You might also like
- Estimating Value-Added Tax Using a Supply and Use Framework: The ADB National Accounts Statistics Value-Added Tax ModelFrom EverandEstimating Value-Added Tax Using a Supply and Use Framework: The ADB National Accounts Statistics Value-Added Tax ModelNo ratings yet
- Project On Quantitative Techniques of Business StaDocument24 pagesProject On Quantitative Techniques of Business Starajat1311No ratings yet
- Value For Money: FrameworkDocument37 pagesValue For Money: FrameworkKanesu GaneshamoorthyNo ratings yet
- Its RR 01 - 01Document106 pagesIts RR 01 - 01odcardozoNo ratings yet
- CHAPTER THREE JoyDocument5 pagesCHAPTER THREE JoyRaytone Tonnie MainaNo ratings yet
- A Dea Approach To Regional Development: Munich Personal Repec ArchiveDocument33 pagesA Dea Approach To Regional Development: Munich Personal Repec ArchiveValentina SocolNo ratings yet
- The Cost Benefit Analysis For The Concept of A Smart City: How To Measure The E Smart Solutions?Document17 pagesThe Cost Benefit Analysis For The Concept of A Smart City: How To Measure The E Smart Solutions?lakshitaNo ratings yet
- Purchasing Management Master ThesisDocument8 pagesPurchasing Management Master ThesisAllison Koehn100% (2)
- Goods Services: Market SectorDocument7 pagesGoods Services: Market SectorOmei KhairiNo ratings yet
- Project Management Hitesh Verma (50614901717) Nna G Shift1 Sec BDocument20 pagesProject Management Hitesh Verma (50614901717) Nna G Shift1 Sec Banamika vermaNo ratings yet
- Statistical AnalysisDocument36 pagesStatistical AnalysisAmmar HassanNo ratings yet
- ScienceDirect Citations 1693286341478Document9 pagesScienceDirect Citations 1693286341478Jose PumaNo ratings yet
- FINAL - Data AnalysisDocument13 pagesFINAL - Data AnalysisaunimapNo ratings yet
- Sustainability 09 01714Document18 pagesSustainability 09 01714Maria Gabriela PopaNo ratings yet
- Exploring Digitalization's Impact On Economic Growth - Assessing Factors and Policy Implications in Emerging Economies.Document5 pagesExploring Digitalization's Impact On Economic Growth - Assessing Factors and Policy Implications in Emerging Economies.dennisNo ratings yet
- Plagiarism CheckDocument7 pagesPlagiarism CheckVishal SharmaNo ratings yet
- "Project Appraisal of Micro, Small and Medium Enterprises" State Bank of HyderabadDocument13 pages"Project Appraisal of Micro, Small and Medium Enterprises" State Bank of HyderabadPalle VinayNo ratings yet
- Progress Report Mini ProjectDocument4 pagesProgress Report Mini ProjectNUR DINI HUDANo ratings yet
- Article (Business Industry)Document8 pagesArticle (Business Industry)Aziz Ibn MusahNo ratings yet
- Estimating Local Consumer Market Size For MarketinDocument9 pagesEstimating Local Consumer Market Size For MarketinChannuNo ratings yet
- Project-Proposal - Sample 2Document24 pagesProject-Proposal - Sample 2phanmaithuyvyNo ratings yet
- Galimkair Mutanov Mathematical Methods and Models in Economic Planning, Management and BudgetingDocument364 pagesGalimkair Mutanov Mathematical Methods and Models in Economic Planning, Management and BudgetingyyscribdNo ratings yet
- A Composite Index Model For Evaluating Used Equipment: C.O. Anyaeche, and E. B. OmoniyiDocument4 pagesA Composite Index Model For Evaluating Used Equipment: C.O. Anyaeche, and E. B. OmoniyiIOSRJEN : hard copy, certificates, Call for Papers 2013, publishing of journalNo ratings yet
- OR AssignmentDocument12 pagesOR AssignmentSkyler HelinNo ratings yet
- Quantitative Techniques in Management (NEW)Document41 pagesQuantitative Techniques in Management (NEW)alokthakurNo ratings yet
- I Will Draw A PESTEL Analysis DiagramDocument8 pagesI Will Draw A PESTEL Analysis DiagramTarif HossanNo ratings yet
- Cumulative Correspondence Analysis To Improve The Public Train TransportDocument10 pagesCumulative Correspondence Analysis To Improve The Public Train TransportJaime Enrique ParionaNo ratings yet
- CC Cost WP PDFDocument14 pagesCC Cost WP PDFMina AminNo ratings yet
- Smart City Literature ReviewDocument8 pagesSmart City Literature Reviewafmzethlgpqoyb100% (1)
