You might also like
- 2 4二項式定理Document9 pages2 4二項式定理Scc AlanNo ratings yet
- Nodejs Mongo SQL Query GuideDocument17 pagesNodejs Mongo SQL Query Guidexhacker.pengNo ratings yet
- Lesson 5 PDFDocument83 pagesLesson 5 PDF高麒傑No ratings yet
- 奇异值分解 (SVD) 有哪些很厉害的应用? - 知乎Document8 pages奇异值分解 (SVD) 有哪些很厉害的应用? - 知乎Yang CaoNo ratings yet
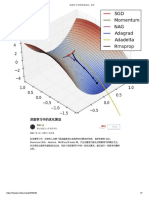
- 2011694 吴辉 强化学习第六次课程作业Document12 pages2011694 吴辉 强化学习第六次课程作业2739557203No ratings yet
- 第4章ADAMS软件算法基本理论Document17 pages第4章ADAMS软件算法基本理论DENNIS songNo ratings yet
- Modeling RF Power Amplifiers With DPD Using Matlab White PaperDocument31 pagesModeling RF Power Amplifiers With DPD Using Matlab White PaperRuixin TuNo ratings yet
- Fpga LedDocument14 pagesFpga Ledtoanbk3iNo ratings yet
- Stata-DeA:数据包络分析一文读懂 连享会主页Document21 pagesStata-DeA:数据包络分析一文读懂 连享会主页TIANTIANNo ratings yet
- eetop.cn DC教程Document13 pageseetop.cn DC教程Quốc Việt TạNo ratings yet
- CCA and Related MethodsDocument4 pagesCCA and Related MethodsAlvin LauNo ratings yet
- 基于幅相分离的属性散射中心参数估计新方法 蒋文Document10 pages基于幅相分离的属性散射中心参数估计新方法 蒋文zjq792150941No ratings yet
- ApacheHTTP源代码手把手教程解读Document228 pagesApacheHTTP源代码手把手教程解读goodnighNo ratings yet
- simulink模型建立及代码生成1Document50 pagessimulink模型建立及代码生成1duanshuang10No ratings yet
- Migration GuideDocument59 pagesMigration GuidesaulNo ratings yet
- JSP網頁設計語法整理Document11 pagesJSP網頁設計語法整理ChiHua0826100% (2)
- 6 汇编语言格式Document20 pages6 汇编语言格式limengdi0269No ratings yet
- Emacs下的计算器 - calcDocument3 pagesEmacs下的计算器 - calcl7943416No ratings yet
- 有穷自动机的原理及应用Finite State AutomatonDocument44 pages有穷自动机的原理及应用Finite State AutomatonYinghui LiuNo ratings yet
- SAP2000 API 入门与 VBA 开发示例Document8 pagesSAP2000 API 入门与 VBA 开发示例cmy384071280No ratings yet
- 深度学习中的优化算法 - 知乎Document7 pages深度学习中的优化算法 - 知乎Yang CaoNo ratings yet
- Hive调优及优化的12种方式 - 知乎Document5 pagesHive调优及优化的12种方式 - 知乎zhao.tangNo ratings yet
- 阿里前端开发规范(部分)Document26 pages阿里前端开发规范(部分)xiaoluo xieNo ratings yet
- VASP计算的理论及实践总结Document18 pagesVASP计算的理论及实践总结Qi LIUNo ratings yet
- 期末報告翻譯版-02clustering and Anomaly Detection Method Using Nearest and Farthest NeighborDocument15 pages期末報告翻譯版-02clustering and Anomaly Detection Method Using Nearest and Farthest Neighbor鄭毓賢No ratings yet
- FastCAE OpenCASCADEDocument141 pagesFastCAE OpenCASCADEguan yunxiaoNo ratings yet
- TrendDB数据库JAVA语言程序接口手册Document62 pagesTrendDB数据库JAVA语言程序接口手册bupa MaoNo ratings yet
- TrendDB技术说明书Document16 pagesTrendDB技术说明书bupa MaoNo ratings yet
- 【不周山之读薄 CSAPP】贰 机器指令与程序优化Document39 pages【不周山之读薄 CSAPP】贰 机器指令与程序优化刘岑岑No ratings yet
- PCA降维与SVDDocument19 pagesPCA降维与SVDwulinjun1360943519No ratings yet
- Stata - 各类全要素生产率 TFP 估算方法Document8 pagesStata - 各类全要素生产率 TFP 估算方法Kai WangNo ratings yet
- 什么是梯度下降法 - 2 - 知乎Document9 pages什么是梯度下降法 - 2 - 知乎Yang CaoNo ratings yet
- xgboost导读和实战Document19 pagesxgboost导读和实战cdasm.orgNo ratings yet
- 「FPGA 設計實務與應用入門 -ADC應用」Document44 pages「FPGA 設計實務與應用入門 -ADC應用」goodyNo ratings yet
