo casasNo ratings yet
- Final Project - Regression Models to Predict Home PricesDocument35 pagesFinal Project - Regression Models to Predict Home PricesCaio Henrique Konyosi Miyashiro100% (1)
- Homework 2: CS 178: Machine Learning: Spring 2020Document3 pagesHomework 2: CS 178: Machine Learning: Spring 2020Jonathan NguyenNo ratings yet
- Random Forest - Parameter - TuningDocument10 pagesRandom Forest - Parameter - TuningNit GossyNo ratings yet
- Auto Tuning Multiple Timeseries SARIMAX Model - With A Case Study and Detailed Code ExplanationDocument10 pagesAuto Tuning Multiple Timeseries SARIMAX Model - With A Case Study and Detailed Code ExplanationTeto ScheduleNo ratings yet
- Project +Sweta+Kumari+ +FRA+Milestone+2 July+2021Document18 pagesProject +Sweta+Kumari+ +FRA+Milestone+2 July+2021sweta kumari100% (1)
- Pair Trade For MatlabDocument4 pagesPair Trade For MatlabNukul SukuprakarnNo ratings yet
- Assignment - CarsData - Descriptive - EDA - Munjal - Exercise - Ipynb - ColaboratoryDocument6 pagesAssignment - CarsData - Descriptive - EDA - Munjal - Exercise - Ipynb - Colaboratoryprarabdhasharma98No ratings yet
- Nomor 3 UtsDocument6 pagesNomor 3 UtsNita FerdianaNo ratings yet
- Control Flow - LoopingDocument18 pagesControl Flow - LoopingNur SyazlianaNo ratings yet
- Regression Linaire Python Tome IIDocument10 pagesRegression Linaire Python Tome IIElisée TEGUENo ratings yet
- Long Term Energy Consumption Forecasting Using GeneticDocument44 pagesLong Term Energy Consumption Forecasting Using GeneticJyothimon ChandranNo ratings yet
- ML Assignemnt PDFDocument21 pagesML Assignemnt PDFEric NormanNo ratings yet
- Matrix Chain MultiplicationDocument20 pagesMatrix Chain MultiplicationHarsh Tibrewal100% (1)
- R Examples Comparing Random Forest Prediction ToolDocument9 pagesR Examples Comparing Random Forest Prediction ToolFlavio L M BarbozaNo ratings yet
- Bda AssignDocument15 pagesBda AssignAishwarya BiradarNo ratings yet
- Data Mining Problem 2 ReportDocument13 pagesData Mining Problem 2 ReportBabu ShaikhNo ratings yet
- CP 4Document2 pagesCP 4Ankita MishraNo ratings yet
- Assignments Walkthroughs and R Demo: W4290 Statistical Methods in Finance - Spring 2010 - Columbia UniversityDocument38 pagesAssignments Walkthroughs and R Demo: W4290 Statistical Methods in Finance - Spring 2010 - Columbia UniversitytsitNo ratings yet
- Data AnalyticsDocument31 pagesData AnalyticsSandeep TanwarNo ratings yet
- Types of Pruning TechniquesDocument10 pagesTypes of Pruning TechniquesSmriti PiyushNo ratings yet
- Fall 2023-2024 IE 451 Homework 3 SolutionsDocument15 pagesFall 2023-2024 IE 451 Homework 3 SolutionsAbdullah BingaziNo ratings yet
- S023Document4,538 pagesS023Abdullah BingaziNo ratings yet
- S028Document5,372 pagesS028Abdullah BingaziNo ratings yet
- S025Document7,033 pagesS025Abdullah BingaziNo ratings yet
- Chapter16 PDFDocument23 pagesChapter16 PDFAbdullah BingaziNo ratings yet
- My Demo DemoDocument19 pagesMy Demo DemoAlex LopezNo ratings yet
- Conditions For The Emergence of Life On The Early Earth: Summary and ReflectionsDocument15 pagesConditions For The Emergence of Life On The Early Earth: Summary and Reflectionsapi-3713202No ratings yet
