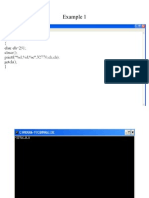
You might also like
- DA SampleDocument21 pagesDA SampleANCY SHARMILA D 20MIS0211No ratings yet
- Unit - 2Document37 pagesUnit - 2abisheakrayarschool123No ratings yet
- Prog Das CDocument61 pagesProg Das CAsaCircleNo ratings yet
- Experiment 1Document51 pagesExperiment 1Harshit SinghNo ratings yet
- 4 StatementsDocument32 pages4 StatementssandhyaNo ratings yet
- C ProgrammingDocument12 pagesC ProgrammingLaxman ThapaNo ratings yet
- CD Lab fileAADocument24 pagesCD Lab fileAAintkhab khanNo ratings yet
- Programs With SolDocument28 pagesPrograms With SolSai Tejesh Reddy Gurijala71% (7)
- C Switch... Case StatementDocument6 pagesC Switch... Case Statementسرحان سويد عيسىNo ratings yet
- A Crash Course in C Notes: Chapter 1: FundamentalsDocument91 pagesA Crash Course in C Notes: Chapter 1: Fundamentalssid1990No ratings yet
- Computer 12 CH11 NotesDocument18 pagesComputer 12 CH11 Noteskhanali62864No ratings yet
- CD (KCS - 552) Lab FileDocument41 pagesCD (KCS - 552) Lab FileVashu GuptaNo ratings yet
- Exp7 RojidDocument5 pagesExp7 Rojidbhalaninaman7No ratings yet
- Question Solution of CIT-111Document42 pagesQuestion Solution of CIT-111Sadia Islam ShefaNo ratings yet
- C LanguagenotesDocument33 pagesC LanguagenotesMichelle Anne ConstantinoNo ratings yet
- C-Language: Lets Learn Fundamentals !!Document30 pagesC-Language: Lets Learn Fundamentals !!malhiavtarsinghNo ratings yet
- Compiler Design LabDocument29 pagesCompiler Design LabNikhil GautamNo ratings yet
- Introduction To C ProgrammingDocument44 pagesIntroduction To C ProgrammingMark Solo IIINo ratings yet
- PCD Lab ManualDocument24 pagesPCD Lab Manualthalasiva64% (25)
- C Programming:: Numerals: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 Alphabets: A, B, .ZDocument13 pagesC Programming:: Numerals: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 Alphabets: A, B, .ZbhavanatiwariNo ratings yet
- Programming in C: by Dhishna DevadasDocument31 pagesProgramming in C: by Dhishna DevadasDhishna DevadasNo ratings yet
- CS 120 Variable DeclarationDocument21 pagesCS 120 Variable DeclarationHassan A. Bu KharsNo ratings yet
- Compiler Design LabDocument62 pagesCompiler Design Lab48 Kartik BhasinNo ratings yet
- Sample Exam Intake 27Document5 pagesSample Exam Intake 27Eyad El RefaieNo ratings yet
- APIC Ch-2 Theory+Practicals-1Document40 pagesAPIC Ch-2 Theory+Practicals-1Vekariya KartikNo ratings yet
- BCSL-33 Lab-Manual-Solution PDFDocument27 pagesBCSL-33 Lab-Manual-Solution PDFsparamveer95_49915960% (2)
- Scanf ("Control String", &var1, &var2... &varn)Document6 pagesScanf ("Control String", &var1, &var2... &varn)D V SASANKANo ratings yet
- Concepts of Programming (Using C)Document93 pagesConcepts of Programming (Using C)Prabin SilwalNo ratings yet
- Overall C Question Bank For StudentsDocument42 pagesOverall C Question Bank For StudentsPriyadarshini.RNo ratings yet
- Shamim Reza (221010006) Lab 3Document13 pagesShamim Reza (221010006) Lab 3Shamim RezaNo ratings yet
- Chapter 02 - Fundamental Input Output and Basic C OperatorsDocument44 pagesChapter 02 - Fundamental Input Output and Basic C OperatorsTed ChanNo ratings yet
- Control StructureDocument27 pagesControl Structureabdishakuradan4040No ratings yet
- C - Language by PrashanthDocument37 pagesC - Language by PrashanthPrashanthNo ratings yet
- C LanguageDocument259 pagesC LanguageAmit AnandNo ratings yet
- Cprogramming ICTweek 4Document31 pagesCprogramming ICTweek 4Mr. CreeperNo ratings yet
