You might also like
- Rahul Raj - Java Deep Learning Cookbook - Train Neural Networks For Classification, NLP, and Reinforcement Learning Using Deeplearning4j.-Packt (2020)Document294 pagesRahul Raj - Java Deep Learning Cookbook - Train Neural Networks For Classification, NLP, and Reinforcement Learning Using Deeplearning4j.-Packt (2020)LUIS MARTINEZNo ratings yet
- Top 100+ Data Engineer Interview Questions and Answers For 2022Document4 pagesTop 100+ Data Engineer Interview Questions and Answers For 2022Mariam Mamdouh Mohamed Mohamed GhoniemNo ratings yet
- A Survey On Knowledge Graphs Representation Acquisition and ApplicationsDocument21 pagesA Survey On Knowledge Graphs Representation Acquisition and ApplicationsxNo ratings yet
- Principles of Hash-Based Text Retrieval.Document8 pagesPrinciples of Hash-Based Text Retrieval.matthewriley123100% (1)
- Adversarial Examples - Attacks and Defenses For Deep LearningDocument20 pagesAdversarial Examples - Attacks and Defenses For Deep Learningoscar ColombiaNo ratings yet
- NN, Hypersurface, RTADocument8 pagesNN, Hypersurface, RTASpectroManNo ratings yet
- Recurrent Neural Networks (RNNS) : A Gentle Introduction and OverviewDocument16 pagesRecurrent Neural Networks (RNNS) : A Gentle Introduction and OverviewRkeA RkeRNo ratings yet
- Implementing Document Ranking Within A Logical FrameworkDocument11 pagesImplementing Document Ranking Within A Logical FrameworkDevi Dian Pramana PutraNo ratings yet
- 1 s2.0 S0959440X2300012X MainDocument6 pages1 s2.0 S0959440X2300012X MainErsela ZainNo ratings yet
- Accepted ManuscriptDocument13 pagesAccepted Manuscript25025073No ratings yet
- New Ranking Algorithms For Parsing and Tagging: Kernels Over Discrete Structures, and The Voted PerceptronDocument8 pagesNew Ranking Algorithms For Parsing and Tagging: Kernels Over Discrete Structures, and The Voted PerceptronMeher VijayNo ratings yet
- On An Improvement of Graph Convolutional Network in Semi-Supervised LearningDocument4 pagesOn An Improvement of Graph Convolutional Network in Semi-Supervised LearningThien ThaiNo ratings yet
- L D S M: Earning EEP Tructured OdelsDocument11 pagesL D S M: Earning EEP Tructured OdelspogNo ratings yet
- Generalized Association Rule Mining Algorithms Based On Data CubeDocument6 pagesGeneralized Association Rule Mining Algorithms Based On Data Cubeapi-3814854No ratings yet
- 1 s2.0 S2666657X23000307 MainDocument13 pages1 s2.0 S2666657X23000307 Mainsonimohit895No ratings yet
- Deepfool: A Simple and Accurate Method To Fool Deep Neural NetworksDocument9 pagesDeepfool: A Simple and Accurate Method To Fool Deep Neural NetworksRanajoy SadhukhanNo ratings yet
- Research PapersDocument18 pagesResearch PapersMuhammad ShahidNo ratings yet
- Techniques For Measuring The Inferential Strength of Forgetting PoliciesDocument13 pagesTechniques For Measuring The Inferential Strength of Forgetting Policiesadelk138019No ratings yet
- Manifold NetDocument14 pagesManifold NetFriji RachaNo ratings yet
- Darling LdaDocument10 pagesDarling Ldaguru dineshNo ratings yet
- Glow: Generative Flow With Invertible 1×1 Convolutions: Equal ContributionDocument15 pagesGlow: Generative Flow With Invertible 1×1 Convolutions: Equal ContributionNguyễn ViệtNo ratings yet
