You might also like
- Performance Tuning Guide For Mellanox Network Adapters Rev 1 0Document13 pagesPerformance Tuning Guide For Mellanox Network Adapters Rev 1 0mcclaink06No ratings yet
- Red Hat Enterprise Linux-7-Virtualization Tuning and Optimization Guide-En-USDocument42 pagesRed Hat Enterprise Linux-7-Virtualization Tuning and Optimization Guide-En-USApoorva BhattNo ratings yet
- Alphavm Um 1 3 9 Windows PDFDocument22 pagesAlphavm Um 1 3 9 Windows PDFMan CangkulNo ratings yet
- Intergraph Smartplant Review 64 Bit WhitepapersDocument12 pagesIntergraph Smartplant Review 64 Bit WhitepapersSomnath LahaNo ratings yet
- Installation Requirements: For System Providers and TenantsDocument37 pagesInstallation Requirements: For System Providers and TenantsDedis CorpNo ratings yet
- Gigabyte GA - 586UX User ManualDocument59 pagesGigabyte GA - 586UX User Manualniko99No ratings yet
- All-Products - Esuprt - Desktop - Esuprt - Legacydt - Poweredge-C5230 - Reference Guide - En-UsDocument74 pagesAll-Products - Esuprt - Desktop - Esuprt - Legacydt - Poweredge-C5230 - Reference Guide - En-Usfarkli88No ratings yet
- Alphavm For Windows User Manual: Date: 28-Feb-2020 Author: Artem Alimarin © 2020, EmuvmDocument39 pagesAlphavm For Windows User Manual: Date: 28-Feb-2020 Author: Artem Alimarin © 2020, Emuvmabdallah tebibNo ratings yet
- IBM SUSE 12 SP2 Device CommandsDocument748 pagesIBM SUSE 12 SP2 Device Commandsdean-sti0% (1)
- Bitfusion Perf Best PracticesDocument15 pagesBitfusion Perf Best PracticesTomáš ZatoNo ratings yet
- Intel® Desktop Boards DZ77GA-70K, DZ77RE-75K: Performance Tuning GuideDocument35 pagesIntel® Desktop Boards DZ77GA-70K, DZ77RE-75K: Performance Tuning Guidecta5No ratings yet
- Belkin Manual PDFDocument43 pagesBelkin Manual PDFKian GonzagaNo ratings yet
- Efficient CLI PDFDocument422 pagesEfficient CLI PDFestwdaNo ratings yet
- Realtime LinuxDocument27 pagesRealtime LinuxMohammed PublicationsNo ratings yet
- EMC ECS (Elastic Cloud Storage) Architectural Guide v2.xDocument21 pagesEMC ECS (Elastic Cloud Storage) Architectural Guide v2.xtood galyNo ratings yet
- XCAL LTE Qualcomm Features v3.2 (Rev.3)Document38 pagesXCAL LTE Qualcomm Features v3.2 (Rev.3)esakNo ratings yet
- Beowulf SetupDocument46 pagesBeowulf SetupBiswa DuttaNo ratings yet
- PSLV1NSB QIP CelerraNS600 Basic 030315chDocument34 pagesPSLV1NSB QIP CelerraNS600 Basic 030315chDavid LynxNo ratings yet
- KM 7222us Rev10netscanDocument232 pagesKM 7222us Rev10netscanRaul Sanchez RoyNo ratings yet
- Opensuse: 11.4 Virtualization With KVMDocument174 pagesOpensuse: 11.4 Virtualization With KVMciaociaociao3100% (1)
- Book - KVM en PDFDocument174 pagesBook - KVM en PDFbonilla03No ratings yet
- ROBO-6711VGA: Single Board ComputerDocument70 pagesROBO-6711VGA: Single Board ComputerJuan Carlos GoyzuetaNo ratings yet
- Acano VM White PaperDocument16 pagesAcano VM White PaperNoCWNo ratings yet
- AKCPro Server HTML ManualDocument391 pagesAKCPro Server HTML ManualRoberto DiazNo ratings yet
- Ug897 Vivado Sysgen UserDocument226 pagesUg897 Vivado Sysgen UserJessica RossNo ratings yet
- Acer Aspire T180 MB. Manual WillerDocument83 pagesAcer Aspire T180 MB. Manual WillerWiller Layonel UrriolaNo ratings yet
- Docu56210 XtremIO Host Configuration GuideDocument162 pagesDocu56210 XtremIO Host Configuration GuideqingyangsNo ratings yet
- Asu ManualDocument128 pagesAsu ManualpowerbitliveNo ratings yet
- Tx300 s3 OptionsDocument124 pagesTx300 s3 OptionsJorge Duran HerasNo ratings yet
- ZEN 3.5 (Blue Edition) - Installation GuideDocument34 pagesZEN 3.5 (Blue Edition) - Installation Guidehaze.eslemNo ratings yet