- Tin Hoc Co So 2 Week4 HustDocument51 pagesTin Hoc Co So 2 Week4 Hustvanhoangdz2003No ratings yet
- 3-Elements of C-31-07-2023Document31 pages3-Elements of C-31-07-2023Dhruv GuptaNo ratings yet
- Input/output in ProgrammingDocument28 pagesInput/output in ProgrammingDuongVanKienNo ratings yet
- Fundamentals of Computer Programming - Dr. A. Charan KumariDocument35 pagesFundamentals of Computer Programming - Dr. A. Charan KumariTHE NORTHCAP UNIVERSITYNo ratings yet
- Why Doesn't C Support Function Overloading?Document17 pagesWhy Doesn't C Support Function Overloading?PEPETI RAVINo ratings yet
- Crash Course in CDocument59 pagesCrash Course in CmultimalikNo ratings yet
- Computer 12 CH10 NotesDocument11 pagesComputer 12 CH10 Notes9t6vx7psm5No ratings yet
- First Program of CDocument69 pagesFirst Program of Caces thalaNo ratings yet
- C Lab Worksheet 5 - 2 C/C++ Variable, Operator and Type 3: // Needed For PrintfDocument7 pagesC Lab Worksheet 5 - 2 C/C++ Variable, Operator and Type 3: // Needed For Printfsalma_1No ratings yet
- Day 2 - (Managing IO and Operators)Document25 pagesDay 2 - (Managing IO and Operators)M.RAMYA DEVI HICET STAFF CSENo ratings yet
- C Programming - Part ADocument5 pagesC Programming - Part APriya JoyNo ratings yet
- 3.variables & OperatorsDocument35 pages3.variables & OperatorsTazbir AntuNo ratings yet
- C Tutorial 2Document63 pagesC Tutorial 2Gitesh NagarNo ratings yet
- BcaDocument29 pagesBcagauravb46No ratings yet
- C Lab ManualDocument12 pagesC Lab ManualMahalakshmi ShanmugamNo ratings yet
- C ProgrammingDocument62 pagesC Programmingabebaw ataleleNo ratings yet
- System Programming Lab: LEX: Lexical Analyser GeneratorDocument33 pagesSystem Programming Lab: LEX: Lexical Analyser GeneratorDivya D GowdaNo ratings yet
- Compiler Design: Practical FileDocument34 pagesCompiler Design: Practical FileRohit KumarNo ratings yet
- Decision MakingDocument14 pagesDecision MakingRASHMI ACHARYANo ratings yet
- DOTE TNDTE C Programming LABDocument14 pagesDOTE TNDTE C Programming LABsmagendiranNo ratings yet
- PogramsDocument20 pagesPogramsThamizh ArasiNo ratings yet
- Assignment 2 04042021 045308pmDocument14 pagesAssignment 2 04042021 045308pmatifNo ratings yet
- C ProgrammingDocument56 pagesC Programmingvishnu_kota58No ratings yet
- 21BRS1284 Ros L6Document5 pages21BRS1284 Ros L6Anime ZNo ratings yet
- CodeTantra Apply For ReevaluationDocument2 pagesCodeTantra Apply For ReevaluationAnime ZNo ratings yet
- Alternate Options in Lieu of Summer Industrial InternshipDocument1 pageAlternate Options in Lieu of Summer Industrial InternshipAnime ZNo ratings yet
- Pat 7Document1 pagePat 7Anime ZNo ratings yet
- Python Pandas & NumphyDocument19 pagesPython Pandas & NumphyAnime ZNo ratings yet
- 111111Document1 page111111Anime ZNo ratings yet
- Solution - Matrices Determinants Sheet - MathonGo BITSAT Crash CourseDocument9 pagesSolution - Matrices Determinants Sheet - MathonGo BITSAT Crash CourseAnime ZNo ratings yet
- Determinants - BITSAT Previous Year Chapter-Wise Sheets - MathonGoDocument6 pagesDeterminants - BITSAT Previous Year Chapter-Wise Sheets - MathonGoAnime ZNo ratings yet
- Question - Matrices Determinants Sheet - MathonGo BITSAT Crash CourseDocument6 pagesQuestion - Matrices Determinants Sheet - MathonGo BITSAT Crash CourseAnime ZNo ratings yet
- Class9-NTSE MATH WORKSHEETDocument4 pagesClass9-NTSE MATH WORKSHEETJeetu RaoNo ratings yet
- 2021 Lecture08 FirstOrderLogic PDFDocument97 pages2021 Lecture08 FirstOrderLogic PDFMinh ChâuNo ratings yet