- SVM算法Document40 pagesSVM算法wulinjun1360943519No ratings yet
- ETABS高级分析技巧Document15 pagesETABS高级分析技巧3577733983No ratings yet
- 1Document4 pages1王萌萌No ratings yet
- 网易易数大数据平台Document26 pages网易易数大数据平台夏双喜No ratings yet
- Cloud Tencent Com Developer Article 2183300Document40 pagesCloud Tencent Com Developer Article 2183300weigegenb666No ratings yet
- 多核及众核体系结构下线性代数算法研究进展 陶袁Document10 pages多核及众核体系结构下线性代数算法研究进展 陶袁shang zhangNo ratings yet
- SAP Extended Warehouse ManagementDocument127 pagesSAP Extended Warehouse ManagementYanyuNo ratings yet
- 第二讲 第三周Document14 pages第二讲 第三周1029115369No ratings yet
- ADAMS Controls第一~三章Document15 pagesADAMS Controls第一~三章DENNIS songNo ratings yet
- SAS 文件操作语句Document62 pagesSAS 文件操作语句ben liuNo ratings yet
- 5 Pentium微处理器的指令系统Document53 pages5 Pentium微处理器的指令系统limengdi0269No ratings yet
- 程序化交易初级教程Document128 pages程序化交易初级教程James LiuNo ratings yet
- ADAMS Controls第四~五章Document12 pagesADAMS Controls第四~五章DENNIS songNo ratings yet
- 03 MATLAB矩阵运算Document24 pages03 MATLAB矩阵运算Chengcheng LiangNo ratings yet
- 03 - Hadoop MapReduce与Hadoop YARNDocument81 pages03 - Hadoop MapReduce与Hadoop YARNSan ZhangNo ratings yet
- hive性能优化Document11 pageshive性能优化geckoo zhuNo ratings yet
- AN00275 BandR SDC Using The Touchprobe Function RevA CNDocument6 pagesAN00275 BandR SDC Using The Touchprobe Function RevA CNdave chaudhuryNo ratings yet
- 精简版x265教程 2020.4C by iAvoeDocument20 pages精简版x265教程 2020.4C by iAvoesbyanNo ratings yet
- 4 降维算法 liveDocument16 pages4 降维算法 livesuzytang5544No ratings yet
- FortiADC Configuration GuideDocument51 pagesFortiADC Configuration GuideWatkins HsuNo ratings yet
- 面向OLAP数据库查询处理功能的模糊测试工具Document10 pages面向OLAP数据库查询处理功能的模糊测试工具陈治盛No ratings yet
- 基于Pytorch复现Transformer模型并实现英语到法语的机器翻译程序设计Document27 pages基于Pytorch复现Transformer模型并实现英语到法语的机器翻译程序设计hanblingz026No ratings yet
- Verilog HDLDocument32 pagesVerilog HDLem330No ratings yet
- 视觉几何三维重建 OpenMVS源码解析Document84 pages视觉几何三维重建 OpenMVS源码解析guan yunxiaoNo ratings yet
- MATLAB程序设计及应用实例Document60 pagesMATLAB程序设计及应用实例dust AssassinNo ratings yet
- 数据结构导论绪论Document9 pages数据结构导论绪论好文超No ratings yet
- 随机过程及其应用Document18 pages随机过程及其应用Eric PritchettNo ratings yet
- 线性代数的本质11 抽象向量空间 - 知乎 00.16.51Document1 page线性代数的本质11 抽象向量空间 - 知乎 00.16.51rileeeeeNo ratings yet
- 简明预积分推导 - 知乎Document13 pages简明预积分推导 - 知乎李金良No ratings yet
- Version 1 2Document141 pagesVersion 1 2王宇No ratings yet
- 2021年4年级数学RPTDocument19 pages2021年4年级数学RPTESTHER SIOW SHUEN SHIN MoeNo ratings yet
- Research Methods - Factor Analysis and Cluster Analysis SlidesDocument103 pagesResearch Methods - Factor Analysis and Cluster Analysis Slides任婷No ratings yet
- 「代码随想录」二叉树专题精讲(v1 2)Document207 pages「代码随想录」二叉树专题精讲(v1 2)shi spNo ratings yet
- 張力計使用說明Document3 pages張力計使用說明莫白No ratings yet
- 人工智能选股之特征选择华泰人工智能系列之十二Document25 pages人工智能选股之特征选择华泰人工智能系列之十二项青云No ratings yet
- 高端专项启动书:路测信令智能分析解决思路专项启动书 v2Document10 pages高端专项启动书:路测信令智能分析解决思路专项启动书 v2wooskyhkNo ratings yet