- (FHWA, 2008) Pavement Management Systems Peer Exchange Program ReportDocument42 pages(FHWA, 2008) Pavement Management Systems Peer Exchange Program Reportali faresNo ratings yet
- Impact Study Methodology PDFDocument63 pagesImpact Study Methodology PDFAfifah Nur ImanNo ratings yet
- car price predictionDocument18 pagescar price predictionRahul mishraNo ratings yet
- Sustainability MarketDocument6 pagesSustainability Marketchandrasena217No ratings yet
- The Price Prediction For Used Cars Using Multiple Linear Regression ModelDocument6 pagesThe Price Prediction For Used Cars Using Multiple Linear Regression ModelIJRASETPublicationsNo ratings yet
- The Tourism Forecasting Competition: George Athanasopoulos, Rob J Hyndman, Haiyan Song, Doris C WuDocument36 pagesThe Tourism Forecasting Competition: George Athanasopoulos, Rob J Hyndman, Haiyan Song, Doris C WuTin SakanNo ratings yet
- MMRDocument31 pagesMMRVinay HotkarNo ratings yet
- Travel Behavior Segmentation Using Attitudinal DataDocument29 pagesTravel Behavior Segmentation Using Attitudinal DataMarhadi LeonchiNo ratings yet
- What Role Do Advanced Production Services Play in Enhancing The Competitiveness and Added Value of Countries That Participate in Global Value Chains?Document17 pagesWhat Role Do Advanced Production Services Play in Enhancing The Competitiveness and Added Value of Countries That Participate in Global Value Chains?Kolin OtaruNo ratings yet
- Value chain analysis stepsDocument3 pagesValue chain analysis stepsErika PetersonNo ratings yet
- Demand Analysis PPT MbaDocument24 pagesDemand Analysis PPT MbaBabasab Patil (Karrisatte)0% (1)
- Moving Average ThesisDocument8 pagesMoving Average Thesisdonnakuhnsbellevue100% (2)
- Systems DynamicsDocument10 pagesSystems DynamicsKapil Kumar GavskerNo ratings yet
- Chain Analysis Tool (Cat)Document47 pagesChain Analysis Tool (Cat)Kalpesh RathodNo ratings yet
- Traffic Impact AssesmentDocument7 pagesTraffic Impact AssesmentDyanAugustineNo ratings yet
- Simulación Urbana y Redes BayesianasDocument43 pagesSimulación Urbana y Redes BayesianasUrbam RedNo ratings yet
- 2015 2020 CTRM Market OutlookDocument17 pages2015 2020 CTRM Market OutlookCTRM CenterNo ratings yet
- Project On Customer Satisfaction Towards Mobile Service ProvidersDocument48 pagesProject On Customer Satisfaction Towards Mobile Service ProvidersViral ChaudhariNo ratings yet
- Data Mining Project ReportDocument29 pagesData Mining Project Reporthema aarthiNo ratings yet
- Guidelines For Business Case Quality and ConsistencyDocument4 pagesGuidelines For Business Case Quality and ConsistencyRobert MariotteNo ratings yet
- Tools For Estimating VMT Reductions From Built Environment ChangesDocument36 pagesTools For Estimating VMT Reductions From Built Environment ChangeskahtanNo ratings yet
- Dipankar Ghosh TSPM Term PaperDocument3 pagesDipankar Ghosh TSPM Term Paperh20180091pNo ratings yet
- Fitra Mulya Saputra - 2206100086 - Summary Chapter 4Document4 pagesFitra Mulya Saputra - 2206100086 - Summary Chapter 4Fitra Mulya SaputraNo ratings yet
- FWD - LS 3922 T - Principles of Operations Managemen EssayDocument11 pagesFWD - LS 3922 T - Principles of Operations Managemen EssaySayan BiwasNo ratings yet
- Cost Estimating Improvement Initiative: Literature Review: Preliminary InvestigationDocument41 pagesCost Estimating Improvement Initiative: Literature Review: Preliminary InvestigationDoni RamadhanNo ratings yet
- E-COMMERCE INDUSTRY ANALYSISDocument35 pagesE-COMMERCE INDUSTRY ANALYSISYASH ALMALNo ratings yet
- Project PPT Second Hand Cars 2nd YearDocument14 pagesProject PPT Second Hand Cars 2nd YearShravan PKNo ratings yet
- ADL 07 Quantitative Techniques in Management V3 1 PDFDocument24 pagesADL 07 Quantitative Techniques in Management V3 1 PDFShahbazNo ratings yet
- Defining Features of The Minibus Taxi IndustryDocument5 pagesDefining Features of The Minibus Taxi IndustrySelva KumarNo ratings yet
- Big Data Management ProjectyDocument18 pagesBig Data Management Projectyakshay kushNo ratings yet
- MPO Case Study - FinalDocument8 pagesMPO Case Study - Finalrajat1311No ratings yet
- MPO Case Study - FinalDocument8 pagesMPO Case Study - Finalrajat1311No ratings yet
