You might also like
- Blender 3D Noob To Pro-Beginner TutorialsDocument49 pagesBlender 3D Noob To Pro-Beginner Tutorialspaintedrealms100% (3)
- Installation Guide For Xampp and Wamp Server On WindowsDocument18 pagesInstallation Guide For Xampp and Wamp Server On Windowspankaj.sikar8643100% (1)
- Test Universe License Upgrade and Module Extension ENUDocument6 pagesTest Universe License Upgrade and Module Extension ENUzinab90100% (2)
- Grade 2 Worksheets FreeDocument3 pagesGrade 2 Worksheets FreePamNo ratings yet
- English 7 Diagnostic TestDocument7 pagesEnglish 7 Diagnostic TestJhay Mhar ANo ratings yet
- Anova and T TestDocument5 pagesAnova and T TestS A M E E U L L A H S O O M R ONo ratings yet
- QuestionnaireDocument5 pagesQuestionnairetamiNo ratings yet
- Huawei 434789548 Massive MIMO TDD ERAN15 1 Draft A PDFDocument215 pagesHuawei 434789548 Massive MIMO TDD ERAN15 1 Draft A PDFALEXANDRE JOSE FIGUEIREDO LOUREIRONo ratings yet
- International Payment Trends - Important To Follow in 2023Document9 pagesInternational Payment Trends - Important To Follow in 2023FahadNo ratings yet
- Standards and Classification Systems: 2009 Philippine Standard Industrial Classification (PSIC)Document2 pagesStandards and Classification Systems: 2009 Philippine Standard Industrial Classification (PSIC)AB AgostoNo ratings yet
- AZ-104 Exam - Free Actual Q&as, Page 1 - ExamTopicsDocument170 pagesAZ-104 Exam - Free Actual Q&as, Page 1 - ExamTopicsmnpawanNo ratings yet
- SOFAR Inverter Limiter Installation Guide and Reflux Power Setting PDFDocument4 pagesSOFAR Inverter Limiter Installation Guide and Reflux Power Setting PDFAlvin Cris Rongavilla100% (2)
- Personality TestDocument9 pagesPersonality Testshashankkapur22100% (2)
- Column 1Document9 pagesColumn 1FrederickML MobileNo ratings yet
- Exercise 1: Coding and Encoding/Descriptive Statistics (Data: Jenyan Survey & Santa Survey)Document3 pagesExercise 1: Coding and Encoding/Descriptive Statistics (Data: Jenyan Survey & Santa Survey)moreNo ratings yet
- Patient Satisfaction Chart Oct 2018: 60 Strongly Agree Agree Uncertain Disagree Strongly DisagreeDocument3 pagesPatient Satisfaction Chart Oct 2018: 60 Strongly Agree Agree Uncertain Disagree Strongly DisagreeSemeeeJuniorNo ratings yet
- ObarDocument9 pagesObarFrederickML MobileNo ratings yet
- Consolidated Results of 2 Periodical Test Philippine Politics and Government S.Y. 2019 - 2020 Mean Percentage Score FormDocument2 pagesConsolidated Results of 2 Periodical Test Philippine Politics and Government S.Y. 2019 - 2020 Mean Percentage Score FormFrancis MacatugobNo ratings yet
- DrioDocument9 pagesDrioFrederickML MobileNo ratings yet
- Exercise 1: Coding and Encoding/Descriptive Statistics (Data: Jenyan Survey & Santa Survey)Document3 pagesExercise 1: Coding and Encoding/Descriptive Statistics (Data: Jenyan Survey & Santa Survey)moreNo ratings yet
- Test 1Document187 pagesTest 1Julian MuñozNo ratings yet
- Lecture 16Document16 pagesLecture 16Mir Fida NadeemNo ratings yet
- Consolidated Results of 2 Periodical Test Philippine Politics and Government S.Y. 2019 - 2020 Mean Percentage Score FormDocument2 pagesConsolidated Results of 2 Periodical Test Philippine Politics and Government S.Y. 2019 - 2020 Mean Percentage Score FormFrancis MacatugobNo ratings yet
- Prcat 9Document2 pagesPrcat 9Shivani SinghNo ratings yet
- Personality Inventory ExerciseDocument6 pagesPersonality Inventory ExerciseVidhya SriNo ratings yet
- Uji RegresiDocument9 pagesUji RegresiIndra PrasastiNo ratings yet
- Reability Tes Pilot Testing g3 LatestDocument6 pagesReability Tes Pilot Testing g3 LatestDavid EnriquezNo ratings yet
- Educ 102 AssignmentDocument7 pagesEduc 102 AssignmentRoy CaburnayNo ratings yet
- Jawaban UTSDocument6 pagesJawaban UTSKarlina MulyawatiNo ratings yet
