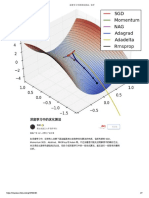
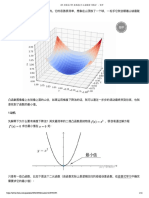
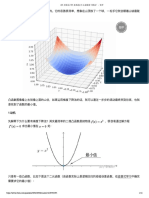
You might also like
- Stata - 各类全要素生产率 TFP 估算方法Document8 pagesStata - 各类全要素生产率 TFP 估算方法Kai WangNo ratings yet
- 基于Pytorch复现Transformer模型并实现英语到法语的机器翻译程序设计Document27 pages基于Pytorch复现Transformer模型并实现英语到法语的机器翻译程序设计hanblingz026No ratings yet
- 2021聯盟網 CPA串接文件Document7 pages2021聯盟網 CPA串接文件mah12076No ratings yet
- ISO-TS16949五大手册-MSA - 测量系统分析 (pdf 54)Document54 pagesISO-TS16949五大手册-MSA - 测量系统分析 (pdf 54)Angus CHUNo ratings yet
- 海通证券 选股因子系列研究(八十八):多颗粒度特征的深度学习模型,探索和对比Document19 pages海通证券 选股因子系列研究(八十八):多颗粒度特征的深度学习模型,探索和对比zhaoqc418No ratings yet
- Numerical Analysis Midterm ProjectDocument21 pagesNumerical Analysis Midterm ProjectBrian HuangNo ratings yet
- 我的第一本算法书 石田保辉 宫崎修一Document210 pages我的第一本算法书 石田保辉 宫崎修一check ngNo ratings yet
- 运输经济学期中大作业Document16 pages运输经济学期中大作业lingmaoNo ratings yet
- 第九届蓝桥杯大赛竞赛大纲(软件类)Document15 pages第九届蓝桥杯大赛竞赛大纲(软件类)vmmmzhuanyongNo ratings yet
- Openbugs Step by StepDocument25 pagesOpenbugs Step by StepChen Yung-weiNo ratings yet
- CN Machine Learning Ebook All ChaptersDocument65 pagesCN Machine Learning Ebook All ChaptersPENG YANNo ratings yet
- Python视觉实战项目71讲 (更新)Document607 pagesPython视觉实战项目71讲 (更新)杨奕航No ratings yet
- IBM SPSS Neural NetworkDocument24 pagesIBM SPSS Neural NetworkMiguel AngelNo ratings yet
- 9Document11 pages9Trần HiệpNo ratings yet
- 程式設計 (三)Document25 pages程式設計 (三)tsaips81921No ratings yet
- 時間序列實驗分析指南Document62 pages時間序列實驗分析指南euler96100% (1)
- OLAP建模与查询优化实践Document150 pagesOLAP建模与查询优化实践gx8tgn9767No ratings yet
- excel数据分析教程Document46 pagesexcel数据分析教程海涛扬No ratings yet
- Mac Rosyn TecDocument43 pagesMac Rosyn Tecthope_baekNo ratings yet
- day02 【数据类型转换、运算符、方法入门】Document12 pagesday02 【数据类型转换、运算符、方法入门】季南城No ratings yet
- Stata-DeA:数据包络分析一文读懂 连享会主页Document21 pagesStata-DeA:数据包络分析一文读懂 连享会主页TIANTIANNo ratings yet
- 2020「决策树及其集成」教案Document19 pages2020「决策树及其集成」教案Ron TanNo ratings yet
- 2022 HKACE Mock ICT 2D Chi v20220109Document15 pages2022 HKACE Mock ICT 2D Chi v20220109GL MakNo ratings yet
- machine learning yearning 中文版 2Document15 pagesmachine learning yearning 中文版 2sapphirelsenNo ratings yet
- Lesson 5 PDFDocument83 pagesLesson 5 PDF高麒傑No ratings yet
- MLX90640开发笔记(第1 10篇) PDFDocument29 pagesMLX90640开发笔记(第1 10篇) PDFLe GNo ratings yet
- 【CASIO】fx-82 SOLAR Ⅱ彩色說明書 - Ver.1904 PDFDocument24 pages【CASIO】fx-82 SOLAR Ⅱ彩色說明書 - Ver.1904 PDFDorisNo ratings yet
- Casio 350MSDocument38 pagesCasio 350MS......No ratings yet
- Nodejs Mongo SQL Query GuideDocument17 pagesNodejs Mongo SQL Query Guidexhacker.pengNo ratings yet
- Ch12345Homework 20210219xgDocument5 pagesCh12345Homework 20210219xgAmyNo ratings yet
- 黑盒测试Document100 pages黑盒测试kiddzhou6No ratings yet
- LCMS GettingStartedGuideDocument64 pagesLCMS GettingStartedGuide张旭东No ratings yet
