You might also like
- Windows Azure Virtual Lab WalkthroughDocument51 pagesWindows Azure Virtual Lab Walkthroughsyedmsalman1844No ratings yet
- Hive TutorialDocument25 pagesHive TutorialSankalp JangamNo ratings yet
- CFF Explorer Scripting LanguageDocument43 pagesCFF Explorer Scripting Languagenight_shade88No ratings yet
- Installing and Working With CentOS 7 x64 and KVMDocument7 pagesInstalling and Working With CentOS 7 x64 and KVMdanxl007No ratings yet
- Hive Is A Data Warehouse Infrastructure Tool To Process Structured Data in HadoopDocument30 pagesHive Is A Data Warehouse Infrastructure Tool To Process Structured Data in HadooparavindNo ratings yet
- Unit-Vi Hive Hadoop & Big DataDocument24 pagesUnit-Vi Hive Hadoop & Big DataAbhay Dabhade100% (1)
- Nptel Big Data Full Assignment Solution 2021Document36 pagesNptel Big Data Full Assignment Solution 2021Sayantan Roy100% (6)
- BigData ObjectiveDocument93 pagesBigData ObjectivesaitejNo ratings yet
- QCM Bigdata 1 ExampdfDocument7 pagesQCM Bigdata 1 Exampdfyounes khounaNo ratings yet
- Hive InterviewDocument17 pagesHive Interviewmihirhota75% (4)
- Apache Hive Cookbook - Sample ChapterDocument27 pagesApache Hive Cookbook - Sample ChapterPackt Publishing100% (1)
- Apache Hive Interview Questions: 1. Define The Difference Between Hive and Hbase?Document10 pagesApache Hive Interview Questions: 1. Define The Difference Between Hive and Hbase?shubham rathodNo ratings yet
- Chapter+9+ HIVEDocument50 pagesChapter+9+ HIVEHARISH SUBRAMANIANNo ratings yet
- 98 364 Test Bank Lesson01Document6 pages98 364 Test Bank Lesson01perrero20100% (2)
- Aws Data Analytics FundamentalsDocument15 pagesAws Data Analytics Fundamentals4139 NIVEDHA S100% (1)
- Hadoop 1000 MCQ QuestionDocument96 pagesHadoop 1000 MCQ Questionyashswami284No ratings yet
- Hive Interview QuestionsDocument5 pagesHive Interview QuestionsGuruprasad VijayakumarNo ratings yet
- Unit-4 Pig HiveDocument40 pagesUnit-4 Pig HiveSivaNo ratings yet
- SolutionsDocument3 pagesSolutionsDeepak PardhiNo ratings yet
- New - HiveDocument46 pagesNew - HiveBharathi Krishna LNo ratings yet
- PDFDocument23 pagesPDFHAMDI GDHAMINo ratings yet
- Big Data Analytics: WelcomeDocument69 pagesBig Data Analytics: WelcomeSaiyed Faiayaz WarisNo ratings yet
- HiveDocument5 pagesHiveMayank RaiNo ratings yet
- Introduction To HIVEDocument8 pagesIntroduction To HIVEKajalNo ratings yet
- Deepshikha Agrawal Pushp B.Sc. (IT), MBA (IT) Certification-Hadoop, Spark, Scala, Python, Tableau, ML (Assistant Professor JLBS)Document47 pagesDeepshikha Agrawal Pushp B.Sc. (IT), MBA (IT) Certification-Hadoop, Spark, Scala, Python, Tableau, ML (Assistant Professor JLBS)Ashita PunjabiNo ratings yet
- Course3 Module2 Intro To Hive SlidesDocument76 pagesCourse3 Module2 Intro To Hive SlidesAnonymous U5zM45uBdNo ratings yet
- Experiment No 2Document9 pagesExperiment No 2Aman JainNo ratings yet
- Hive-NASA Case StudyDocument9 pagesHive-NASA Case Studycopy leaks100% (1)
- Hive ObjectiveDocument2 pagesHive ObjectiveraviNo ratings yet
- HiveDocument13 pagesHivethunuguri santoshNo ratings yet
- Hive2 PDFDocument8 pagesHive2 PDFRavi MistryNo ratings yet
- Question Bank: Descriptive QuestionsDocument5 pagesQuestion Bank: Descriptive QuestionsVrushali Vilas BorleNo ratings yet
