You might also like
- Antenna Azimuth Position Control System Using PIDDocument12 pagesAntenna Azimuth Position Control System Using PIDAyumuNo ratings yet
- Time Lapse Approach to Monitoring Oil, Gas, and CO2 Storage by Seismic MethodsFrom EverandTime Lapse Approach to Monitoring Oil, Gas, and CO2 Storage by Seismic MethodsNo ratings yet
- Survey Manual-Sm01 PDFDocument408 pagesSurvey Manual-Sm01 PDFAkbar RezaNo ratings yet
- Saikiran Data - Engineer ResumeDocument7 pagesSaikiran Data - Engineer Resumeramu_uppadaNo ratings yet
- IT5409 Ch7 Part1 Object Detection v2Document97 pagesIT5409 Ch7 Part1 Object Detection v2Bui Minh DucNo ratings yet
- Convolutional Neural Networks in PythonDocument141 pagesConvolutional Neural Networks in PythonAnonymous rsGzBBiqk100% (2)
- Pedersen Detection of Marine Animals in A New Underwater Dataset With CVPRW 2019 PaperDocument9 pagesPedersen Detection of Marine Animals in A New Underwater Dataset With CVPRW 2019 Papermahalekshmi anilNo ratings yet
- Fish Survival Prediction in An Aquatic Environment Using Random Forest ModelDocument9 pagesFish Survival Prediction in An Aquatic Environment Using Random Forest ModelIAES IJAINo ratings yet
- Spatio-Temporal Variability of The Habitat SuitabilityDocument12 pagesSpatio-Temporal Variability of The Habitat SuitabilityagustinasiiskaaNo ratings yet
- Fishes 08 00514Document17 pagesFishes 08 00514jlassi wadiiNo ratings yet
- Technical and Financial PROPOSAL FOR THE REHABILITATION OF MARINE AND COASTAL HABITATS of Saudi Arabia Ver 2Document17 pagesTechnical and Financial PROPOSAL FOR THE REHABILITATION OF MARINE AND COASTAL HABITATS of Saudi Arabia Ver 2Emad AbduallahNo ratings yet
- Analysis of Trawl Data Sample From Different AnglesDocument7 pagesAnalysis of Trawl Data Sample From Different AnglesPETER BAAHNo ratings yet
- DPI Tongkol PDFDocument8 pagesDPI Tongkol PDFGhufairah 23No ratings yet
- Acoustic Assessment of Squid StocksDocument18 pagesAcoustic Assessment of Squid StocksJohn KaruwalNo ratings yet
- How Many Fish in A Tank? Constructing An Automated Fish Counting System by Using PTV AnalysisDocument5 pagesHow Many Fish in A Tank? Constructing An Automated Fish Counting System by Using PTV AnalysisMICHAEL HERZEN CONDE GARCIANo ratings yet
- Ocean & Coastal ManagementDocument9 pagesOcean & Coastal ManagementsyahaliNo ratings yet
- Schilletal 2006 Oyster MappingDocument91 pagesSchilletal 2006 Oyster MappingSteve SchillNo ratings yet
- Lee K, Mukai T, Lee DJ, Iida K. 2014Document30 pagesLee K, Mukai T, Lee DJ, Iida K. 2014osemetmil subdisNo ratings yet
- 1 s2.0 S0308597X22000628 MainDocument17 pages1 s2.0 S0308597X22000628 Mainjagtapdevkinandan60No ratings yet
- Mobilenet Ikan v3Document13 pagesMobilenet Ikan v3dainsyah dainNo ratings yet
- 13 PageDocument13 pages13 Pageabourifa hananeNo ratings yet
- FSZ 025Document13 pagesFSZ 025jagtapdevkinandan60No ratings yet
- Fish 1Document7 pagesFish 1Zachariah OverauxNo ratings yet
- 269 Burrows MT Et AlDocument52 pages269 Burrows MT Et Alapi-708169763No ratings yet
- Citi 2020Document10 pagesCiti 2020Fernando ChavezNo ratings yet
- MPA FishMApp A Citizen Science App That Simplifies Monitoring of Coral Reef Fish Density and Biomass in Marine Protected AreasDocument15 pagesMPA FishMApp A Citizen Science App That Simplifies Monitoring of Coral Reef Fish Density and Biomass in Marine Protected AreasJefferd Jhon TalibongNo ratings yet
- Live Fish Species Classification in Underwater ImaDocument15 pagesLive Fish Species Classification in Underwater Imaabourifa hananeNo ratings yet
- CSE 444 Detection and Recognition of Bangladeshi Fishes Using Surf and Convolutional Neural NetworkDocument7 pagesCSE 444 Detection and Recognition of Bangladeshi Fishes Using Surf and Convolutional Neural NetworkAbirNo ratings yet
- Technical Proposal 1Document8 pagesTechnical Proposal 1Rahul kundiyaNo ratings yet
- IJMEIR 04211840000002 Ibnu KhuldunDocument10 pagesIJMEIR 04211840000002 Ibnu KhuldunIbnu MKNo ratings yet
- Klemas, 2013 - Fisheries Applications of Remote Sensing An OverviewDocument13 pagesKlemas, 2013 - Fisheries Applications of Remote Sensing An OverviewFrancisko NainggolanNo ratings yet