- When Are Overcomplete Topic Models Identifiable? Uniqueness of Tensor Tucker Decompositions With Structured SparsityDocument52 pagesWhen Are Overcomplete Topic Models Identifiable? Uniqueness of Tensor Tucker Decompositions With Structured SparsitySrinath KadapannagariNo ratings yet
- A Chatterjee, An Introduction To The Proper Orthogonal DecompositionDocument11 pagesA Chatterjee, An Introduction To The Proper Orthogonal DecompositionPiyush HotaNo ratings yet
- Digital Signal Processing: Grégoire Montavon, Wojciech Samek, Klaus-Robert MüllerDocument15 pagesDigital Signal Processing: Grégoire Montavon, Wojciech Samek, Klaus-Robert MüllerAnonymous HUY0yRexYfNo ratings yet
- Roa FiltrDocument5 pagesRoa Filtrali engNo ratings yet
- Prediction of Building Lighting Energy Consumption Based On Support Vector RegressionDocument5 pagesPrediction of Building Lighting Energy Consumption Based On Support Vector RegressionMajjonesNo ratings yet
- Deep Reinforcement Learning in Computer Vision: A Comprehensive SurveyDocument103 pagesDeep Reinforcement Learning in Computer Vision: A Comprehensive SurveyAlex MercerNo ratings yet
- Discovering Patterns With Weak-Wildcard GapsDocument11 pagesDiscovering Patterns With Weak-Wildcard GapsgowripNo ratings yet
- RenyidpDocument13 pagesRenyidpwilliam waltersNo ratings yet
- Q1 Fisher Kernels On Visual Vocabularies For Image CategorizationDocument8 pagesQ1 Fisher Kernels On Visual Vocabularies For Image Categorization弘元No ratings yet
- Sum-Product Networks: A New Deep Architecture: Hoifung Poon and Pedro DomingosDocument10 pagesSum-Product Networks: A New Deep Architecture: Hoifung Poon and Pedro DomingosAswaNo ratings yet
- Fully Homomorphic Encryptionand BootstrappingDocument12 pagesFully Homomorphic Encryptionand BootstrappingModjtaba GharibyarNo ratings yet
- 2DI F D A D S E S: Mage Eatures Etector ND Escriptor Election Xpert YstemDocument11 pages2DI F D A D S E S: Mage Eatures Etector ND Escriptor Election Xpert YstemIbon MerinoNo ratings yet
- CIM Ensemble Classification Regression SurveyDocument15 pagesCIM Ensemble Classification Regression SurveyjebaevaNo ratings yet
- (2006) Barrier Options and Their Static Hedges Simple Derivations and ExtensionsDocument10 pages(2006) Barrier Options and Their Static Hedges Simple Derivations and ExtensionsAble ZhangNo ratings yet
- W T K ::: N I N I D W::: W::: W KDocument4 pagesW T K ::: N I N I D W::: W::: W KjimakosjpNo ratings yet
- Document Classification Utilising Ontologies and Relations Between DocumentsDocument8 pagesDocument Classification Utilising Ontologies and Relations Between DocumentsUno de MadridNo ratings yet
- Bare Conf4Document5 pagesBare Conf4asd asdasNo ratings yet
- Provable Benefits of Representation Learning: Sanjeev Arora Andrej Risteski June 15, 2017Document22 pagesProvable Benefits of Representation Learning: Sanjeev Arora Andrej Risteski June 15, 2017Ramchandran MuthukumarNo ratings yet
- Topic EsttimationDocument73 pagesTopic Esttimationmohitgond170No ratings yet
- Classification of Malware by Using Structural Entropy On Convolutional Neural NetworksDocument6 pagesClassification of Malware by Using Structural Entropy On Convolutional Neural NetworksAmts TamerNo ratings yet
- High Range Resolution Profile Automatic Target Recognition Using Sparse RepresentationDocument7 pagesHigh Range Resolution Profile Automatic Target Recognition Using Sparse RepresentationSunny GNo ratings yet