- Project management software enables collaborationDocument4 pagesProject management software enables collaborationNoman AliNo ratings yet
- Advanced Guide To Digital MarketingDocument43 pagesAdvanced Guide To Digital MarketingArpan KarNo ratings yet
- 1 Catalyst FundamentalsDocument17 pages1 Catalyst FundamentalsSam AnuNo ratings yet
- James M. Buchanan - Why I, Too, Am Not A Conservative PDFDocument121 pagesJames M. Buchanan - Why I, Too, Am Not A Conservative PDFHeitor Berbigier Bandas100% (2)
- Database AwsDocument15 pagesDatabase AwsHareesha N GNo ratings yet
- Mental Status Examination FormatDocument7 pagesMental Status Examination FormatMala Rasaily100% (3)
- A Detailed Lesson Plan in (Teaching Science)Document8 pagesA Detailed Lesson Plan in (Teaching Science)Evan Jane Jumamil67% (3)
- Economics of Power GenerationDocument32 pagesEconomics of Power GenerationKimberly Jade VillaganasNo ratings yet
- Jurnal Mira FixDocument16 pagesJurnal Mira Fixarisanto micoNo ratings yet
- WET - AT - AT - 003 - ENG - Manuale Di Istruzione Tenute LubrificateDocument15 pagesWET - AT - AT - 003 - ENG - Manuale Di Istruzione Tenute LubrificateNadia WilsonNo ratings yet
- Ffective Riting Kills: Training & Discussion OnDocument37 pagesFfective Riting Kills: Training & Discussion OnKasi ReddyNo ratings yet
- Analisis Kinerja Turbin Uap Unit 3 BerdasarkanDocument12 pagesAnalisis Kinerja Turbin Uap Unit 3 BerdasarkanfebriansyahNo ratings yet
- Assignments - 2017 09 15 182103 - PDFDocument49 pagesAssignments - 2017 09 15 182103 - PDFMena AlzahawyNo ratings yet
- I3rc Insights Pvt. Ltd. India - Company Credentials PDFDocument28 pagesI3rc Insights Pvt. Ltd. India - Company Credentials PDFManoj Kumar JhaNo ratings yet
- Omega: Mahdi Alinaghian, Nadia ShokouhiDocument15 pagesOmega: Mahdi Alinaghian, Nadia ShokouhiMohcine ES-SADQINo ratings yet
- Horizontal Projectile MotionDocument17 pagesHorizontal Projectile MotionMark BagamaspadNo ratings yet
- SAQ Ans 6Document3 pagesSAQ Ans 6harshanauocNo ratings yet
- Method Overloading in JavaDocument6 pagesMethod Overloading in JavaPrerna GourNo ratings yet
- Mercer Role and Job Analysis InfoDocument3 pagesMercer Role and Job Analysis InfojehaniaNo ratings yet
- Bachelor of Arts (Psychology HR Management) Y3 V2Document1 pageBachelor of Arts (Psychology HR Management) Y3 V2Kenny sylvainNo ratings yet
- RRT LH: Gt'R:Ut (TLDocument75 pagesRRT LH: Gt'R:Ut (TLkl equipmentNo ratings yet
- Standard JKR Spec For Bridge LoadingDocument5 pagesStandard JKR Spec For Bridge LoadingHong Rui ChongNo ratings yet
- Value YourselfDocument7 pagesValue YourselfTalha KhalidNo ratings yet
- ErgonomicsDocument15 pagesErgonomicsdtmNo ratings yet
- 2017 Expert Packet Workshop V3 + ExerciseDocument268 pages2017 Expert Packet Workshop V3 + ExerciseJeya ChandranNo ratings yet
- 1675.does Concrete Lighten or Change Color As It DriesDocument5 pages1675.does Concrete Lighten or Change Color As It DriestvrNo ratings yet
- Unit 5: Structural Modelling: Block II: From Analysis To DesignDocument76 pagesUnit 5: Structural Modelling: Block II: From Analysis To DesignPatrick FarahNo ratings yet
- Material 01 - Human-Computer InteractionDocument8 pagesMaterial 01 - Human-Computer InteractionIlangmi NutolangNo ratings yet