- Kursus Asas TiktokDocument28 pagesKursus Asas TiktokAinun Rafieza Ahmad Tajuddin100% (3)
- Databases For A Purpose 03/03 (Programming Language) ICT Starters 8984/4293Document34 pagesDatabases For A Purpose 03/03 (Programming Language) ICT Starters 8984/4293Yann VautrinNo ratings yet
- Pri Dlbt1201182enDocument2 pagesPri Dlbt1201182enzaheerNo ratings yet
- AT-500 Antenna Tester: Operation ManualDocument53 pagesAT-500 Antenna Tester: Operation ManualTecnica ACNNo ratings yet
- Swing JavaBuilderDocument88 pagesSwing JavaBuilderIvánNo ratings yet
- AWS General Version 1.0Document342 pagesAWS General Version 1.0gopuggNo ratings yet
- PC Lab ManualDocument47 pagesPC Lab ManualAoiNo ratings yet
- Unit 1: Compiler DesignDocument74 pagesUnit 1: Compiler Designlakshay oberoiNo ratings yet
- Wonderware Application Server Scripting GuideDocument148 pagesWonderware Application Server Scripting Guideshidris007No ratings yet
- Arma Server Web Admin - ARMA 3 - COMMUNITY MADE UTILITIES - Bohemia Interactive Forums PDFDocument1 pageArma Server Web Admin - ARMA 3 - COMMUNITY MADE UTILITIES - Bohemia Interactive Forums PDFBMikeNo ratings yet
- Phantasy Star Portable 2 Infinity - Japanese To English Translation Guide by DeviFoxxDocument236 pagesPhantasy Star Portable 2 Infinity - Japanese To English Translation Guide by DeviFoxxAnonymous 3CCzxUK0d6No ratings yet
- ProfileDocument2 pagesProfilesandip kajaleNo ratings yet
- Tally Prime Short KeyDocument2 pagesTally Prime Short KeyAbhijeetNo ratings yet
- Curriculam Vitae: Lavanya E Email: Mob: +Document4 pagesCurriculam Vitae: Lavanya E Email: Mob: +Vishal FernandesNo ratings yet
- LOGIQ P9 DatasheetDocument10 pagesLOGIQ P9 DatasheetHani Al-Nass100% (2)
- Answer: D Explanation: The Term "DDL" Stands For Data Definition Language, Used ToDocument17 pagesAnswer: D Explanation: The Term "DDL" Stands For Data Definition Language, Used ToPrathamesh AmateNo ratings yet
- Use Browser Find Functionality To Locate Specific SAP Icon Icon - Length Id Name QuickinfoDocument18 pagesUse Browser Find Functionality To Locate Specific SAP Icon Icon - Length Id Name QuickinfodonrexNo ratings yet
- Mori Seiki M720BM NL Auto Tune Procedure (Z A and B Phase)Document14 pagesMori Seiki M720BM NL Auto Tune Procedure (Z A and B Phase)Gordon CooperNo ratings yet
- Supplier/Vendor Ageing Analysis in SAP Query DesignerDocument31 pagesSupplier/Vendor Ageing Analysis in SAP Query Designerskskumar4848No ratings yet
- Sybase Administration Guid 1 PDFDocument432 pagesSybase Administration Guid 1 PDFakp_sapfiNo ratings yet
- Hugo Users GuideDocument21 pagesHugo Users GuideUsuario ParticularNo ratings yet
- SysAid Free Edition Installation GuideDocument75 pagesSysAid Free Edition Installation Guidebonilla.ernestoNo ratings yet
- Bill Notification SystemDocument17 pagesBill Notification SystemB. S BabuNo ratings yet
- Book C++ InternetDocument111 pagesBook C++ InternetRuben Kempter100% (1)
- Master Test Plan: Department of Veterans AffairsDocument26 pagesMaster Test Plan: Department of Veterans Affairssudhakar kakunuriNo ratings yet
- EECS 247 Analog-Digital Interface Integrated Circuits © 2008Document24 pagesEECS 247 Analog-Digital Interface Integrated Circuits © 2008Hassan FarssiNo ratings yet
- s71500 s71500t Motion Control Overview Function Manual en-US en-USDocument185 pagess71500 s71500t Motion Control Overview Function Manual en-US en-USnosenose99No ratings yet
- RDocument57 pagesRAlberto SalazarNo ratings yet