- Atomic WedgieDocument8 pagesAtomic WedgieElfawizzyNo ratings yet
- 1074553xdDocument15 pages1074553xdgg2697528No ratings yet
- Velten Research PaperDocument6 pagesVelten Research PaperkoshlendraNo ratings yet
- Analysis Methods ReflectometryDocument8 pagesAnalysis Methods ReflectometrymilitiamonNo ratings yet
- Chapter 2 Modeling: Modern Information Retrieval by R. Baeza-Yates and B. RibeirDocument47 pagesChapter 2 Modeling: Modern Information Retrieval by R. Baeza-Yates and B. RibeirIrvan MaizharNo ratings yet
- Prime Classes BrochureDocument14 pagesPrime Classes BrochurearavindNo ratings yet
- Abstractive Sentence Summarization With Attentive Recurrent Neural NetworksDocument6 pagesAbstractive Sentence Summarization With Attentive Recurrent Neural NetworksSaipul BahriNo ratings yet
- Session 01 - Paper 08Document8 pagesSession 01 - Paper 08Nicholas DawsonNo ratings yet
- A Geometrical Viewpoint On The Benign Overfitting Property of The Minimum - Norm Interpolant EstimatorDocument32 pagesA Geometrical Viewpoint On The Benign Overfitting Property of The Minimum - Norm Interpolant EstimatorMarcelo Marcy Majstruk CimilloNo ratings yet
- CAIM: Cerca I Anàlisi D'informació Massiva: FIB, Grau en Enginyeria InformàticaDocument21 pagesCAIM: Cerca I Anàlisi D'informació Massiva: FIB, Grau en Enginyeria InformàticaBlackMoothNo ratings yet
- BaratAL PatternRecognition2010 VirtualDoubleSidedImageProbingDocument15 pagesBaratAL PatternRecognition2010 VirtualDoubleSidedImageProbingThiago StatellaNo ratings yet
- MKLforDR Lin2011 PDFDocument14 pagesMKLforDR Lin2011 PDFMihai FieraruNo ratings yet
- On Parametric Picture Fuzzy Information Measure in Pattern Recognition ProblemDocument6 pagesOn Parametric Picture Fuzzy Information Measure in Pattern Recognition ProblemNistha SNo ratings yet
- Approximations To The Fisher Information Metric of Deep Generative Models For Out-Of-Distribution DetectionDocument32 pagesApproximations To The Fisher Information Metric of Deep Generative Models For Out-Of-Distribution Detectiondonny7543No ratings yet
- Emerging Patterns and ClassificationDocument19 pagesEmerging Patterns and ClassificationEmmanuel DoronNo ratings yet
- Open Domain QADocument28 pagesOpen Domain QAATHARVA INAMDARNo ratings yet
- 5 - Chen & Fu, 2018Document4 pages5 - Chen & Fu, 2018Abu MansyurNo ratings yet
- Termite: Visualization Techniques For Assessing Textual Topic ModelsDocument4 pagesTermite: Visualization Techniques For Assessing Textual Topic Modelspol_boraNo ratings yet
- Improving Document Ranking With Dual Word EmbeddingsDocument2 pagesImproving Document Ranking With Dual Word EmbeddingsgashawNo ratings yet
- 111111Document20 pages111111gashawNo ratings yet
- Sec ElementDocument3 pagesSec ElementgashawNo ratings yet
- Information SecurityDocument33 pagesInformation SecuritygashawNo ratings yet
- Infosecch 2Document34 pagesInfosecch 2gashawNo ratings yet
- Machine Learning Spark MLDocument11 pagesMachine Learning Spark MLsyarian sakirNo ratings yet
- AI Final Exam For 6kilo.Document4 pagesAI Final Exam For 6kilo.Beki TubeNo ratings yet
- Japanese Text ClassificationDocument6 pagesJapanese Text ClassificationWingnin ChoiNo ratings yet
- Report Kernel Pca MethodDocument11 pagesReport Kernel Pca MethodMUHAMMAD NUR FITRI BIN NORAFFENDINo ratings yet