- Chapter 2Document51 pagesChapter 2nirmala periasamyNo ratings yet
- Limnology Ocean Methods - 2016 - Salman - Fish Species Classification in Unconstrained Underwater Environments Based OnDocument16 pagesLimnology Ocean Methods - 2016 - Salman - Fish Species Classification in Unconstrained Underwater Environments Based Onjagtapdevkinandan60No ratings yet
- Sensors 21 04649Document19 pagesSensors 21 04649ARSHIE FATHREZZANo ratings yet
- Sensors: Underwater Holographic Sensor For Plankton Studies in Situ Including Accompanying MeasurementsDocument19 pagesSensors: Underwater Holographic Sensor For Plankton Studies in Situ Including Accompanying MeasurementsQuý HuỳnhNo ratings yet
- Observing Incidental Harbour Porpoise: Phocoena Phocoena Bycatch by Remote Electronic MonitoringDocument9 pagesObserving Incidental Harbour Porpoise: Phocoena Phocoena Bycatch by Remote Electronic MonitoringsheriefmuhammedNo ratings yet
- Remotesensing 10 01604Document23 pagesRemotesensing 10 01604Jack Robert LabradorNo ratings yet
- Application of Knowledge-Based Expert System Model For Fishing Ground Prediction in The Tropical AreaDocument8 pagesApplication of Knowledge-Based Expert System Model For Fishing Ground Prediction in The Tropical AreaRiskahMappileNo ratings yet
- Digital Transformation in Industrial FishingDocument11 pagesDigital Transformation in Industrial FishingJorge Victor Mayhuasca GuerraNo ratings yet
- The Classification of Upwelling Indicators Base OnDocument13 pagesThe Classification of Upwelling Indicators Base OnskyNo ratings yet
- Yusup 2020 IOP Conf. Ser. Earth Environ. Sci. 429 012046Document9 pagesYusup 2020 IOP Conf. Ser. Earth Environ. Sci. 429 012046Rhaiza PabelloNo ratings yet
- Potential Fishing Zone Estimation by Rough Cluster PredictionsDocument6 pagesPotential Fishing Zone Estimation by Rough Cluster Predictionsvineeth sagarNo ratings yet
- 2000-Santos FR PDFDocument20 pages2000-Santos FR PDFJohn KaruwalNo ratings yet
- Competing Conservation Objectives For Predators and Prey: Estimating Killer Whale Prey Requirements For Chinook SalmonDocument9 pagesCompeting Conservation Objectives For Predators and Prey: Estimating Killer Whale Prey Requirements For Chinook Salmonabnaod5363No ratings yet
- Fish Growth ModellingDocument56 pagesFish Growth ModellinggiuseppegnrNo ratings yet
- Implementation of Data Mining Analysis To Determine The Tuna Fishing Zone Using DBSCAN AlgorithmDocument6 pagesImplementation of Data Mining Analysis To Determine The Tuna Fishing Zone Using DBSCAN AlgorithmNur AdliNo ratings yet
- 1.1.b.3 - Fishing Season and Participatory Mapping of The Fishing GroundDocument9 pages1.1.b.3 - Fishing Season and Participatory Mapping of The Fishing GroundPaulangan1975No ratings yet
- NW Siquijor Biodiversity SurveyFINALDocument14 pagesNW Siquijor Biodiversity SurveyFINALENRMO LCCNo ratings yet
- 2017 Filipponi Et Al MultiTemp2017 WatermarkDocument9 pages2017 Filipponi Et Al MultiTemp2017 WatermarkDaniel Mateo Rangel ReséndezNo ratings yet
- Dao2013 12Document7 pagesDao2013 12Javier, Kristine MarieNo ratings yet
- Current and Emerging Statistical Techniques For Aquatic Telemetry Data: A Guide To Analyzing Spatially Discrete Animal DetectionsDocument41 pagesCurrent and Emerging Statistical Techniques For Aquatic Telemetry Data: A Guide To Analyzing Spatially Discrete Animal DetectionsEvie CraigNo ratings yet
- Aquaculture and Wave Energy in Puerto Rico - Summary - 6.30.23Document3 pagesAquaculture and Wave Energy in Puerto Rico - Summary - 6.30.23CORALationsNo ratings yet
- Whale Counting in Satellite and Aerial Images With Deep LearningDocument12 pagesWhale Counting in Satellite and Aerial Images With Deep LearningrobertNo ratings yet
- 1 s2.0 S016974392300309X MainDocument8 pages1 s2.0 S016974392300309X MainTeddy BubsNo ratings yet
- Thesis Marta RamirezDocument140 pagesThesis Marta RamirezPelos FuentesNo ratings yet
- Jurnal KelautanDocument25 pagesJurnal KelautanNani SuryaniNo ratings yet
- 349-Article Text-2470-1-6-20221126Document14 pages349-Article Text-2470-1-6-20221126mustasimNo ratings yet
