You might also like
- QB - Data ScienceDocument4 pagesQB - Data Sciencesvaishnavi112003No ratings yet
- CM6 - Mathematics As A Tool - Dispersion and CorrelationDocument18 pagesCM6 - Mathematics As A Tool - Dispersion and CorrelationLoeynahcNo ratings yet
- S1 Oct 22 QPDocument28 pagesS1 Oct 22 QPMunavi Bin Zaman MbzNo ratings yet
- PWCDocument24 pagesPWCratnadeppNo ratings yet
- MR Data Preparation and InvestigationDocument19 pagesMR Data Preparation and InvestigationRamesh GNo ratings yet
- Lect-1-Types and Summarizing Data - 2017Document51 pagesLect-1-Types and Summarizing Data - 2017Sara wannasNo ratings yet
- Statistics: Measures of Central TendencyDocument13 pagesStatistics: Measures of Central TendencyspencerNo ratings yet
- DSBDA Mock Insem Question BankDocument2 pagesDSBDA Mock Insem Question Bankrupaliwalunj_2135193No ratings yet
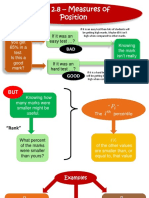
- Sec 2.8 - 2021Document20 pagesSec 2.8 - 2021sthembisoandile059No ratings yet
- Chap4 Normality (Data Analysis) FVDocument72 pagesChap4 Normality (Data Analysis) FVryad fki100% (1)
- Data Organization and Standardized TestingDocument7 pagesData Organization and Standardized TestingJohn LamNo ratings yet
- 2000 CartDocument50 pages2000 CartSwapan Kumar SahaNo ratings yet
- DM - Ch4 - Classification (Part1)Document20 pagesDM - Ch4 - Classification (Part1)C.RadhiyaDeviNo ratings yet
- DS - ESE - June 22Document2 pagesDS - ESE - June 22sakshi bhegadeNo ratings yet
- Multivariate Analysis TechniquesDocument55 pagesMultivariate Analysis TechniquesSi Hui ZhuoNo ratings yet
- 2210 WST01-01 IAL Statistics P1 October 2022 PDFDocument28 pages2210 WST01-01 IAL Statistics P1 October 2022 PDFApisit PoonpiriyaNo ratings yet
- Part 2 Descriptive StatisticsDocument47 pagesPart 2 Descriptive Statisticscarla guban-oñesNo ratings yet
- AIRs-LM - Math 10 QUARTER 4-Weeks 6-7 - Module 5Document20 pagesAIRs-LM - Math 10 QUARTER 4-Weeks 6-7 - Module 5joe mark d. manalang100% (4)
- Chap004BDocument61 pagesChap004Byadanar htaysanNo ratings yet
- STAT1122 QuestionsDocument17 pagesSTAT1122 Questionsmacayla0909No ratings yet
- Cae 2 Set 1 Original - KEYDocument5 pagesCae 2 Set 1 Original - KEYJANILA J.No ratings yet
- Measures of Dispersion Topic 11Document8 pagesMeasures of Dispersion Topic 11Syed Abdul Mussaver ShahNo ratings yet
- Data Analytics TheoryDocument54 pagesData Analytics TheoryChandra MohanNo ratings yet
- Prepare Data for AnalysisDocument17 pagesPrepare Data for AnalysisAtisha JunejaNo ratings yet
- SPSS Guide for Data AnalysisDocument71 pagesSPSS Guide for Data AnalysishudaNo ratings yet
- Nature of Statistics Part 2Document48 pagesNature of Statistics Part 2ROYYETTE F. FERNANDEZNo ratings yet
- Lecture 05 - Measures of Dispersion_56581bcb00cfd7a65d30a2cfbd09dadbDocument17 pagesLecture 05 - Measures of Dispersion_56581bcb00cfd7a65d30a2cfbd09dadbferassadadi10No ratings yet
- What is classification and predictionDocument21 pagesWhat is classification and predictionHit ManNo ratings yet
- PSY417 Week02Document38 pagesPSY417 Week02Ellisha McCNo ratings yet
- Stats101A - Chapter 1Document25 pagesStats101A - Chapter 1Zhen WangNo ratings yet
- Supervised Learning AlgorithmDocument59 pagesSupervised Learning Algorithmrenus25jNo ratings yet
- Chapter 2 - Data Analysis IDocument36 pagesChapter 2 - Data Analysis INazratul NajwaNo ratings yet