- BDA Assignment I and IIDocument8 pagesBDA Assignment I and IIAshok Mane ManeNo ratings yet
- Hadoop Questions and Answers Part 100Document34 pagesHadoop Questions and Answers Part 100yashswami284No ratings yet
- Hive Crash Course: A Beginner's GuideDocument19 pagesHive Crash Course: A Beginner's GuidesunitaNo ratings yet
- FinalDocument276 pagesFinalYàssine HàdryNo ratings yet
- Hive - A Warehousing Solution Over A Map-Reduce FrameworkDocument4 pagesHive - A Warehousing Solution Over A Map-Reduce FrameworkSatyanarayan PatelNo ratings yet
- SQL and Nosql Programming With SparkDocument63 pagesSQL and Nosql Programming With SparkHuy NguyễnNo ratings yet
- Cloudera CCD 410Document21 pagesCloudera CCD 410chandukaturi100% (1)
- Top SQL MCQDocument85 pagesTop SQL MCQScientific WayNo ratings yet
- IBM Big Data Engineer: IBM C2090-101 Version DemoDocument6 pagesIBM Big Data Engineer: IBM C2090-101 Version DemoRia KhareNo ratings yet
- SME PrepDocument5 pagesSME PrepGuruprasad VijayakumarNo ratings yet
- HiveDocument65 pagesHiveApurvaNo ratings yet
- Bda Exp-6Document10 pagesBda Exp-6Mohit GangwaniNo ratings yet
- Bda Unit 5 NotesDocument23 pagesBda Unit 5 NotesAishwarya RayasamNo ratings yet
- Hiveinterviewquestions 150326053618 Conversion Gate01 PDFDocument4 pagesHiveinterviewquestions 150326053618 Conversion Gate01 PDFgegopiNo ratings yet
- Hadoop MCQ ChallengeDocument63 pagesHadoop MCQ Challengeyashswami284No ratings yet
- 4 Lesson Plan For AAVQDocument4 pages4 Lesson Plan For AAVQwill herondaleNo ratings yet
- Hadoop HiveDocument61 pagesHadoop HivemustaqNo ratings yet
- CDC With HDFS ApplyDocument10 pagesCDC With HDFS ApplyparasharaNo ratings yet
- Aindumps.c2090 101.v2021!05!19.by - Blade.64qDocument28 pagesAindumps.c2090 101.v2021!05!19.by - Blade.64qaissam berrahouNo ratings yet
- IBM DataStage V11.5.x Database Transaction ProcessingDocument27 pagesIBM DataStage V11.5.x Database Transaction ProcessingAntonio BlancoNo ratings yet
- Big Data AnalyticsDocument6 pagesBig Data AnalyticsGauri BawaNo ratings yet
- 2 Answer For YLCDDocument2 pages2 Answer For YLCDWDanielAnzulesBscNo ratings yet
- External Lab and Skill 17-05-2022Document10 pagesExternal Lab and Skill 17-05-2022Vignesh ChallaNo ratings yet
- BDT QuizDocument4 pagesBDT QuizVani HiremaniNo ratings yet
- DatabricksmcqsquestionsandanswersDocument5 pagesDatabricksmcqsquestionsandanswersSonali ManjunathNo ratings yet
- Big Data Analytics - AssignmenDocument1 pageBig Data Analytics - AssignmenGoku pubgMNo ratings yet
- Hive Full LectureDocument17 pagesHive Full LectureAtharv ChaudhariNo ratings yet
- HIVEDocument56 pagesHIVEjagadeeswara71No ratings yet
- HiveDocument45 pagesHivebabel 8No ratings yet
- Spark Interview Q&ADocument31 pagesSpark Interview Q&ARushi KhandareNo ratings yet
- NOSQL Interview Q&ADocument25 pagesNOSQL Interview Q&ARushi KhandareNo ratings yet
- Day71 - Day75 Tableau InterviewDocument26 pagesDay71 - Day75 Tableau InterviewRushi KhandareNo ratings yet
- Day65 - Day70 Power BI InterviewDocument31 pagesDay65 - Day70 Power BI InterviewRushi KhandareNo ratings yet
- Day1-Day75 Data Analytics InterviewDocument669 pagesDay1-Day75 Data Analytics InterviewRushi KhandareNo ratings yet
- ML Inter Q&ADocument54 pagesML Inter Q&ARushi KhandareNo ratings yet
- Stock Maintenance SystemDocument67 pagesStock Maintenance Systemanandv8687% (23)