- Review Article: Modeling and Analysis in Marine Big Data: Advances and ChallengesDocument14 pagesReview Article: Modeling and Analysis in Marine Big Data: Advances and ChallengesNurul Huda AnggraeniNo ratings yet
- Shark Density Modelling - 2014Document10 pagesShark Density Modelling - 2014Yann FleatwoodNo ratings yet
- Dunn2009 BoatsDocument9 pagesDunn2009 BoatsEvgueni SapojnikovNo ratings yet
- SPE 65150 Discussion On Integrating Monitoring Data Into The Reservoir Management ProcessDocument10 pagesSPE 65150 Discussion On Integrating Monitoring Data Into The Reservoir Management ProcessJanittze CastilloNo ratings yet
- DepomodDocument68 pagesDepomodNikita PuertoNo ratings yet
- Developing OBIS Into A Tool To Provide Reliable Estimates of Population Indices For Marine Species From Research Trawl SurveysDocument6 pagesDeveloping OBIS Into A Tool To Provide Reliable Estimates of Population Indices For Marine Species From Research Trawl SurveysChakma NhikiNo ratings yet
- Deep LearningDocument39 pagesDeep LearningwilliamNo ratings yet
- Adventures in Data Analysis: A Systematic Review of Deep Learning Techniques For Pattern Recognition in Cyber Physical Social SystemsDocument65 pagesAdventures in Data Analysis: A Systematic Review of Deep Learning Techniques For Pattern Recognition in Cyber Physical Social SystemsAli Asghar Pourhaji KazemNo ratings yet
- EPSM Syllabus 290419Document12 pagesEPSM Syllabus 290419hristina velickovskaNo ratings yet
- Critical Systems Thinking: Beyond The FragmentsDocument17 pagesCritical Systems Thinking: Beyond The FragmentsFacicNo ratings yet
- Artificial Intelligence Illuminated (2) - 46-50Document5 pagesArtificial Intelligence Illuminated (2) - 46-50ИллаNo ratings yet
- Production Ranking Systems: A Review: Murium Iqbal Nishan Subedi Kamelia AryafarDocument10 pagesProduction Ranking Systems: A Review: Murium Iqbal Nishan Subedi Kamelia Aryafar정윤호No ratings yet
- Lecture Notes - Optimal Control (LQG, MPC)Document76 pagesLecture Notes - Optimal Control (LQG, MPC)mindthomasNo ratings yet
- DMBI Exp1: Introduction To WEKA ToolDocument6 pagesDMBI Exp1: Introduction To WEKA ToolAnkitNo ratings yet
- Students' Performance Prediction Using Deep Neural Network: Bendangnuksung and Dr. Prabu PDocument6 pagesStudents' Performance Prediction Using Deep Neural Network: Bendangnuksung and Dr. Prabu PHiếu Nguyễn ChíNo ratings yet
- Dbms Lab FileDocument46 pagesDbms Lab FileSaksham SaxenaNo ratings yet
- Neural Network ReportDocument27 pagesNeural Network ReportSiddharth PatelNo ratings yet
- Intelligent Agent AIMA ExercisesDocument5 pagesIntelligent Agent AIMA Exercisesrafeak rafeakNo ratings yet
- Natural Language Processing (NLP)Document63 pagesNatural Language Processing (NLP)Saif JuttNo ratings yet
- CrsDocument10 pagesCrsAkNo ratings yet
- EEG-Based Age and Gender Prediction Using Deep BLSTM-LSTM Network ModelDocument8 pagesEEG-Based Age and Gender Prediction Using Deep BLSTM-LSTM Network ModelarifNo ratings yet
- 1909 01709 PDFDocument18 pages1909 01709 PDFDHIRAJ DILLEP S NAIRNo ratings yet
- DatabaseDocument8 pagesDatabaseGideon BusiaNo ratings yet
- Word2Vec DemoDocument12 pagesWord2Vec DemoGia Ân Ngô TriệuNo ratings yet
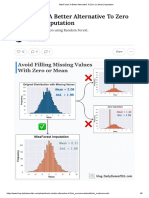
- MissForest - A Better Alternative To Zero (Or Mean) ImputationDocument8 pagesMissForest - A Better Alternative To Zero (Or Mean) ImputationPaulo RicardoNo ratings yet
- Kuliah 1 PendahuluanDocument39 pagesKuliah 1 PendahuluanTeddy EkatamtoNo ratings yet
- Assignment2AI - 2023 Moderated2Document11 pagesAssignment2AI - 2023 Moderated2minajadritNo ratings yet
- Project Weekly Diary 21-24Document10 pagesProject Weekly Diary 21-24adityakerimane108No ratings yet
- Fuzzy LogicDocument24 pagesFuzzy LogicAnup Kumar SarkerNo ratings yet
- Dyslexia Prediction Using Machine LearningDocument9 pagesDyslexia Prediction Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Understanding Self-Supervised Features For Learning Unsupervised Instance SegmentationDocument12 pagesUnderstanding Self-Supervised Features For Learning Unsupervised Instance SegmentationdrewqNo ratings yet
- Computer ScienceDocument10 pagesComputer ScienceLudwigVonBeethovenNo ratings yet