- Basic SPSS Guidance 1Document21 pagesBasic SPSS Guidance 1Lim KaishiNo ratings yet
- Measures of Variation v3Document43 pagesMeasures of Variation v3zahirah najihahNo ratings yet
- The Impact of a Values Intervention on Math Test Scores in College StudentsDocument25 pagesThe Impact of a Values Intervention on Math Test Scores in College StudentsJoyful SilhouetteNo ratings yet
- Module 5 - Range, Variance, Standard DeviationDocument31 pagesModule 5 - Range, Variance, Standard DeviationKenneth tejamNo ratings yet
- Learning Activity SheetDocument3 pagesLearning Activity SheetShuyen AmistadNo ratings yet
- Classification Ppts 2021Document80 pagesClassification Ppts 2021PRIYA RATHORENo ratings yet
- Week 5 Statistics Worksheet AnswersDocument6 pagesWeek 5 Statistics Worksheet AnswersJennifer MooreNo ratings yet
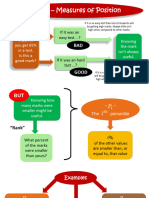
- Sec 2.8 - Measures of PositionDocument20 pagesSec 2.8 - Measures of PositionSiinozuko MasentseNo ratings yet
- Lecture - 8 - Statistics - Standard Deviation - Dr. (MRS) - Neelam YadavDocument31 pagesLecture - 8 - Statistics - Standard Deviation - Dr. (MRS) - Neelam YadavayushiNo ratings yet
- 5 StatistikDocument62 pages5 StatistikPhang Jiew LeongNo ratings yet
- STATISTICS and PROBABILITY - Final Exam CorrectedDocument3 pagesSTATISTICS and PROBABILITY - Final Exam CorrectedEsher JabesNo ratings yet
- Understanding and Presenting DataDocument26 pagesUnderstanding and Presenting DataZC47No ratings yet
- To The Learners:: NAME: - YR & SECDocument11 pagesTo The Learners:: NAME: - YR & SECG01-Azurin, Keisha Denise T.No ratings yet
- Brian Butterworth PDF CompressedDocument79 pagesBrian Butterworth PDF CompressedSoleil JimenezNo ratings yet
- Saint Ma 'S College September 4, 2021: 6 October 2021Document30 pagesSaint Ma 'S College September 4, 2021: 6 October 2021Chin TampipiNo ratings yet
- 3 Descriptive Statistics PDFDocument58 pages3 Descriptive Statistics PDFCharlyne Mari FloresNo ratings yet
- Slides Chp03 Stats 20221Document41 pagesSlides Chp03 Stats 20221nadiaNo ratings yet
- Mathematics As A Tool (Descriptive Statistics) (Midterm Period) Overview: This Module Tackles Mathematics As Applied To Different Areas Such As DataDocument33 pagesMathematics As A Tool (Descriptive Statistics) (Midterm Period) Overview: This Module Tackles Mathematics As Applied To Different Areas Such As Datacerell jun EscabasNo ratings yet
- DtreeDocument67 pagesDtreekaran sharmaNo ratings yet
- UntitledDocument43 pagesUntitledMuhammad AreebNo ratings yet
- Minitab HandbookDocument121 pagesMinitab HandbookSalvador Peña Ugalde100% (1)
- Data PreparationDocument12 pagesData PreparationKhari haranNo ratings yet
- unit 1Document72 pagesunit 1udaywal.nandiniNo ratings yet
- Item Analysis and Evaluation of Test ResultsDocument12 pagesItem Analysis and Evaluation of Test ResultsJessie BarreraNo ratings yet
- 3 - MeasureDocument39 pages3 - Measuredhruvil shahNo ratings yet
- Lecture 4 - Rise of Machine LearningDocument37 pagesLecture 4 - Rise of Machine LearningAbNo ratings yet
- Chap 1 - 2: Business StatisticsDocument38 pagesChap 1 - 2: Business StatisticsAdi Ruzaini Di EddyNo ratings yet
- Rapid Miner - Data PreparationDocument17 pagesRapid Miner - Data PreparationanithaaNo ratings yet
- Data Integrity and SecurityDocument4 pagesData Integrity and SecurityVarsha GhanashNo ratings yet
- MagicQ DMX and EthernetDocument5 pagesMagicQ DMX and EthernetChamSys|netNo ratings yet