- Bab Iv Hasil Pengamatan Dan PembahasanDocument4 pagesBab Iv Hasil Pengamatan Dan PembahasanYumma Apuy C'drew BieberNo ratings yet
- UGM UI USM Undip IPB UB Unair UNYDocument11 pagesUGM UI USM Undip IPB UB Unair UNYriza kurniawanNo ratings yet
- Mps English 7 First Quarter NewDocument17 pagesMps English 7 First Quarter NewJhay Mhar ANo ratings yet
- Final Excel - Vanshit KothariDocument29 pagesFinal Excel - Vanshit KothariTUSHAR JAINNo ratings yet
- Bahasa Inggris Kelas 9 A SMT 120222023 Al Munir 20221118 20221125Document72 pagesBahasa Inggris Kelas 9 A SMT 120222023 Al Munir 20221118 20221125IntihakNo ratings yet
- Uttarakhand State Control Room COVID - 19Document4 pagesUttarakhand State Control Room COVID - 19Mohit ChauhanNo ratings yet
- Bye Elections To 18 Acs - List of Contesting CandidatesDocument1 pageBye Elections To 18 Acs - List of Contesting Candidateskarthickumar24No ratings yet
- BMI Autopsy: 1 1 3 1 1 1 1 2 1 3 1 1 1 2 2 1 2 3 3 2 4 1 2 1 1 2 1 2 1 1 1 Total Result 23 27 50Document4 pagesBMI Autopsy: 1 1 3 1 1 1 1 2 1 3 1 1 1 2 2 1 2 3 3 2 4 1 2 1 1 2 1 2 1 1 1 Total Result 23 27 50GAURAV RAJNo ratings yet
- No N Panelis 314 As Batch 055 072 As Blind Control 695 As Batch 057 1 10 13 2 2 11 11 5 3 7 5 8 4 4 3 11 5 1 1 7Document8 pagesNo N Panelis 314 As Batch 055 072 As Blind Control 695 As Batch 057 1 10 13 2 2 11 11 5 3 7 5 8 4 4 3 11 5 1 1 7Angga SukmaNo ratings yet
- Assignment Question #1 Naïve Method Three Period Moving Average Method Period Observation Period Observation Forecast Period ObservationDocument4 pagesAssignment Question #1 Naïve Method Three Period Moving Average Method Period Observation Period Observation Forecast Period ObservationBlanche Carey AbonNo ratings yet
- Etiología de Las MaloclusionesDocument280 pagesEtiología de Las MaloclusionesManuel Estuardo BravoNo ratings yet
- Aplicaciones en TicsDocument307 pagesAplicaciones en TicsCriss Eder SuluagaNo ratings yet
- Sri Chaitanya IIT Academy., India.: Key Sheet MathsDocument11 pagesSri Chaitanya IIT Academy., India.: Key Sheet Mathsmatrix dNo ratings yet
- AssignmentDocument33 pagesAssignmentRameshchandra SinghNo ratings yet
- Mid Term Exam-IMCDocument36 pagesMid Term Exam-IMCTUSHAR JAINNo ratings yet
- EDUC 202 PER Module SGSDocument5 pagesEDUC 202 PER Module SGSNathaniel DiazNo ratings yet
- Data Analysis From Questionaire Survey: This Workbook Is A Companion of Kardi Teknomo's TutorialDocument16 pagesData Analysis From Questionaire Survey: This Workbook Is A Companion of Kardi Teknomo's TutorialNaziarNo ratings yet
- A) Elev Slump Upp 1 Upp 2 Upp 3 Upp 4 Upp 5Document5 pagesA) Elev Slump Upp 1 Upp 2 Upp 3 Upp 4 Upp 5Linnea BjörckNo ratings yet
- Raw Data1Document28 pagesRaw Data1allen paulo repolloNo ratings yet
- Oup5.2019 - Data Processing and Analysis DataDocument24 pagesOup5.2019 - Data Processing and Analysis DataPeter GirasolNo ratings yet
- Data Sekolah Kab. Cilacap - DapodikdasmenDocument3 pagesData Sekolah Kab. Cilacap - DapodikdasmenBramantya Budi LaksanaNo ratings yet
- Castor Alviar National High School: Third Periodical Test January 10, 2019 Grade 10Document5 pagesCastor Alviar National High School: Third Periodical Test January 10, 2019 Grade 10Jhay Mhar ANo ratings yet
- Sample Inferential Statistics ExerciseDocument6 pagesSample Inferential Statistics ExerciseVeluz MarquezNo ratings yet
- FinalDocument56 pagesFinalsatrio bagusNo ratings yet
- Automated MPS 3RD Quarter Esp 7 10Document94 pagesAutomated MPS 3RD Quarter Esp 7 10Rodrigo Lazo Jr.No ratings yet
- Department of Education: Republic of The PhilippinesDocument2 pagesDepartment of Education: Republic of The PhilippinesGlenn Cacho GarceNo ratings yet
- Accomplishment Report For Phil IRI English 19 20Document19 pagesAccomplishment Report For Phil IRI English 19 20mary christine folleroNo ratings yet