- 交通分配Document8 pages交通分配afbvewmpdNo ratings yet
- 虚拟软件使用说明书v1 0Document11 pages虚拟软件使用说明书v1 0meiwanlanjunNo ratings yet
- 4 降维算法 liveDocument16 pages4 降维算法 livesuzytang5544No ratings yet
- UntitledDocument28 pagesUntitledchinreiNo ratings yet
- 10讲动态规划(下):如何求得状态转移方程并进行编程实现Document21 pages10讲动态规划(下):如何求得状态转移方程并进行编程实现yunlong yuNo ratings yet
- 汽車產業CAEDocument12 pages汽車產業CAE模具工程系謝惟晴No ratings yet
- 梯度下降Document10 pages梯度下降Tony ZhengNo ratings yet
- 02 Data PropertyDocument26 pages02 Data Property張cyunNo ratings yet
- 期末簡報111-1 機動學Document35 pages期末簡報111-1 機動學super longhairNo ratings yet
- 工业视觉综合管理平台用户手册Document26 pages工业视觉综合管理平台用户手册wty2494624575No ratings yet
- 工业视觉综合管理平台用户手册Document26 pages工业视觉综合管理平台用户手册wty2494624575No ratings yet
- 金融工程专题研究:市场强弱下动态回撤率控制 国信证券Document21 pages金融工程专题研究:市场强弱下动态回撤率控制 国信证券zhaoyusong318No ratings yet
- WEB安全之反射型XSS扫描器的实现 毕业设计说明文Document14 pagesWEB安全之反射型XSS扫描器的实现 毕业设计说明文夏辰No ratings yet
- 2020212309 安柯锦 实验报告Document38 pages2020212309 安柯锦 实验报告徐赟博No ratings yet
- C语言Document20 pagesC语言XHwNo ratings yet
- 第 08 节 GEE 的数据类型 (Landsat Images, Confusion Marix)Document7 pages第 08 节 GEE 的数据类型 (Landsat Images, Confusion Marix)Davidata LiaoNo ratings yet
- Basic caculator 3 (基礎計算機3)Document7 pagesBasic caculator 3 (基礎計算機3)林宗佑No ratings yet
- Migration GuideDocument59 pagesMigration GuidesaulNo ratings yet
- MHNGJKNDocument6 pagesMHNGJKNGMNo ratings yet
- Emacs下的计算器 - calcDocument3 pagesEmacs下的计算器 - calcl7943416No ratings yet
- 程序语言实验学习Document7 pages程序语言实验学习meiwanlanjunNo ratings yet
- 36丨生产者 消费者模式:用流水线思想提高效率Document12 pages36丨生产者 消费者模式:用流水线思想提高效率Tom TomatoooNo ratings yet
- NI VeriStand 2010 使用手册Document59 pagesNI VeriStand 2010 使用手册jackgeng1971No ratings yet
- 软件工程Document193 pages软件工程Moh Abd BenNo ratings yet
- CCA and Related MethodsDocument4 pagesCCA and Related MethodsAlvin LauNo ratings yet
- 试题Document14 pages试题47j9vpgfb7No ratings yet
- 如何正确理解特征值与特征向量 - 知乎Document4 pages如何正确理解特征值与特征向量 - 知乎Yang CaoNo ratings yet
- 如何记住所有的三角函数公式? - 知乎Document8 pages如何记住所有的三角函数公式? - 知乎Yang CaoNo ratings yet
- 为什么样本方差 (Sample Variance) 的分母是 N-1? - 知乎Document9 pages为什么样本方差 (Sample Variance) 的分母是 N-1? - 知乎Yang CaoNo ratings yet
- 如何正确理解主成分分析 (PCA) 和奇异值分解 (SVD) - 知乎Document5 pages如何正确理解主成分分析 (PCA) 和奇异值分解 (SVD) - 知乎Yang CaoNo ratings yet
- 如何自己从零实现一个神经网络 - - 知乎Document18 pages如何自己从零实现一个神经网络 - - 知乎Yang CaoNo ratings yet
- 如何通俗地理解概率论中的 极大似然估计法 - - 知乎Document16 pages如何通俗地理解概率论中的 极大似然估计法 - - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 2 - 知乎Document9 pages什么是梯度下降法 - 2 - 知乎Yang CaoNo ratings yet
- 一文搞懂麦克斯韦方程,现代科技的总基石,人类文明的加速器 - 知乎Document34 pages一文搞懂麦克斯韦方程,现代科技的总基石,人类文明的加速器 - 知乎Yang CaoNo ratings yet
- 深度学习中的优化算法 - 知乎Document7 pages深度学习中的优化算法 - 知乎Yang CaoNo ratings yet