- NMCI Case AssignmentDocument6 pagesNMCI Case Assignmentrajat1311No ratings yet
- Johari Window Questionnaire-PackageDocument7 pagesJohari Window Questionnaire-Packagedebianggun10No ratings yet
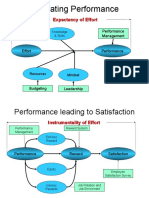
- MotivationDocument7 pagesMotivationrajat1311No ratings yet
- Biomedical EngineeringDocument1 pageBiomedical Engineeringrajat1311No ratings yet
- Sbst1303 - Elementary StatisticsDocument7 pagesSbst1303 - Elementary StatisticsSimon RajNo ratings yet
- Mathematical Statistics I SummaryDocument64 pagesMathematical Statistics I SummarySaad RazaNo ratings yet
- Tugas Analisis Regresi - 220020076 - Novita Ratna DewiDocument17 pagesTugas Analisis Regresi - 220020076 - Novita Ratna DewiNOVITA RATNASMK PGRI 1 GRESIKNo ratings yet
- Autocorrelation: y X U S Euu SDocument15 pagesAutocorrelation: y X U S Euu SRawad JumaaNo ratings yet
- Basic Statistical Tests GuideDocument33 pagesBasic Statistical Tests GuideArnold de los ReyesNo ratings yet
- Note Statistics 2021 Part 3Document22 pagesNote Statistics 2021 Part 3amira qistinaNo ratings yet
- Almanac, 2001) - Use The Median Age of The Preceding Data To Comment OnDocument2 pagesAlmanac, 2001) - Use The Median Age of The Preceding Data To Comment Ontushar jainNo ratings yet
- Mean, Mode, MedianDocument9 pagesMean, Mode, MedianAamirNo ratings yet
- Statistics and Optimization Techniques 2021 Q PAPERDocument3 pagesStatistics and Optimization Techniques 2021 Q PAPERDr Praveen KumarNo ratings yet
- CNSC Statistical Analysis HandoutDocument14 pagesCNSC Statistical Analysis HandoutChristine DamesNo ratings yet
- IBM SPSS Step-by-Step Guide - Histograms and Descriptive Statistics (PDF)Document4 pagesIBM SPSS Step-by-Step Guide - Histograms and Descriptive Statistics (PDF)Melfran Valera ReyesNo ratings yet
- Math 10 Q4 Week1Document26 pagesMath 10 Q4 Week1theacielaNo ratings yet
- FEM3004 Chapter 3 Sampling DistributionDocument20 pagesFEM3004 Chapter 3 Sampling DistributionCheng Kai WahNo ratings yet
- Lectur 4 Basic Statistical Descriptions of DataDocument44 pagesLectur 4 Basic Statistical Descriptions of DataAsma Batool NaqviNo ratings yet
- Module 5 - Measures of VariabilityDocument6 pagesModule 5 - Measures of VariabilityAdrianNo ratings yet
- RISK AND RETURN BoosterDocument15 pagesRISK AND RETURN BoosterBhavya Jain100% (1)
- Chapter 3Document5 pagesChapter 3Haris MalikNo ratings yet
- 3.39 Rain and SnowDocument3 pages3.39 Rain and SnowLarks TacangNo ratings yet
- Customer Day Browser Time (Min) Pages Viewed Amount Spent ($)Document32 pagesCustomer Day Browser Time (Min) Pages Viewed Amount Spent ($)Jimbo ManalastasNo ratings yet
- Data Analysis and VisualizationDocument20 pagesData Analysis and VisualizationCahyo Agung SaputraNo ratings yet
- Ial Maths s1 Ex2fDocument2 pagesIal Maths s1 Ex2fMartha MessinaNo ratings yet
- UM18MB502 QM-1 Unit 1 Practice ProblemsDocument3 pagesUM18MB502 QM-1 Unit 1 Practice ProblemschandrikaNo ratings yet
- Estimating The Sample Mean and Standard Deviation From The Sample Size, Median, Range And/or Interquartile RangeDocument14 pagesEstimating The Sample Mean and Standard Deviation From The Sample Size, Median, Range And/or Interquartile RangeBA OngNo ratings yet
- Chapter 3 Describing, Exploring, and Comparing DataDocument144 pagesChapter 3 Describing, Exploring, and Comparing DatarehmaNo ratings yet
- SPSS Analysis of Leukocyte Count and TreatmentDocument3 pagesSPSS Analysis of Leukocyte Count and Treatmentmustakim gmaNo ratings yet
- TOSDocument16 pagesTOSElizabeth GonzagaNo ratings yet
- A Detailed Lesson Plan in Mathematics 10: A. Preliminary/Routinary ActivityDocument12 pagesA Detailed Lesson Plan in Mathematics 10: A. Preliminary/Routinary ActivityWilson MoralesNo ratings yet
- Tabel R - N 30 0.2290: Uji ValiditasDocument3 pagesTabel R - N 30 0.2290: Uji Validitassamsir rumahlautNo ratings yet
- Measures of Central Tendency-IV-1Document55 pagesMeasures of Central Tendency-IV-1Abhijeet BhardwajNo ratings yet
- Bivariate Data Analysis Olympics Project Lef-2Document6 pagesBivariate Data Analysis Olympics Project Lef-2api-484251774No ratings yet