You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (843)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5810)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (346)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Rigging JSA RiggerDocument12 pagesRigging JSA RiggeraQiLGunawanNo ratings yet
- LR - Phil Politics and Governance Week 1 For StudentDocument19 pagesLR - Phil Politics and Governance Week 1 For StudentErinRoelleNo ratings yet
- CHAPTER Five Transiportation ProblemDocument8 pagesCHAPTER Five Transiportation ProblemLe nternetNo ratings yet
- Adidas and Automated Sewbots!Document7 pagesAdidas and Automated Sewbots!Akanksha MishraNo ratings yet
- Kusisami Hornberger - Scaling Impact - Finance and Investment For A Better World-Palgrave Macmillan (2023)Document269 pagesKusisami Hornberger - Scaling Impact - Finance and Investment For A Better World-Palgrave Macmillan (2023)Nemeth AdamNo ratings yet
- LCM 285 ConklingDocument8 pagesLCM 285 ConklingShukura ShuaibNo ratings yet
- Circus LecturaDocument1 pageCircus LecturadanielNo ratings yet
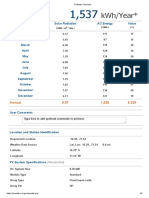
- PVWatts Calculator 0.78Document2 pagesPVWatts Calculator 0.78DiegoJimNo ratings yet
- Research Paper On Performance AppraisalDocument6 pagesResearch Paper On Performance AppraisalAlla nemma0% (1)
- Company Name Employee Turnover Manual v1Document17 pagesCompany Name Employee Turnover Manual v1Lý Ngọc HiếuNo ratings yet
- Man Hanway Raw 125 14Document40 pagesMan Hanway Raw 125 14Jose GarciaNo ratings yet
- Summary TDT Task Force SurveyDocument10 pagesSummary TDT Task Force SurveyJeff WeinerNo ratings yet
- How Do I Enable or Disable HDMI Audio in Windows If I Am Using An HDMI Connection Between My Nvidia Video Card or Motherboard and My Monitor?Document3 pagesHow Do I Enable or Disable HDMI Audio in Windows If I Am Using An HDMI Connection Between My Nvidia Video Card or Motherboard and My Monitor?JavadNo ratings yet
- Analog Video 101 - National Instruments PDFDocument7 pagesAnalog Video 101 - National Instruments PDFjollygreengiant001No ratings yet
- Office Administration Caribbean Secondary Examination Council School Based Assessment (SBA) 2023Document21 pagesOffice Administration Caribbean Secondary Examination Council School Based Assessment (SBA) 2023Tianna MorganNo ratings yet
- Design Consideration Material Selection-EditedDocument8 pagesDesign Consideration Material Selection-EditedRajani DalalNo ratings yet
- Risk Ambank IslamicDocument4 pagesRisk Ambank Islamicirfan sururiNo ratings yet
- PNP Booking Form 2 - "Arrest and Booking Form": (To Be Accomplished by The Arresting Officer)Document2 pagesPNP Booking Form 2 - "Arrest and Booking Form": (To Be Accomplished by The Arresting Officer)Brixter Dumalina AsanNo ratings yet
- Quiz 2 Acctg Major 8Document4 pagesQuiz 2 Acctg Major 8Jovyl InguitoNo ratings yet
- Federal Brands LimitedDocument13 pagesFederal Brands LimitedAnkit KaushikNo ratings yet
- TTCC - 2023 Fee Structure For Junior PlayersDocument4 pagesTTCC - 2023 Fee Structure For Junior PlayersSuchhandoNo ratings yet
- Information System Contingency Plan TemplateDocument44 pagesInformation System Contingency Plan TemplateJaredNo ratings yet
- Unit 8 Evolution of TelevisionDocument26 pagesUnit 8 Evolution of TelevisionYanz MuhamadNo ratings yet
- Press ReleaseDocument3 pagesPress Releaseokello jacob juniorNo ratings yet
- Beam Ismb SpecificationDocument3 pagesBeam Ismb SpecificationAbhinav KumarNo ratings yet
- Chapter 24-btvnDocument40 pagesChapter 24-btvnĐặng Khánh Linh100% (1)
- Brillantes Vs CastroDocument1 pageBrillantes Vs CastroDan LocsinNo ratings yet
- Tioga NicetownDocument93 pagesTioga NicetownbaumawbNo ratings yet
- The FollowingDocument2 pagesThe FollowingAnthony Angel TejaresNo ratings yet
- Madfund NotesDocument14 pagesMadfund NotesJoshua KhoNo ratings yet