- Mobile Application Development UnitDocument24 pagesMobile Application Development Unitjango navi100% (1)
- A Review of Supervised Object-Based Land-Cover Image ClassificationDocument17 pagesA Review of Supervised Object-Based Land-Cover Image ClassificationThanh Nguyen LongNo ratings yet
- DBMS Interview Questions and Answers: Sindhuja HariDocument71 pagesDBMS Interview Questions and Answers: Sindhuja HariDeepak SinghNo ratings yet
- Elearning Project File (Final)Document68 pagesElearning Project File (Final)Manwinder Singh GillNo ratings yet
- Olawumi, Chan - 2018 - A Scientometric Review of Global Research On Sustainability and Sustainable DevelopmentDocument20 pagesOlawumi, Chan - 2018 - A Scientometric Review of Global Research On Sustainability and Sustainable Developmentjean marcellNo ratings yet
- Er Diagram Assignment (DBMS)Document18 pagesEr Diagram Assignment (DBMS)asifNo ratings yet
- Group Assignment 2 - Group A5Document4 pagesGroup Assignment 2 - Group A5Limen ChuaNo ratings yet
- Cs3027 Deep Learning SyllabusDocument2 pagesCs3027 Deep Learning Syllabusvasu devNo ratings yet
- Fyit DBMS Unit 1-1Document9 pagesFyit DBMS Unit 1-1Shaikh WasimaNo ratings yet
- Prashant Kapgate Seminar ChatGPTDocument21 pagesPrashant Kapgate Seminar ChatGPTHarish AugadNo ratings yet
- Unit V - Web and Text MiningDocument35 pagesUnit V - Web and Text Miningswetha sastryNo ratings yet
- Decision Support and Data Warehouse SystemsDocument9 pagesDecision Support and Data Warehouse SystemsroopachandrikaNo ratings yet
- Sentiment Analysis in Arabic Language Using Machine Learning Iraqi Dialect Case StudyDocument15 pagesSentiment Analysis in Arabic Language Using Machine Learning Iraqi Dialect Case StudyHussein NassrullahNo ratings yet
- Text-Mined Dataset of Inorganic Materials Synthesis Recipes: Data DescriptorDocument11 pagesText-Mined Dataset of Inorganic Materials Synthesis Recipes: Data Descriptornguyen van anNo ratings yet
- Cognitive MapDocument9 pagesCognitive Mapbenjamin212No ratings yet
- Hive Quiz and QuestionsDocument6 pagesHive Quiz and QuestionsRushi KhandareNo ratings yet
- Events InformationDocument3 pagesEvents InformationMatheo BienaimeNo ratings yet
- Text To Video - ModelDocument2 pagesText To Video - Modelava939No ratings yet
- LCD TestDocument3 pagesLCD Testsilent knight100% (1)
- Qualitative Coding Summary From Jason Hopkins' PresentationDocument2 pagesQualitative Coding Summary From Jason Hopkins' PresentationBlessing NyazikaNo ratings yet
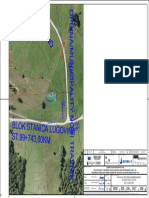
- 6050 000 DW 1421 008 R0 Situacije Pristupnih Puteva Objektima-8 BS LugovinaDocument1 page6050 000 DW 1421 008 R0 Situacije Pristupnih Puteva Objektima-8 BS LugovinaRiad ĆišićNo ratings yet
- VTEAM A General Model For Voltage-Controlled MemristorsDocument23 pagesVTEAM A General Model For Voltage-Controlled MemristorsAmmuNo ratings yet
- The Extent To Which The Creation Sharing and Utilization of Knowledge Are Central To Resource Based View of Competitive Advantage A Critical EvaluationDocument13 pagesThe Extent To Which The Creation Sharing and Utilization of Knowledge Are Central To Resource Based View of Competitive Advantage A Critical EvaluationObinwanne OdimgbeNo ratings yet
- Publications v6Document11 pagesPublications v6basuiasNo ratings yet