- VLANDocument587 pagesVLANAhmad Fajri AshidiqiNo ratings yet
- MPL Template SY 2022 2023 Sections A Q Q4Document1 pageMPL Template SY 2022 2023 Sections A Q Q4Susan ValloyasNo ratings yet
- 03 08 20 SRN Com Jee Main WTM 32 Key & Sol'sDocument11 pages03 08 20 SRN Com Jee Main WTM 32 Key & Sol'sAditya Raj SinhaNo ratings yet
- Mean-Mps-Sd-Solver-Grade 10Document4 pagesMean-Mps-Sd-Solver-Grade 10mike22No ratings yet
- Activity 6 Personality Worksheet Part 1Document5 pagesActivity 6 Personality Worksheet Part 1Khylla ManlapazNo ratings yet
- Shift Wise PRESENT / ABSENT Report (Sugar)Document2 pagesShift Wise PRESENT / ABSENT Report (Sugar)Akash KumarNo ratings yet
- Chem ABC Daily Report 13.05.2021)Document2 pagesChem ABC Daily Report 13.05.2021)Akash KumarNo ratings yet
- Rancob Acara 4Document6 pagesRancob Acara 4Idayatul HanifaNo ratings yet
- Gen. Info. Educ. Background Employment DataDocument8 pagesGen. Info. Educ. Background Employment DataEdith MartinNo ratings yet
- TinkaDocument79 pagesTinkaLuis Angel Oblitas GonzalesNo ratings yet
- CAT 2023 SyllabusDocument3 pagesCAT 2023 Syllabuswnamanpc2No ratings yet
- Daily Bulletin of COVID 19 As On 3-06-2020 EveningDocument2 pagesDaily Bulletin of COVID 19 As On 3-06-2020 EveningJass PreetNo ratings yet
- English Trial Form NewDocument2 pagesEnglish Trial Form Newaries zoNo ratings yet
- 1 Introduction To The Personal Computer PDFDocument10 pages1 Introduction To The Personal Computer PDFSam LenciNo ratings yet
- Q2-TOS Grade 7Document4 pagesQ2-TOS Grade 7Shara Cañada CalvarioNo ratings yet
- Lesson 11 Definite IntegralsDocument17 pagesLesson 11 Definite Integralsava tyNo ratings yet
- The Dystonaut - Issue #5Document16 pagesThe Dystonaut - Issue #5maruka33No ratings yet
- Communication Media Channels (Wren and Shaine)Document24 pagesCommunication Media Channels (Wren and Shaine)LuzLlantinoTatoyNo ratings yet
- Keynote Patrick Link Design Thinking Summit 2017Document36 pagesKeynote Patrick Link Design Thinking Summit 2017Rafly AndrianzaNo ratings yet
- 56K PCI Soft Modem User Manual: Revision 1.0Document10 pages56K PCI Soft Modem User Manual: Revision 1.0kuda_jengkeNo ratings yet
- Andi Kuswantoro - Mid Project Chapter 1 To 3Document10 pagesAndi Kuswantoro - Mid Project Chapter 1 To 3ajdajbdahdNo ratings yet
- ANRITSU MG3692C DatasheetDocument17 pagesANRITSU MG3692C DatasheetSeymaNo ratings yet
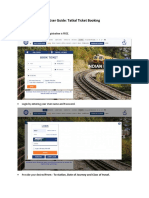
- User Guide: Tatkal Ticket Booking: - Register As An Individual. Registration Is FREEDocument7 pagesUser Guide: Tatkal Ticket Booking: - Register As An Individual. Registration Is FREEPratiksha JadhavNo ratings yet
- FSM-ES (001-924) Fire System Monitor + Engine ShutdownDocument7 pagesFSM-ES (001-924) Fire System Monitor + Engine ShutdownYoga putra riandiNo ratings yet
- A Thechnical Report-AydeeDocument29 pagesA Thechnical Report-AydeeJoanna AtiyotaNo ratings yet
- Osa 5422Document10 pagesOsa 5422Ken Ooi Kien LamNo ratings yet
- Insulation Resistance Testers PR-511: Model UT511Document1 pageInsulation Resistance Testers PR-511: Model UT511Jose Diaz HuamanNo ratings yet
- LD Lab ManualDocument92 pagesLD Lab ManualSunil BegumpurNo ratings yet
- Interim Australian/New Zealand Standard: Lightning ProtectionDocument9 pagesInterim Australian/New Zealand Standard: Lightning ProtectionkamaleshsNo ratings yet
- 100 Tareas Me Dejan en InglesDocument2 pages100 Tareas Me Dejan en InglesGian Carlos Silva DiazNo ratings yet
- Digital Logic Design Chapter 5Document23 pagesDigital Logic Design Chapter 5Gemechis GurmesaNo ratings yet
- Certificate of Eligibility CaliforniaDocument3 pagesCertificate of Eligibility CaliforniaJojo Aboyme CorcillesNo ratings yet
- Pset1 SolutionsDocument2 pagesPset1 SolutionsFernando BastosNo ratings yet