- Virtualization Xeon Core Count Impacts Performance PaperDocument10 pagesVirtualization Xeon Core Count Impacts Performance Paperpro_naveenNo ratings yet
- Net G PDFDocument74 pagesNet G PDFremote controlNo ratings yet
- Benchmarking The 3ware 9000 Controller Using Linux Kernel 2.6Document24 pagesBenchmarking The 3ware 9000 Controller Using Linux Kernel 2.6ElvedinCokićNo ratings yet
- Bl8X0C I2: Overview, Setup, Troubleshooting, and Various Methods To Install OpenvmsDocument23 pagesBl8X0C I2: Overview, Setup, Troubleshooting, and Various Methods To Install OpenvmsFabrizio GiordanoNo ratings yet
- EPO Deep Command 1.5.0 Product GuideDocument129 pagesEPO Deep Command 1.5.0 Product GuidedanipajbrNo ratings yet
- Simplified Remote Restart White PaperDocument33 pagesSimplified Remote Restart White Paperch herlinNo ratings yet
- Nova-8890 V2.2Document49 pagesNova-8890 V2.2Rafael SoaresNo ratings yet
- Xts - Cms (Version 3.24.9)Document129 pagesXts - Cms (Version 3.24.9)Yeiser Martines MoscoteNo ratings yet
- CLIUGDocument272 pagesCLIUGJason TangNo ratings yet
- WP VMW Nexus1000v VSphere4 DeploymentDocument27 pagesWP VMW Nexus1000v VSphere4 DeploymentnunomgtorresNo ratings yet
- Hikcentral Professional 1.4.2 Quick Start Guide 20190905Document43 pagesHikcentral Professional 1.4.2 Quick Start Guide 20190905Ricardo MNo ratings yet
- Advantech SKY Series Industrial Server Solutions: High-Performance, Reliable, and Flexible With Product Longevity SupportDocument44 pagesAdvantech SKY Series Industrial Server Solutions: High-Performance, Reliable, and Flexible With Product Longevity SupportSentaNo ratings yet
- IBM Total Storage Productivity Center For Replication On Linux Sg247411Document248 pagesIBM Total Storage Productivity Center For Replication On Linux Sg247411bupbechanhNo ratings yet
- System BIOS For IBM PC - XT - AT Computers and CompatiblesDocument554 pagesSystem BIOS For IBM PC - XT - AT Computers and CompatiblesАнатолий БатракинNo ratings yet
- Service Manual Acer TravelMate 3000 PDFDocument101 pagesService Manual Acer TravelMate 3000 PDFmohzgoNo ratings yet
- IPCAgility OnPremisesInstallationandUpgradeGuide v32Document76 pagesIPCAgility OnPremisesInstallationandUpgradeGuide v32HatemNo ratings yet
- Configuring Your Computer and Network Adapters For Best Performance Application NoteDocument13 pagesConfiguring Your Computer and Network Adapters For Best Performance Application NotekeoxxNo ratings yet
- Nano-7270 V1.0Document40 pagesNano-7270 V1.0Rafael SoaresNo ratings yet
- F120 Configure Details Good Startup BookDocument208 pagesF120 Configure Details Good Startup Bookdayasankar1198No ratings yet
- Troubleshooting High CPU Utilization On Cisco Routers............................................................................... 1Document10 pagesTroubleshooting High CPU Utilization On Cisco Routers............................................................................... 1german12No ratings yet
- Emulex® NVMe Over Fibre Channel - User Guide R12.0Document49 pagesEmulex® NVMe Over Fibre Channel - User Guide R12.0Y.FNo ratings yet
- Technical Tips and Tricks RevEDocument106 pagesTechnical Tips and Tricks RevEGrigore UifaleanNo ratings yet
- TEMS Investigation 14 1 Getting Started Manual PDFDocument130 pagesTEMS Investigation 14 1 Getting Started Manual PDFHailu TsegaNo ratings yet
- KVM Best PracticesDocument44 pagesKVM Best PracticesxnewsNo ratings yet
- CnMaestro On-Premises Quick Start 1.4.0Document38 pagesCnMaestro On-Premises Quick Start 1.4.0Muhammad Syafriel Cupriel SiCuphuNo ratings yet