- Rails Authentication from Scratch with Devise and Scaffolding PostsDocument25 pagesRails Authentication from Scratch with Devise and Scaffolding PostsMarkoKaponiNo ratings yet
- Program Design and ImplementationDocument24 pagesProgram Design and ImplementationmaryamNo ratings yet
- RAJ SoniDocument40 pagesRAJ SoniPATEL POOJANNo ratings yet
- OOP Theory With Real World Examples v2 UpdatedDocument21 pagesOOP Theory With Real World Examples v2 UpdatedFarhad ul HassanNo ratings yet
- Business Analysis Tools - Activity DiagramDocument148 pagesBusiness Analysis Tools - Activity DiagramArsène LupinNo ratings yet
- Crash 2023 05 18 08 23 11Document4 pagesCrash 2023 05 18 08 23 11Samsul ArifNo ratings yet
- DANEO 400: Hybrid Signal Analyzer For Power Utility Automation SystemsDocument16 pagesDANEO 400: Hybrid Signal Analyzer For Power Utility Automation SystemsAndrew SetiawanNo ratings yet
- Compiler Unit 1Document110 pagesCompiler Unit 1Aditya RajNo ratings yet
- SimulationDocument66 pagesSimulationMECH DR.VENKAT PRASATNo ratings yet
- Ujian Golang IntermediateDocument20 pagesUjian Golang IntermediateDeris PutraNo ratings yet
- Lesson 1 INTRODUCTION TO CSSDocument45 pagesLesson 1 INTRODUCTION TO CSSChristopher OlayaNo ratings yet
- Marvelmind Indoor Positioning Technologies ReviewDocument34 pagesMarvelmind Indoor Positioning Technologies ReviewRumah WayangNo ratings yet
- PowerPoint Slides To Chapter 04Document9 pagesPowerPoint Slides To Chapter 04Shreya DwivediNo ratings yet
- ABAP Program Tips by MundosapDocument168 pagesABAP Program Tips by MundosapOscar FrancoNo ratings yet
- (June-2022) New PassLeader DP-900 Exam DumpsDocument4 pages(June-2022) New PassLeader DP-900 Exam Dumpsestudio estudioNo ratings yet
- PassLeader 300-375 Exam Dumps (1-10)Document7 pagesPassLeader 300-375 Exam Dumps (1-10)Janek PodwalaNo ratings yet
- CT and Mri of The Whole Body Haaga PDFDocument5 pagesCT and Mri of The Whole Body Haaga PDFSahityaNo ratings yet
- Global Micro-Tech Release: Bulk Weighing & Monitoring SolutionsDocument24 pagesGlobal Micro-Tech Release: Bulk Weighing & Monitoring SolutionsCapacitacion TodocatNo ratings yet
- Activity 3.3 Thesis, Topic Sentence and Supporting Details-1Document3 pagesActivity 3.3 Thesis, Topic Sentence and Supporting Details-1Blanche Faith C. MARGATENo ratings yet
- Books SearchDocument12 pagesBooks Searchhiddenhidden16No ratings yet
- CCNA 200-125题库V3.0Document150 pagesCCNA 200-125题库V3.0Gabriela PopescuNo ratings yet
- Comparative Study On Spoken Language Identification Based On Deep LearningDocument5 pagesComparative Study On Spoken Language Identification Based On Deep LearningMaged HamoudaNo ratings yet
- Datasheet of DS 2DF8442IXS AELWYT5 - V5.7.1 - 20220121Document7 pagesDatasheet of DS 2DF8442IXS AELWYT5 - V5.7.1 - 20220121Andres VarelaNo ratings yet
- Prime Network OSS Integration Guide-2-0 PDFDocument148 pagesPrime Network OSS Integration Guide-2-0 PDFmalli gaduNo ratings yet
- Arabsat Frequency List PDF: Downloadarabsat Frequency List Pdf. Free PDF Download Zeal - Increased Damage Above Level 4Document5 pagesArabsat Frequency List PDF: Downloadarabsat Frequency List Pdf. Free PDF Download Zeal - Increased Damage Above Level 4jody9090No ratings yet
- SvendborgDocument287 pagesSvendborgPalyyNo ratings yet
- HB Ac2 Profibus enDocument124 pagesHB Ac2 Profibus enJan KowalskiNo ratings yet