- 求极限方法总结 - 知乎Document5 pages求极限方法总结 - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 1 - 知乎Document11 pages什么是梯度下降法 - 1 - 知乎Yang CaoNo ratings yet
- 活用拉格朗日中值,吊打复杂极限难题! - 知乎Document7 pages活用拉格朗日中值,吊打复杂极限难题! - 知乎Yang CaoNo ratings yet
- 做好机器学习,数学要学到什么程度? - 知乎Document11 pages做好机器学习,数学要学到什么程度? - 知乎Yang CaoNo ratings yet
- 格林公式的几何意义是什么? - 知乎Document19 pages格林公式的几何意义是什么? - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 3 - 知乎Document8 pages什么是梯度下降法 - 3 - 知乎Yang CaoNo ratings yet
- 梯度, 散度, 旋度, Jacobian, Hessian, Laplacian 的关系图 - 知乎Document4 pages梯度, 散度, 旋度, Jacobian, Hessian, Laplacian 的关系图 - 知乎Yang CaoNo ratings yet
- 树莓派项目实战 第一节 点亮LED灯 - 知乎Document16 pages树莓派项目实战 第一节 点亮LED灯 - 知乎Yang CaoNo ratings yet
- 吴恩达倾情推荐!这28张图全解深度学习知识真棒! - 知乎Document32 pages吴恩达倾情推荐!这28张图全解深度学习知识真棒! - 知乎Yang CaoNo ratings yet
- 一文搞懂麦克斯韦方程,现代科技的总基石,人类文明的加速器 - 知乎Document34 pages一文搞懂麦克斯韦方程,现代科技的总基石,人类文明的加速器 - 知乎Yang CaoNo ratings yet
- 树莓派项目实战 第二节 制作led呼吸灯 - 知乎Document14 pages树莓派项目实战 第二节 制作led呼吸灯 - 知乎Yang CaoNo ratings yet
- 奇异值与特征值辨析 - 知乎Document8 pages奇异值与特征值辨析 - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 2 - 知乎Document9 pages什么是梯度下降法 - 2 - 知乎Yang CaoNo ratings yet
- 函数极限的超强笔记总结 - 知乎Document7 pages函数极限的超强笔记总结 - 知乎Yang CaoNo ratings yet
- 做好机器学习,数学要学到什么程度? - 知乎Document11 pages做好机器学习,数学要学到什么程度? - 知乎Yang CaoNo ratings yet
- 为什么样本方差 (Sample Variance) 的分母是 N-1? - 知乎Document9 pages为什么样本方差 (Sample Variance) 的分母是 N-1? - 知乎Yang CaoNo ratings yet
- 为什么样本方差 (sample variance) 的分母是 n-1? - 知乎Document9 pages为什么样本方差 (sample variance) 的分母是 n-1? - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 1 - 知乎Document11 pages什么是梯度下降法 - 1 - 知乎Yang CaoNo ratings yet
- Pandas 在使用时语法感觉很乱,有什么学习的技巧吗? - 知乎Document21 pagesPandas 在使用时语法感觉很乱,有什么学习的技巧吗? - 知乎Yang CaoNo ratings yet
- 什么是梯度下降法 - 2 - 知乎Document9 pages什么是梯度下降法 - 2 - 知乎Yang CaoNo ratings yet
- 2022年吉林省普通高校招生计划 (Ocr)Document389 pages2022年吉林省普通高校招生计划 (Ocr)Wong YoungNo ratings yet
- CCIE Routing and SwitchingDocument447 pagesCCIE Routing and SwitchingVincent ShenNo ratings yet
- Penggal 1 Minggu 2Document8 pagesPenggal 1 Minggu 2LIM SEN HONG MoeNo ratings yet
- 国语艺术特色Document3 pages国语艺术特色Hedy LingNo ratings yet
- 2020年百度、阿里、腾讯、字节跳动Android高频面试题解析Document677 pages2020年百度、阿里、腾讯、字节跳动Android高频面试题解析pocket mo.No ratings yet
- Lesson PlanDocument5 pagesLesson PlanAdrian ChewNo ratings yet
- 03章 羅馬天主教儀式與聖歌2020 VerDocument4 pages03章 羅馬天主教儀式與聖歌2020 Ver吳戎彬No ratings yet
- 俄罗斯进出口标准,技术规格,法律,法规,中英文,目录编号rg 1803Document1 page俄罗斯进出口标准,技术规格,法律,法规,中英文,目录编号rg 1803KediaralNo ratings yet
- 透过语根修行Document12 pages透过语根修行譚馬凡No ratings yet
- Bai 8 西瓜一斤多少钱Document15 pagesBai 8 西瓜一斤多少钱ny gfanNo ratings yet
- D20432 Exe 01Document4 pagesD20432 Exe 01Cph CpNo ratings yet
- 北岛 - 蓝房子Document44 pages北岛 - 蓝房子Nunu AbuashviliNo ratings yet
- Verilog-A 30分钟快速入门教程Document7 pagesVerilog-A 30分钟快速入门教程tonywaiNo ratings yet