- Acer 5670 Service ManualDocument135 pagesAcer 5670 Service ManualMetalFrostNo ratings yet
- Alphaserver1000a ServiceguideDocument200 pagesAlphaserver1000a Serviceguidests100No ratings yet
- Nintendo 64 Architecture: Architecture of Consoles: A Practical Analysis, #8From EverandNintendo 64 Architecture: Architecture of Consoles: A Practical Analysis, #8No ratings yet
- Topics: InterruptsDocument11 pagesTopics: InterruptsyokeswaranNo ratings yet
- MSI P35 Platinum Combo ManualDocument122 pagesMSI P35 Platinum Combo ManualBobapatatasNo ratings yet
- Red Hat Enterprise Linux 7: Virtualization Tuning and Optimization GuideDocument61 pagesRed Hat Enterprise Linux 7: Virtualization Tuning and Optimization GuidechakrikollaNo ratings yet
- Intel 3 Series Express Chipset Family: DatasheetDocument438 pagesIntel 3 Series Express Chipset Family: DatasheetGabrielNo ratings yet
- Jinesh (Real Time Systems in Linux)Document27 pagesJinesh (Real Time Systems in Linux)yuben josephNo ratings yet
- ACPIDocument501 pagesACPISteve SmallNo ratings yet
- Boot Procedure For REDocument12 pagesBoot Procedure For RESivaraman AlagappanNo ratings yet
- Microprocessors (CSE 206) (Makeup)Document2 pagesMicroprocessors (CSE 206) (Makeup)Vishal VimalkumarNo ratings yet
- Ig31k-M7s Bios 100719Document35 pagesIg31k-M7s Bios 100719hardcastNo ratings yet
- Hypervisor Top Level Functional SpecificationDocument242 pagesHypervisor Top Level Functional SpecificationLibardo SanabriaNo ratings yet
- 7512v1.1 (G52-75121X2) (P45 Neo2) PDFDocument143 pages7512v1.1 (G52-75121X2) (P45 Neo2) PDFZeljko Krivokuca100% (1)
- Fujitsu Siemens BIOSDocument131 pagesFujitsu Siemens BIOSzabavkoNo ratings yet
- Revision Guide For AMD Athlon 64 and AMD Opteron Processors: Publication # Revision: Issue DateDocument85 pagesRevision Guide For AMD Athlon 64 and AMD Opteron Processors: Publication # Revision: Issue DateSajith Ranjeewa SenevirathneNo ratings yet
- IoregDocument104 pagesIoregliqsquidNo ratings yet
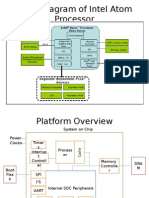
- Block Diagram of Intel Atom ProcessorDocument23 pagesBlock Diagram of Intel Atom Processorfestio94No ratings yet
- 651C-M (1.0)Document68 pages651C-M (1.0)Fatima OliveiraNo ratings yet
- Best Practices When Deploying Microsoft Windows Server On The HP ProLiant DL980Document32 pagesBest Practices When Deploying Microsoft Windows Server On The HP ProLiant DL980Balram AggarwalNo ratings yet
- MSI - Neo K9AG-Neo2Digital - 7368v1.0 (G52-73681X1)Document103 pagesMSI - Neo K9AG-Neo2Digital - 7368v1.0 (G52-73681X1)djdanny89No ratings yet
- A Tour Beyond BIOS Memory Map and Practices in UEFI BIOS V2Document40 pagesA Tour Beyond BIOS Memory Map and Practices in UEFI BIOS V2memoarfaaNo ratings yet
- Ig41s-M7s Bios 101213 PDFDocument33 pagesIg41s-M7s Bios 101213 PDFАнтон МальченкоNo ratings yet
- RTX64RuntimeInstallGuide PDFDocument48 pagesRTX64RuntimeInstallGuide PDFDavid JacquesNo ratings yet
- Rome Tuning Guide PDFDocument25 pagesRome Tuning Guide PDFAjay KrishnaNo ratings yet
- RTAI User Manual-3.4Document41 pagesRTAI User Manual-3.4oscar201140No ratings yet
- VT Directed Io SpecDocument297 pagesVT Directed Io SpechobomanNo ratings yet
- ReportDocument34 pagesReportJunior Nunes OliveiraNo ratings yet
- VBoxDocument51 pagesVBoxhessam.jkr7No ratings yet
- Embedded LinuxDocument466 pagesEmbedded Linuxronoski100% (1)
- 7642v1.0 (G52 76421X1) (890GXM G65)Document110 pages7642v1.0 (G52 76421X1) (890GXM G65)Nicolas BertoaNo ratings yet
- Administrator's Guide For The AT&T Global Network Client For LinuxDocument10 pagesAdministrator's Guide For The AT&T Global Network Client For LinuxPippolone PaprunskiNo ratings yet