You might also like
- Python Data ImportDocument28 pagesPython Data ImportBeni Djohan100% (1)
- Start DateDocument2 pagesStart DateHussainNo ratings yet
- Simple Tutorial in RDocument15 pagesSimple Tutorial in RklugshitterNo ratings yet
- Split and Create Py FileDocument3 pagesSplit and Create Py Filekakashi hatakeNo ratings yet
- SCD Typ2 in Databricks AzureDocument8 pagesSCD Typ2 in Databricks Azuresayhi2sudarshan0% (1)
- Python RulesDocument9 pagesPython Rulesshrivastavanuj823No ratings yet
- Data Flow TransformationDocument1 pageData Flow Transformationrampage4630No ratings yet
- IDAP AssignmentDocument6 pagesIDAP AssignmentRithik ReddyNo ratings yet
- XXDocument4 pagesXXMuhdhanafiNo ratings yet
- Python MannualDocument50 pagesPython Mannualrasalshweta221No ratings yet
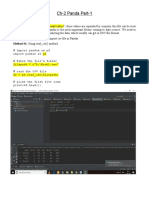
- Ch-2 - Panda - Part-1 - 3rd - DayDocument5 pagesCh-2 - Panda - Part-1 - 3rd - DayRC SharmaNo ratings yet
- Text File Programs Xii CDocument6 pagesText File Programs Xii Cmashiuddin mohammedNo ratings yet
- 2736118-Python PandasDocument2 pages2736118-Python PandasSanthoshNo ratings yet
- Sahil Malhotra 16 BCE 0113 Web Mining L51+L52: 1. Universal Crawling 1.1. CODEDocument11 pagesSahil Malhotra 16 BCE 0113 Web Mining L51+L52: 1. Universal Crawling 1.1. CODEsahilNo ratings yet
- Sub BookmarksDocument2 pagesSub BookmarksmuthyalarajeshNo ratings yet
- How To Parse Data Tables From A PDF Bank Statement With Python - by Phillip Heita - Nov, 2021 - MediumDocument8 pagesHow To Parse Data Tables From A PDF Bank Statement With Python - by Phillip Heita - Nov, 2021 - MediumdirgaNo ratings yet
- PythonDocument31 pagesPythonRimjhim KymariNo ratings yet
- Vasu Nagar CS Report FileDocument38 pagesVasu Nagar CS Report Filenagar.vasu0810No ratings yet
- Cse Material 4Document7 pagesCse Material 4aasthaa1805No ratings yet
- Functions in PythonDocument19 pagesFunctions in Pythonsonali karkiNo ratings yet
- Lab3 - Python - Pandas DataFrame - GeeksforGeeksDocument20 pagesLab3 - Python - Pandas DataFrame - GeeksforGeekssa00059No ratings yet
- Import Pandas As PDDocument2 pagesImport Pandas As PDG SuriyanaraynanNo ratings yet
- Psdata 01Document1 pagePsdata 01prof.dourival.juniorNo ratings yet
- Source Code Python JemmyDocument7 pagesSource Code Python JemmyFadilah RiczkyNo ratings yet
- Computer Science-CLASS-12-RECORD PROGRAMSDocument10 pagesComputer Science-CLASS-12-RECORD PROGRAMSnitheeshchowdary2007No ratings yet
- IterationDocument40 pagesIterationSidhu WorldwideNo ratings yet
- HAND NOTE-PDF REPORTING - Id.enDocument4 pagesHAND NOTE-PDF REPORTING - Id.enmaryamNo ratings yet
- Test SqsDocument8 pagesTest Sqssamir silwalNo ratings yet
- Chatbot Exp6Document1 pageChatbot Exp620bd1a6622No ratings yet
- How To in PandasDocument1 pageHow To in PandasSureshNo ratings yet
- File Handling in PythonDocument5 pagesFile Handling in Pythontmv venkateshNo ratings yet
- PDFTK MaunalDocument6 pagesPDFTK MaunalMarlon MachadoNo ratings yet
- Python Part B ProgramsDocument6 pagesPython Part B Programschethan rohith PCNo ratings yet
- Introduction To Pandas LibraryDocument4 pagesIntroduction To Pandas LibraryAbhisingNo ratings yet
- Testing - Ipynb - ColaboratoryDocument3 pagesTesting - Ipynb - Colaboratory555 FFNo ratings yet
- PDFTK Server Man PageDocument8 pagesPDFTK Server Man PagecafjnkNo ratings yet
- Python - Module Test - Jupyter NotebookDocument6 pagesPython - Module Test - Jupyter NotebookPawan GosaviNo ratings yet
- Python LabDocument13 pagesPython Labbiswadeepbasak0212No ratings yet
- Record Practicals - XiiDocument30 pagesRecord Practicals - Xiir0776817No ratings yet
- DemocodeDocument1 pageDemocodepanditNo ratings yet
- 12 Cs Cbse QP ProgramsDocument10 pages12 Cs Cbse QP Programsroyalfancy704No ratings yet
- PythonDocument32 pagesPythonYogenDran SuraskumarNo ratings yet
- IR Journal (Printable)Document20 pagesIR Journal (Printable)krii24u8No ratings yet
- Document 1Document5 pagesDocument 1Soumyakant BeheraNo ratings yet
- Pre-Processing Example - 1Document6 pagesPre-Processing Example - 1Ishani MehtaNo ratings yet
- Pandas DataframeDocument48 pagesPandas DataframeJames PrakashNo ratings yet
- CS Practical File 2023-24Document49 pagesCS Practical File 2023-24Souvik JEE 2024No ratings yet
- Python LabDocument13 pagesPython Labbiswadeepbasak0212No ratings yet
- Write A Program To Capitalize First and Last Letter of Given StringDocument45 pagesWrite A Program To Capitalize First and Last Letter of Given Stringrasalshweta221No ratings yet
- CS Practical File 2023-24Document51 pagesCS Practical File 2023-24apnshayarNo ratings yet
- 6 - Text Vectorization-CSC688-SP22Document5 pages6 - Text Vectorization-CSC688-SP22Crypto GeniusNo ratings yet
- Web ScrapingDocument11 pagesWeb ScrapingAlya RusmiNo ratings yet
- Assignment 5Document3 pagesAssignment 5shrinkhal03No ratings yet
- File IODocument15 pagesFile IOalmulla7xNo ratings yet
- 3Document7 pages3Rithik ReddyNo ratings yet
- Shreyas Practical Doc FinalDocument44 pagesShreyas Practical Doc FinalshreyassantoshkurupNo ratings yet
- Data Handling Using Pandas-1Document25 pagesData Handling Using Pandas-1shakti singhNo ratings yet
- Chapter 12-pDocument13 pagesChapter 12-paravindkbNo ratings yet