- 90%-UGRD-IT6203 Database Management System 2 (Oracle 10g Admin 2)Document16 pages90%-UGRD-IT6203 Database Management System 2 (Oracle 10g Admin 2)michael sevillaNo ratings yet
- Manifest Generator: User InstructionsDocument6 pagesManifest Generator: User Instructionsjohan carranza alvarezNo ratings yet
- Instructions To View .MOBI File Using Kindle AppDocument1 pageInstructions To View .MOBI File Using Kindle AppRishabh JoshiNo ratings yet
- Kofax Analytics For Controlsuite: Installation GuideDocument51 pagesKofax Analytics For Controlsuite: Installation GuideHever MondragonNo ratings yet
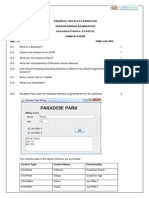
- CBSE Class 11 Informatics Practices Sample Paper-01 (Solved)Document10 pagesCBSE Class 11 Informatics Practices Sample Paper-01 (Solved)cbsesamplepaper83% (24)
- SQL - Understanding Oracle Apex - Application.g - FNN and How To Use It - Stack OverflowDocument4 pagesSQL - Understanding Oracle Apex - Application.g - FNN and How To Use It - Stack OverflowkhalidsnNo ratings yet
- Electricity Bill Payment PDF FreeDocument16 pagesElectricity Bill Payment PDF Freekrishna mouliNo ratings yet
- AlienVault Asset Management Reference GuideDocument58 pagesAlienVault Asset Management Reference GuidegreyoneNo ratings yet
- Lot Size ProcedureDocument10 pagesLot Size ProceduremsankaranNo ratings yet
- Gallery App in Go and Fyne: in This Article, We'll Learn How To Make An Image ViewerDocument9 pagesGallery App in Go and Fyne: in This Article, We'll Learn How To Make An Image Viewermamta yadavNo ratings yet
- CSA 7 QuestionsDocument4 pagesCSA 7 Questionsvk.maddali6256No ratings yet
- Archexteriors Vol 27Document21 pagesArchexteriors Vol 27SchreiberNo ratings yet
- IWS v7.1+SP3 Technical Reference (A4)Document932 pagesIWS v7.1+SP3 Technical Reference (A4)ricardosoarescostaNo ratings yet
- FS100 ControllerDocument2 pagesFS100 ControllermartinimartiiniNo ratings yet
- Excel and Powerpoint QuestionsDocument8 pagesExcel and Powerpoint Questionsvk singhNo ratings yet
- Dmde-3 6 0-ManualDocument63 pagesDmde-3 6 0-ManualaudiolimitNo ratings yet
- Cisco ASDM Release Notes Version 5.0 (5) : April 2006Document20 pagesCisco ASDM Release Notes Version 5.0 (5) : April 2006Ryan BelicovNo ratings yet
- B.Tech - Cyber Security PDFDocument119 pagesB.Tech - Cyber Security PDFRAJNATH YADAVNo ratings yet
- Teamviewer9 Manual Managementconsole en PDFDocument45 pagesTeamviewer9 Manual Managementconsole en PDFRossy Dinda PratiwiNo ratings yet
- Eleduino 7 Inch IPS (1024-600) Captive Touchscreen For Raspberry User Guide EN1.2Document11 pagesEleduino 7 Inch IPS (1024-600) Captive Touchscreen For Raspberry User Guide EN1.2Emeka EruokwuNo ratings yet
- 2 VDR & SVDRDocument21 pages2 VDR & SVDRtaufikNo ratings yet
- Correcting The - Ve Valuated Stock by Cancelling Material DocumentDocument7 pagesCorrecting The - Ve Valuated Stock by Cancelling Material Documentamol_di1743No ratings yet
- Mobile ACS Manual Edit (English) .OdtDocument2 pagesMobile ACS Manual Edit (English) .Odtkenyu10No ratings yet
- FS20 Fire Detection System: ConfigurationDocument406 pagesFS20 Fire Detection System: ConfigurationehsanrastayeshNo ratings yet
- ATV TUNER FM2 Guia InstalacionDocument10 pagesATV TUNER FM2 Guia InstalacionGabriel Espinoza0% (1)